 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAEBench: A Comprehensive Benchmark for Sparse Autoencoders in Language Model Interpretability
Mar 13, 2025Sparse autoencoders (SAEs) are a popular technique for interpreting language model activations, and there is extensive recent work on improving SAE effectiveness. However, most prior work evaluates progress using unsupervised proxy metrics with unclear practical relevance. We introduce SAEBench, a comprehensive evaluation suite that measures SAE performance across seven diverse metrics, spanning interpretability, feature disentanglement and practical applications like unlearning. To enable systematic comparison, we open-source a suite of over 200 SAEs across eight recently proposed SAE architectures and training algorithms. Our evaluation reveals that gains on proxy metrics do not reliably translate to better practical performance. For instance, while Matryoshka SAEs slightly underperform on existing proxy metrics, they substantially outperform other architectures on feature disentanglement metrics; moreover, this advantage grows with SAE scale. By providing a standardized framework for measuring progress in SAE development, SAEBench enables researchers to study scaling trends and make nuanced comparisons between different SAE architectures and training methodologies. Our interactive interface enables researchers to flexibly visualize relationships between metrics across hundreds of open-source SAEs at: https://saebench.xyz
Sparse Autoencoders Do Not Find Canonical Units of Analysis
Feb 07, 2025



A common goal of mechanistic interpretability is to decompose the activations of neural networks into features: interpretable properties of the input computed by the model. Sparse autoencoders (SAEs) are a popular method for finding these features in LLMs, and it has been postulated that they can be used to find a \textit{canonical} set of units: a unique and complete list of atomic features. We cast doubt on this belief using two novel techniques: SAE stitching to show they are incomplete, and meta-SAEs to show they are not atomic. SAE stitching involves inserting or swapping latents from a larger SAE into a smaller one. Latents from the larger SAE can be divided into two categories: \emph{novel latents}, which improve performance when added to the smaller SAE, indicating they capture novel information, and \emph{reconstruction latents}, which can replace corresponding latents in the smaller SAE that have similar behavior. The existence of novel features indicates incompleteness of smaller SAEs. Using meta-SAEs -- SAEs trained on the decoder matrix of another SAE -- we find that latents in SAEs often decompose into combinations of latents from a smaller SAE, showing that larger SAE latents are not atomic. The resulting decompositions are often interpretable; e.g. a latent representing ``Einstein'' decomposes into ``scientist'', ``Germany'', and ``famous person''. Even if SAEs do not find canonical units of analysis, they may still be useful tools. We suggest that future research should either pursue different approaches for identifying such units, or pragmatically choose the SAE size suited to their task. We provide an interactive dashboard to explore meta-SAEs: https://metasaes.streamlit.app/
LLM Circuit Analyses Are Consistent Across Training and Scale
Jul 15, 2024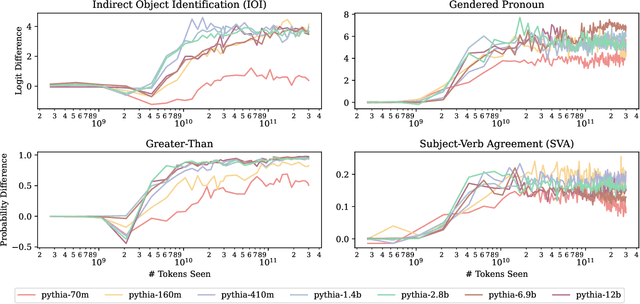
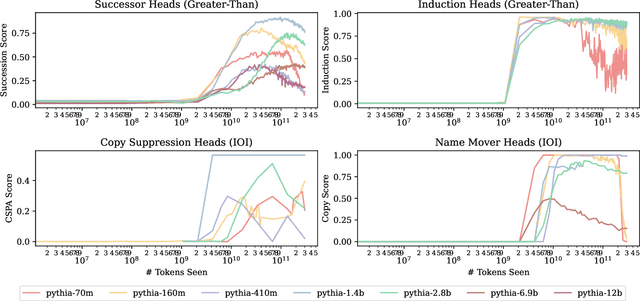
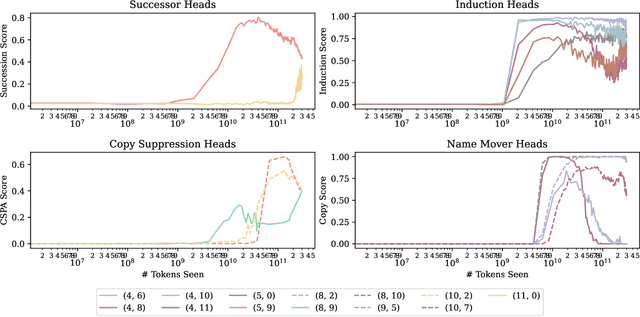
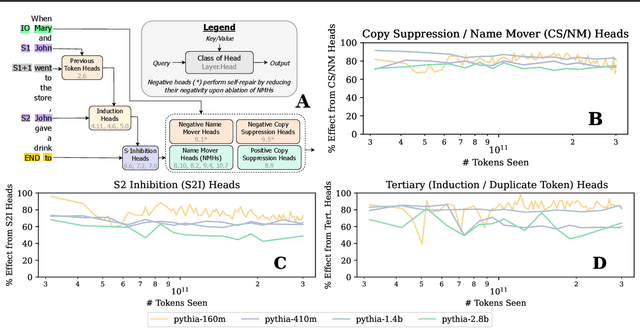
Most currently deployed large language models (LLMs) undergo continuous training or additional finetuning. By contrast, most research into LLMs' internal mechanisms focuses on models at one snapshot in time (the end of pre-training), raising the question of whether their results generalize to real-world settings. Existing studies of mechanisms over time focus on encoder-only or toy models, which differ significantly from most deployed models. In this study, we track how model mechanisms, operationalized as circuits, emerge and evolve across 300 billion tokens of training in decoder-only LLMs, in models ranging from 70 million to 2.8 billion parameters. We find that task abilities and the functional components that support them emerge consistently at similar token counts across scale. Moreover, although such components may be implemented by different attention heads over time, the overarching algorithm that they implement remains. Surprisingly, both these algorithms and the types of components involved therein can replicate across model scale. These results suggest that circuit analyses conducted on small models at the end of pre-training can provide insights that still apply after additional pre-training and over model scale.
Transformer-Based Models Are Not Yet Perfect At Learning to Emulate Structural Recursion
Jan 23, 2024



This paper investigates the ability of transformer-based models to learn structural recursion from examples. Recursion is a universal concept in both natural and formal languages. Structural recursion is central to the programming language and formal mathematics tasks where symbolic tools currently excel beyond neural models, such as inferring semantic relations between datatypes and emulating program behavior. We introduce a general framework that nicely connects the abstract concepts of structural recursion in the programming language domain to concrete sequence modeling problems and learned models' behavior. The framework includes a representation that captures the general \textit{syntax} of structural recursion, coupled with two different frameworks for understanding their \textit{semantics} -- one that is more natural from a programming languages perspective and one that helps bridge that perspective with a mechanistic understanding of the underlying transformer architecture. With our framework as a powerful conceptual tool, we identify different issues under various set-ups. The models trained to emulate recursive computations cannot fully capture the recursion yet instead fit short-cut algorithms and thus cannot solve certain edge cases that are under-represented in the training distribution. In addition, it is difficult for state-of-the-art large language models (LLMs) to mine recursive rules from in-context demonstrations. Meanwhile, these LLMs fail in interesting ways when emulating reduction (step-wise computation) of the recursive function.
Linear Representations of Sentiment in Large Language Models
Oct 23, 2023

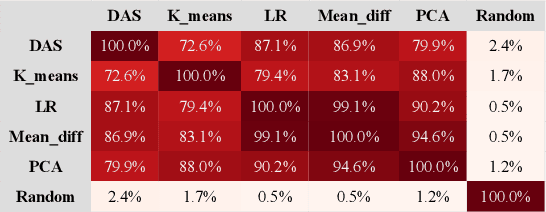
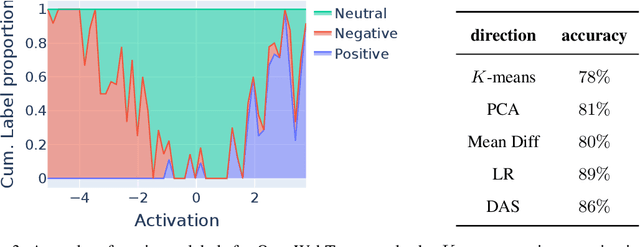
Sentiment is a pervasive feature in natural language text, yet it is an open question how sentiment is represented within Large Language Models (LLMs). In this study, we reveal that across a range of models, sentiment is represented linearly: a single direction in activation space mostly captures the feature across a range of tasks with one extreme for positive and the other for negative. Through causal interventions, we isolate this direction and show it is causally relevant in both toy tasks and real world datasets such as Stanford Sentiment Treebank. Through this case study we model a thorough investigation of what a single direction means on a broad data distribution. We further uncover the mechanisms that involve this direction, highlighting the roles of a small subset of attention heads and neurons. Finally, we discover a phenomenon which we term the summarization motif: sentiment is not solely represented on emotionally charged words, but is additionally summarized at intermediate positions without inherent sentiment, such as punctuation and names. We show that in Stanford Sentiment Treebank zero-shot classification, 76% of above-chance classification accuracy is lost when ablating the sentiment direction, nearly half of which (36%) is due to ablating the summarized sentiment direction exclusively at comma positions.
Can Transformers Learn to Solve Problems Recursively?
May 24, 2023



Neural networks have in recent years shown promise for helping software engineers write programs and even formally verify them. While semantic information plays a crucial part in these processes, it remains unclear to what degree popular neural architectures like transformers are capable of modeling that information. This paper examines the behavior of neural networks learning algorithms relevant to programs and formal verification proofs through the lens of mechanistic interpretability, focusing in particular on structural recursion. Structural recursion is at the heart of tasks on which symbolic tools currently outperform neural models, like inferring semantic relations between datatypes and emulating program behavior. We evaluate the ability of transformer models to learn to emulate the behavior of structurally recursive functions from input-output examples. Our evaluation includes empirical and conceptual analyses of the limitations and capabilities of transformer models in approximating these functions, as well as reconstructions of the ``shortcut" algorithms the model learns. By reconstructing these algorithms, we are able to correctly predict 91 percent of failure cases for one of the approximated functions. Our work provides a new foundation for understanding the behavior of neural networks that fail to solve the very tasks they are trained for.