 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Modular addition without black-boxes: Compressing explanations of MLPs that compute numerical integration
Dec 04, 2024



The goal of mechanistic interpretability is discovering simpler, low-rank algorithms implemented by models. While we can compress activations into features, compressing nonlinear feature-maps -- like MLP layers -- is an open problem. In this work, we present the first case study in rigorously compressing nonlinear feature-maps, which are the leading asymptotic bottleneck to compressing small transformer models. We work in the classic setting of the modular addition models, and target a non-vacuous bound on the behaviour of the ReLU MLP in time linear in the parameter-count of the circuit. To study the ReLU MLP analytically, we use the infinite-width lens, which turns post-activation matrix multiplications into approximate integrals. We discover a novel interpretation of} the MLP layer in one-layer transformers implementing the ``pizza'' algorithm: the MLP can be understood as evaluating a quadrature scheme, where each neuron computes the area of a rectangle under the curve of a trigonometric integral identity. Our code is available at https://tinyurl.com/mod-add-integration.
Unifying and Verifying Mechanistic Interpretations: A Case Study with Group Operations
Oct 09, 2024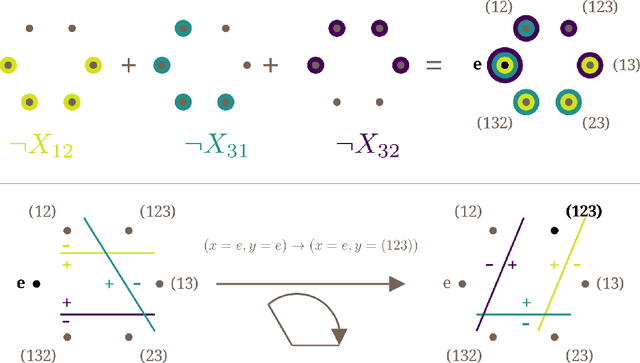
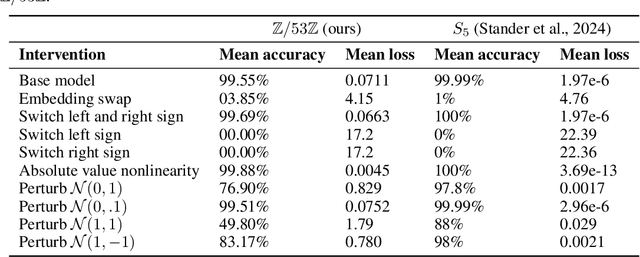
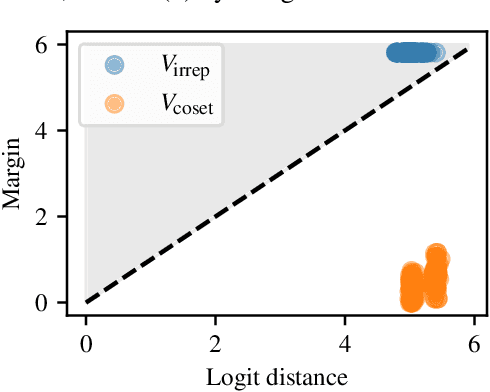

A recent line of work in mechanistic interpretability has focused on reverse-engineering the computation performed by neural networks trained on the binary operation of finite groups. We investigate the internals of one-hidden-layer neural networks trained on this task, revealing previously unidentified structure and producing a more complete description of such models that unifies the explanations of previous works. Notably, these models approximate equivariance in each input argument. We verify that our explanation applies to a large fraction of networks trained on this task by translating it into a compact proof of model performance, a quantitative evaluation of model understanding. In particular, our explanation yields a guarantee of model accuracy that runs in 30% the time of brute force and gives a >=95% accuracy bound for 45% of the models we trained. We were unable to obtain nontrivial non-vacuous accuracy bounds using only explanations from previous works.
Compact Proofs of Model Performance via Mechanistic Interpretability
Jun 24, 2024



In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jun 18, 2024In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Design of Stickbug: a Six-Armed Precision Pollination Robot
Apr 04, 2024



This work presents the design of Stickbug, a six-armed, multi-agent, precision pollination robot that combines the accuracy of single-agent systems with swarm parallelization in greenhouses. Precision pollination robots have often been proposed to offset the effects of a decreasing population of natural pollinators, but they frequently lack the required parallelization and scalability. Stickbug achieves this by allowing each arm and drive base to act as an individual agent, significantly reducing planning complexity. Stickbug uses a compact holonomic Kiwi drive to navigate narrow greenhouse rows, a tall mast to support multiple manipulators and reach plant heights, a detection model and classifier to identify Bramble flowers, and a felt-tipped end-effector for contact-based pollination. Initial experimental validation demonstrates that Stickbug can attempt over 1.5 pollinations per minute with a 50% success rate. Additionally, a Bramble flower perception dataset was created and is publicly available alongside Stickbug's software and design files.
CryptOpt: Automatic Optimization of Straightline Code
May 31, 2023



Manual engineering of high-performance implementations typically consumes many resources and requires in-depth knowledge of the hardware. Compilers try to address these problems; however, they are limited by design in what they can do. To address this, we present CryptOpt, an automatic optimizer for long stretches of straightline code. Experimental results across eight hardware platforms show that CryptOpt achieves a speed-up factor of up to 2.56 over current off-the-shelf compilers.
CryptOpt: Verified Compilation with Random Program Search for Cryptographic Primitives
Nov 19, 2022



Most software domains rely on compilers to translate high-level code to multiple different machine languages, with performance not too much worse than what developers would have the patience to write directly in assembly language. However, cryptography has been an exception, where many performance-critical routines have been written directly in assembly (sometimes through metaprogramming layers). Some past work has shown how to do formal verification of that assembly, and other work has shown how to generate C code automatically along with formal proof, but with consequent performance penalties vs. the best-known assembly. We present CryptOpt, the first compilation pipeline that specializes high-level cryptographic functional programs into assembly code significantly faster than what GCC or Clang produce, with mechanized proof (in Coq) whose final theorem statement mentions little beyond the input functional program and the operational semantics of x86-64 assembly. On the optimization side, we apply randomized search through the space of assembly programs, with repeated automatic benchmarking on target CPUs. On the formal-verification side, we connect to the Fiat Cryptography framework (which translates functional programs into C-like IR code) and extend it with a new formally verified program-equivalence checker, incorporating a modest subset of known features of SMT solvers and symbolic-execution engines. The overall prototype is quite practical, e.g. producing new fastest-known implementations for the relatively new Intel i9 12G, of finite-field arithmetic for both Curve25519 (part of the TLS standard) and the Bitcoin elliptic curve secp256k1.
A Comparison of Robust Kalman Filters for Improving Wheel-Inertial Odometry in Planetary Rovers
Dec 15, 2021
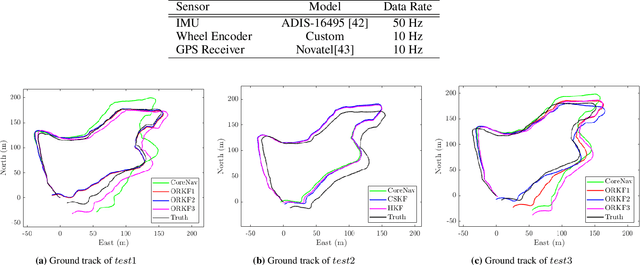
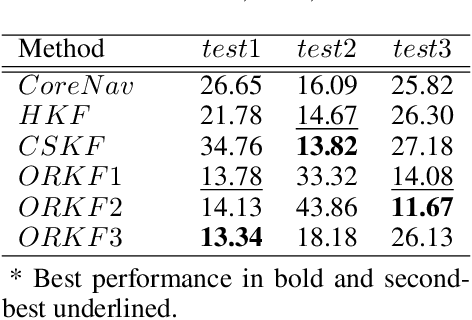
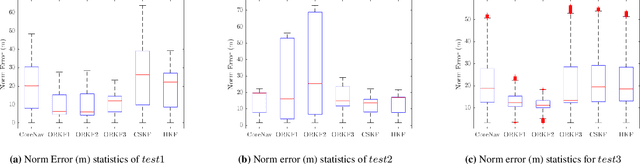
This paper compares the performance of adaptive and robust Kalman filter algorithms in improving wheel-inertial odometry on low featured rough terrain. Approaches include classical adaptive and robust methods as well as variational methods, which are evaluated experimentally on a wheeled rover in terrain similar to what would be encountered in planetary exploration. Variational filters show improved solution accuracy compared to the classical adaptive filters and are able to handle erroneous wheel odometry measurements and keep good localization for longer distances without significant drift. We also show how varying the parameters affects localization performance.
Review of Factor Graphs for Robust GNSS Applications
Dec 14, 2021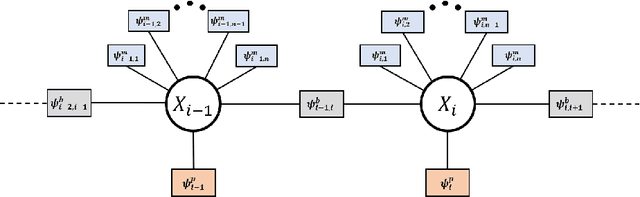
Factor graphs have recently emerged as an alternative solution method for GNSS positioning. In this article, we review how factor graphs are implemented in GNSS, some of their advantages over Kalman Filters, and their importance in making positioning solutions more robust to degraded measurements. We also talk about how factor graphs can be an important tool for the field radio-navigation community.