 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Explanations: An Explanatory Virtues Framework for Mechanistic Interpretability -- The Strange Science Part I.ii
May 02, 2025



Mechanistic Interpretability (MI) aims to understand neural networks through causal explanations. Though MI has many explanation-generating methods, progress has been limited by the lack of a universal approach to evaluating explanations. Here we analyse the fundamental question "What makes a good explanation?" We introduce a pluralist Explanatory Virtues Framework drawing on four perspectives from the Philosophy of Science - the Bayesian, Kuhnian, Deutschian, and Nomological - to systematically evaluate and improve explanations in MI. We find that Compact Proofs consider many explanatory virtues and are hence a promising approach. Fruitful research directions implied by our framework include (1) clearly defining explanatory simplicity, (2) focusing on unifying explanations and (3) deriving universal principles for neural networks. Improved MI methods enhance our ability to monitor, predict, and steer AI systems.
A Mathematical Philosophy of Explanations in Mechanistic Interpretability -- The Strange Science Part I.i
May 01, 2025Mechanistic Interpretability aims to understand neural networks through causal explanations. We argue for the Explanatory View Hypothesis: that Mechanistic Interpretability research is a principled approach to understanding models because neural networks contain implicit explanations which can be extracted and understood. We hence show that Explanatory Faithfulness, an assessment of how well an explanation fits a model, is well-defined. We propose a definition of Mechanistic Interpretability (MI) as the practice of producing Model-level, Ontic, Causal-Mechanistic, and Falsifiable explanations of neural networks, allowing us to distinguish MI from other interpretability paradigms and detail MI's inherent limits. We formulate the Principle of Explanatory Optimism, a conjecture which we argue is a necessary precondition for the success of Mechanistic Interpretability.
Unifying and Verifying Mechanistic Interpretations: A Case Study with Group Operations
Oct 09, 2024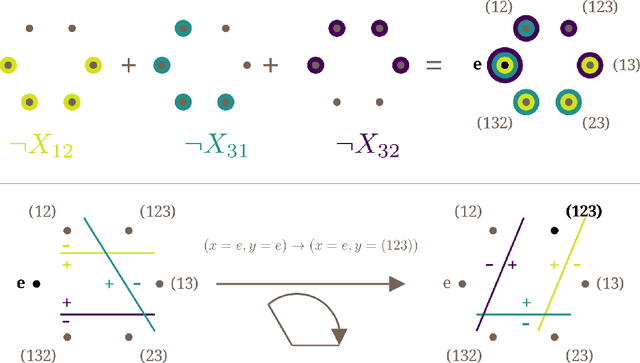
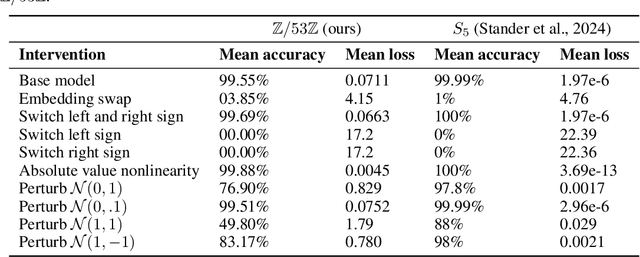
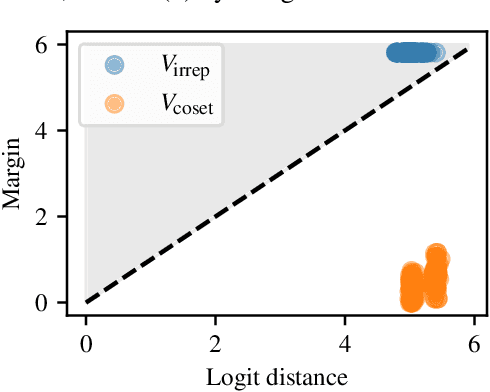

A recent line of work in mechanistic interpretability has focused on reverse-engineering the computation performed by neural networks trained on the binary operation of finite groups. We investigate the internals of one-hidden-layer neural networks trained on this task, revealing previously unidentified structure and producing a more complete description of such models that unifies the explanations of previous works. Notably, these models approximate equivariance in each input argument. We verify that our explanation applies to a large fraction of networks trained on this task by translating it into a compact proof of model performance, a quantitative evaluation of model understanding. In particular, our explanation yields a guarantee of model accuracy that runs in 30% the time of brute force and gives a >=95% accuracy bound for 45% of the models we trained. We were unable to obtain nontrivial non-vacuous accuracy bounds using only explanations from previous works.