 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Evaluating Explanations: An Explanatory Virtues Framework for Mechanistic Interpretability -- The Strange Science Part I.ii
May 02, 2025



Mechanistic Interpretability (MI) aims to understand neural networks through causal explanations. Though MI has many explanation-generating methods, progress has been limited by the lack of a universal approach to evaluating explanations. Here we analyse the fundamental question "What makes a good explanation?" We introduce a pluralist Explanatory Virtues Framework drawing on four perspectives from the Philosophy of Science - the Bayesian, Kuhnian, Deutschian, and Nomological - to systematically evaluate and improve explanations in MI. We find that Compact Proofs consider many explanatory virtues and are hence a promising approach. Fruitful research directions implied by our framework include (1) clearly defining explanatory simplicity, (2) focusing on unifying explanations and (3) deriving universal principles for neural networks. Improved MI methods enhance our ability to monitor, predict, and steer AI systems.
A Mathematical Philosophy of Explanations in Mechanistic Interpretability -- The Strange Science Part I.i
May 01, 2025Mechanistic Interpretability aims to understand neural networks through causal explanations. We argue for the Explanatory View Hypothesis: that Mechanistic Interpretability research is a principled approach to understanding models because neural networks contain implicit explanations which can be extracted and understood. We hence show that Explanatory Faithfulness, an assessment of how well an explanation fits a model, is well-defined. We propose a definition of Mechanistic Interpretability (MI) as the practice of producing Model-level, Ontic, Causal-Mechanistic, and Falsifiable explanations of neural networks, allowing us to distinguish MI from other interpretability paradigms and detail MI's inherent limits. We formulate the Principle of Explanatory Optimism, a conjecture which we argue is a necessary precondition for the success of Mechanistic Interpretability.
SAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
Adaptive Sparse Allocation with Mutual Choice & Feature Choice Sparse Autoencoders
Nov 04, 2024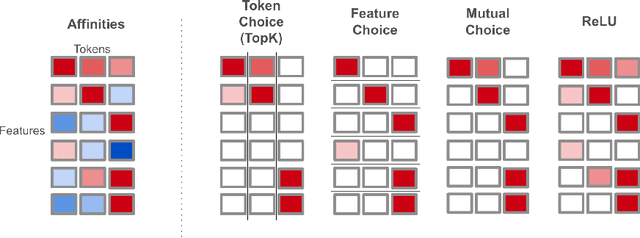

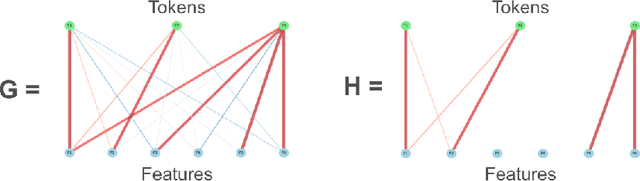

Sparse autoencoders (SAEs) are a promising approach to extracting features from neural networks, enabling model interpretability as well as causal interventions on model internals. SAEs generate sparse feature representations using a sparsifying activation function that implicitly defines a set of token-feature matches. We frame the token-feature matching as a resource allocation problem constrained by a total sparsity upper bound. For example, TopK SAEs solve this allocation problem with the additional constraint that each token matches with at most $k$ features. In TopK SAEs, the $k$ active features per token constraint is the same across tokens, despite some tokens being more difficult to reconstruct than others. To address this limitation, we propose two novel SAE variants, Feature Choice SAEs and Mutual Choice SAEs, which each allow for a variable number of active features per token. Feature Choice SAEs solve the sparsity allocation problem under the additional constraint that each feature matches with at most $m$ tokens. Mutual Choice SAEs solve the unrestricted allocation problem where the total sparsity budget can be allocated freely between tokens and features. Additionally, we introduce a new auxiliary loss function, $\mathtt{aux\_zipf\_loss}$, which generalises the $\mathtt{aux\_k\_loss}$ to mitigate dead and underutilised features. Our methods result in SAEs with fewer dead features and improved reconstruction loss at equivalent sparsity levels as a result of the inherent adaptive computation. More accurate and scalable feature extraction methods provide a path towards better understanding and more precise control of foundation models.
Interpretability as Compression: Reconsidering SAE Explanations of Neural Activations with MDL-SAEs
Oct 15, 2024Sparse Autoencoders (SAEs) have emerged as a useful tool for interpreting the internal representations of neural networks. However, naively optimising SAEs for reconstruction loss and sparsity results in a preference for SAEs that are extremely wide and sparse. We present an information-theoretic framework for interpreting SAEs as lossy compression algorithms for communicating explanations of neural activations. We appeal to the Minimal Description Length (MDL) principle to motivate explanations of activations which are both accurate and concise. We further argue that interpretable SAEs require an additional property, "independent additivity": features should be able to be understood separately. We demonstrate an example of applying our MDL-inspired framework by training SAEs on MNIST handwritten digits and find that SAE features representing significant line segments are optimal, as opposed to SAEs with features for memorised digits from the dataset or small digit fragments. We argue that using MDL rather than sparsity may avoid potential pitfalls with naively maximising sparsity such as undesirable feature splitting and that this framework naturally suggests new hierarchical SAE architectures which provide more concise explanations.