 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Prediction of Dynamic Physical Simulations With Pixel-Space Spatiotemporal Transformers
Oct 23, 2025Inspired by the performance and scalability of autoregressive large language models (LLMs), transformer-based models have seen recent success in the visual domain. This study investigates a transformer adaptation for video prediction with a simple end-to-end approach, comparing various spatiotemporal self-attention layouts. Focusing on causal modeling of physical simulations over time; a common shortcoming of existing video-generative approaches, we attempt to isolate spatiotemporal reasoning via physical object tracking metrics and unsupervised training on physical simulation datasets. We introduce a simple yet effective pure transformer model for autoregressive video prediction, utilizing continuous pixel-space representations for video prediction. Without the need for complex training strategies or latent feature-learning components, our approach significantly extends the time horizon for physically accurate predictions by up to 50% when compared with existing latent-space approaches, while maintaining comparable performance on common video quality metrics. In addition, we conduct interpretability experiments to identify network regions that encode information useful to perform accurate estimations of PDE simulation parameters via probing models, and find that this generalizes to the estimation of out-of-distribution simulation parameters. This work serves as a platform for further attention-based spatiotemporal modeling of videos via a simple, parameter efficient, and interpretable approach.
* 14 pages, 14 figures
Inference-Time Decomposition of Activations (ITDA): A Scalable Approach to Interpreting Large Language Models
May 23, 2025Sparse autoencoders (SAEs) are a popular method for decomposing Large Langage Models (LLM) activations into interpretable latents. However, due to their substantial training cost, most academic research uses open-source SAEs which are only available for a restricted set of models of up to 27B parameters. SAE latents are also learned from a dataset of activations, which means they do not transfer between models. Motivated by relative representation similarity measures, we introduce Inference-Time Decomposition of Activations (ITDA) models, an alternative method for decomposing language model activations. To train an ITDA, we greedily construct a dictionary of language model activations on a dataset of prompts, selecting those activations which were worst approximated by matching pursuit on the existing dictionary. ITDAs can be trained in just 1\% of the time required for SAEs, using 1\% of the data. This allowed us to train ITDAs on Llama-3.1 70B and 405B on a single consumer GPU. ITDAs can achieve similar reconstruction performance to SAEs on some target LLMs, but generally incur a performance penalty. However, ITDA dictionaries enable cross-model comparisons, and a simple Jaccard similarity index on ITDA dictionaries outperforms existing methods like CKA, SVCCA, and relative representation similarity metrics. ITDAs provide a cheap alternative to SAEs where computational resources are limited, or when cross model comparisons are necessary. Code available at https://github.com/pleask/itda.
Analyzing LLMs' Knowledge Boundary Cognition Across Languages Through the Lens of Internal Representations
Apr 18, 2025While understanding the knowledge boundaries of LLMs is crucial to prevent hallucination, research on knowledge boundaries of LLMs has predominantly focused on English. In this work, we present the first study to analyze how LLMs recognize knowledge boundaries across different languages by probing their internal representations when processing known and unknown questions in multiple languages. Our empirical studies reveal three key findings: 1) LLMs' perceptions of knowledge boundaries are encoded in the middle to middle-upper layers across different languages. 2) Language differences in knowledge boundary perception follow a linear structure, which motivates our proposal of a training-free alignment method that effectively transfers knowledge boundary perception ability across languages, thereby helping reduce hallucination risk in low-resource languages; 3) Fine-tuning on bilingual question pair translation further enhances LLMs' recognition of knowledge boundaries across languages. Given the absence of standard testbeds for cross-lingual knowledge boundary analysis, we construct a multilingual evaluation suite comprising three representative types of knowledge boundary data. Our code and datasets are publicly available at https://github.com/DAMO-NLP-SG/LLM-Multilingual-Knowledge-Boundaries.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
Sparse Autoencoders Do Not Find Canonical Units of Analysis
Feb 07, 2025



A common goal of mechanistic interpretability is to decompose the activations of neural networks into features: interpretable properties of the input computed by the model. Sparse autoencoders (SAEs) are a popular method for finding these features in LLMs, and it has been postulated that they can be used to find a \textit{canonical} set of units: a unique and complete list of atomic features. We cast doubt on this belief using two novel techniques: SAE stitching to show they are incomplete, and meta-SAEs to show they are not atomic. SAE stitching involves inserting or swapping latents from a larger SAE into a smaller one. Latents from the larger SAE can be divided into two categories: \emph{novel latents}, which improve performance when added to the smaller SAE, indicating they capture novel information, and \emph{reconstruction latents}, which can replace corresponding latents in the smaller SAE that have similar behavior. The existence of novel features indicates incompleteness of smaller SAEs. Using meta-SAEs -- SAEs trained on the decoder matrix of another SAE -- we find that latents in SAEs often decompose into combinations of latents from a smaller SAE, showing that larger SAE latents are not atomic. The resulting decompositions are often interpretable; e.g. a latent representing ``Einstein'' decomposes into ``scientist'', ``Germany'', and ``famous person''. Even if SAEs do not find canonical units of analysis, they may still be useful tools. We suggest that future research should either pursue different approaches for identifying such units, or pragmatically choose the SAE size suited to their task. We provide an interactive dashboard to explore meta-SAEs: https://metasaes.streamlit.app/
Everything is a Video: Unifying Modalities through Next-Frame Prediction
Nov 15, 2024Multimodal learning, which involves integrating information from various modalities such as text, images, audio, and video, is pivotal for numerous complex tasks like visual question answering, cross-modal retrieval, and caption generation. Traditional approaches rely on modality-specific encoders and late fusion techniques, which can hinder scalability and flexibility when adapting to new tasks or modalities. To address these limitations, we introduce a novel framework that extends the concept of task reformulation beyond natural language processing (NLP) to multimodal learning. We propose to reformulate diverse multimodal tasks into a unified next-frame prediction problem, allowing a single model to handle different modalities without modality-specific components. This method treats all inputs and outputs as sequential frames in a video, enabling seamless integration of modalities and effective knowledge transfer across tasks. Our approach is evaluated on a range of tasks, including text-to-text, image-to-text, video-to-video, video-to-text, and audio-to-text, demonstrating the model's ability to generalize across modalities with minimal adaptation. We show that task reformulation can significantly simplify multimodal model design across various tasks, laying the groundwork for more generalized multimodal foundation models.
Breaking Down Financial News Impact: A Novel AI Approach with Geometric Hypergraphs
Aug 31, 2024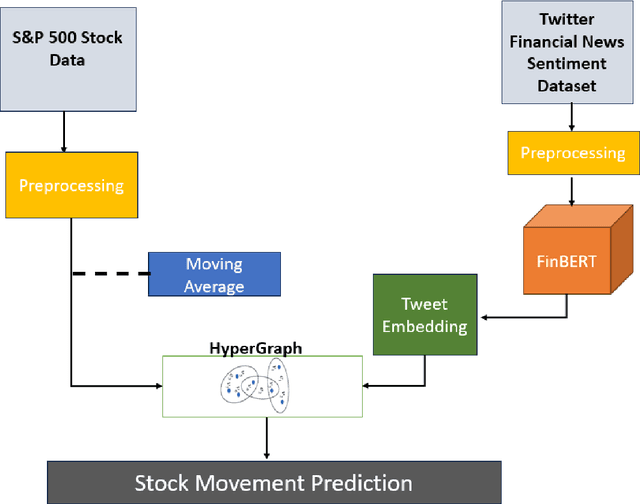
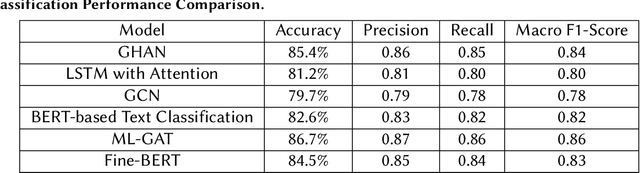
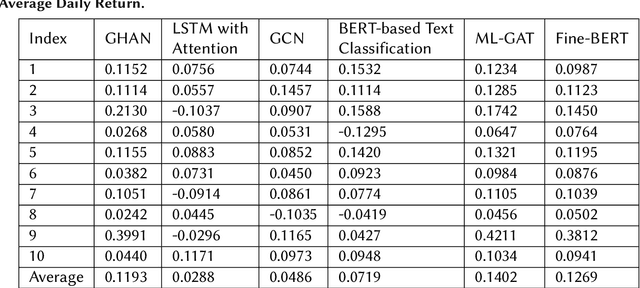
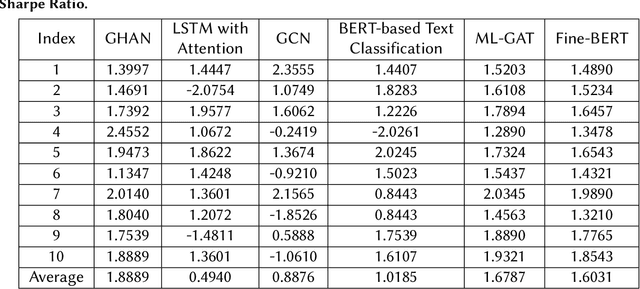
In the fast-paced and volatile financial markets, accurately predicting stock movements based on financial news is critical for investors and analysts. Traditional models often struggle to capture the intricate and dynamic relationships between news events and market reactions, limiting their ability to provide actionable insights. This paper introduces a novel approach leveraging Explainable Artificial Intelligence (XAI) through the development of a Geometric Hypergraph Attention Network (GHAN) to analyze the impact of financial news on market behaviours. Geometric hypergraphs extend traditional graph structures by allowing edges to connect multiple nodes, effectively modelling high-order relationships and interactions among financial entities and news events. This unique capability enables the capture of complex dependencies, such as the simultaneous impact of a single news event on multiple stocks or sectors, which traditional models frequently overlook. By incorporating attention mechanisms within hypergraphs, GHAN enhances the model's ability to focus on the most relevant information, ensuring more accurate predictions and better interpretability. Additionally, we employ BERT-based embeddings to capture the semantic richness of financial news texts, providing a nuanced understanding of the content. Using a comprehensive financial news dataset, our GHAN model addresses key challenges in financial news impact analysis, including the complexity of high-order interactions, the necessity for model interpretability, and the dynamic nature of financial markets. Integrating attention mechanisms and SHAP values within GHAN ensures transparency, highlighting the most influential factors driving market predictions. Empirical validation demonstrates the superior effectiveness of our approach over traditional sentiment analysis and time-series models.
X-ray Made Simple: Radiology Report Generation and Evaluation with Layman's Terms
Jun 25, 2024



Radiology Report Generation (RRG) has achieved significant progress with the advancements of multimodal generative models. However, the evaluation in the domain suffers from a lack of fair and robust metrics. We reveal that, high performance on RRG with existing lexical-based metrics (e.g. BLEU) might be more of a mirage - a model can get a high BLEU only by learning the template of reports. This has become an urgent problem for RRG due to the highly patternized nature of these reports. In this work, we un-intuitively approach this problem by proposing the Layman's RRG framework, a layman's terms-based dataset, evaluation and training framework that systematically improves RRG with day-to-day language. We first contribute the translated Layman's terms dataset. Building upon the dataset, we then propose a semantics-based evaluation method, which is proved to mitigate the inflated numbers of BLEU and provides fairer evaluation. Last, we show that training on the layman's terms dataset encourages models to focus on the semantics of the reports, as opposed to overfitting to learning the report templates. We reveal a promising scaling law between the number of training examples and semantics gain provided by our dataset, compared to the inverse pattern brought by the original formats. Our code is available at \url{https://github.com/hegehongcha/LaymanRRG}.
AttenCraft: Attention-guided Disentanglement of Multiple Concepts for Text-to-Image Customization
May 28, 2024



With the unprecedented performance being achieved by text-to-image (T2I) diffusion models, T2I customization further empowers users to tailor the diffusion model to new concepts absent in the pre-training dataset, termed subject-driven generation. Moreover, extracting several new concepts from a single image enables the model to learn multiple concepts, and simultaneously decreases the difficulties of training data preparation, urging the disentanglement of multiple concepts to be a new challenge. However, existing models for disentanglement commonly require pre-determined masks or retain background elements. To this end, we propose an attention-guided method, AttenCraft, for multiple concept disentanglement. In particular, our method leverages self-attention and cross-attention maps to create accurate masks for each concept within a single initialization step, omitting any required mask preparation by humans or other models. The created masks are then applied to guide the cross-attention activation of each target concept during training and achieve concept disentanglement. Additionally, we introduce Uniform sampling and Reweighted sampling schemes to alleviate the non-synchronicity of feature acquisition from different concepts, and improve generation quality. Our method outperforms baseline models in terms of image-alignment, and behaves comparably on text-alignment. Finally, we showcase the applicability of AttenCraft to more complicated settings, such as an input image containing three concepts. The project is available at https://github.com/junjie-shentu/AttenCraft.
RAR-b: Reasoning as Retrieval Benchmark
Apr 09, 2024



Semantic textual similartiy (STS) and information retrieval tasks (IR) tasks have been the two major avenues to record the progress of embedding models in the past few years. Under the emerging Retrieval-augmented Generation (RAG) paradigm, we envision the need to evaluate next-level language understanding abilities of embedding models, and take a conscious look at the reasoning abilities stored in them. Addressing this, we pose the question: Can retrievers solve reasoning problems? By transforming reasoning tasks into retrieval tasks, we find that without specifically trained for reasoning-level language understanding, current state-of-the-art retriever models may still be far from being competent for playing the role of assisting LLMs, especially in reasoning-intensive tasks. Moreover, albeit trained to be aware of instructions, instruction-aware IR models are often better off without instructions in inference time for reasoning tasks, posing an overlooked retriever-LLM behavioral gap for the research community to align. However, recent decoder-based embedding models show great promise in narrowing the gap, highlighting the pathway for embedding models to achieve reasoning-level language understanding. We also show that, although current off-the-shelf re-ranker models fail on these tasks, injecting reasoning abilities into them through fine-tuning still appears easier than doing so to bi-encoders, and we are able to achieve state-of-the-art performance across all tasks by fine-tuning a reranking model. We release Reasoning as Retrieval Benchmark (RAR-b), a holistic suite of tasks and settings to evaluate the reasoning abilities stored in retriever models. RAR-b is available at https://github.com/gowitheflow-1998/RAR-b.