 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Racial Phenotypes: Fine-Grained Control of Race-related Facial Phenotype Characteristics
Mar 29, 2024Achieving an effective fine-grained appearance variation over 2D facial images, whilst preserving facial identity, is a challenging task due to the high complexity and entanglement of common 2D facial feature encoding spaces. Despite these challenges, such fine-grained control, by way of disentanglement is a crucial enabler for data-driven racial bias mitigation strategies across multiple automated facial analysis tasks, as it allows to analyse, characterise and synthesise human facial diversity. In this paper, we propose a novel GAN framework to enable fine-grained control over individual race-related phenotype attributes of the facial images. Our framework factors the latent (feature) space into elements that correspond to race-related facial phenotype representations, thereby separating phenotype aspects (e.g. skin, hair colour, nose, eye, mouth shapes), which are notoriously difficult to annotate robustly in real-world facial data. Concurrently, we also introduce a high quality augmented, diverse 2D face image dataset drawn from CelebA-HQ for GAN training. Unlike prior work, our framework only relies upon 2D imagery and related parameters to achieve state-of-the-art individual control over race-related phenotype attributes with improved photo-realistic output.
Racial Bias within Face Recognition: A Survey
May 01, 2023



Facial recognition is one of the most academically studied and industrially developed areas within computer vision where we readily find associated applications deployed globally. This widespread adoption has uncovered significant performance variation across subjects of different racial profiles leading to focused research attention on racial bias within face recognition spanning both current causation and future potential solutions. In support, this study provides an extensive taxonomic review of research on racial bias within face recognition exploring every aspect and stage of the face recognition processing pipeline. Firstly, we discuss the problem definition of racial bias, starting with race definition, grouping strategies, and the societal implications of using race or race-related groupings. Secondly, we divide the common face recognition processing pipeline into four stages: image acquisition, face localisation, face representation, face verification and identification, and review the relevant corresponding literature associated with each stage. The overall aim is to provide comprehensive coverage of the racial bias problem with respect to each and every stage of the face recognition processing pipeline whilst also highlighting the potential pitfalls and limitations of contemporary mitigation strategies that need to be considered within future research endeavours or commercial applications alike.
Does lossy image compression affect racial bias within face recognition?
Aug 16, 2022

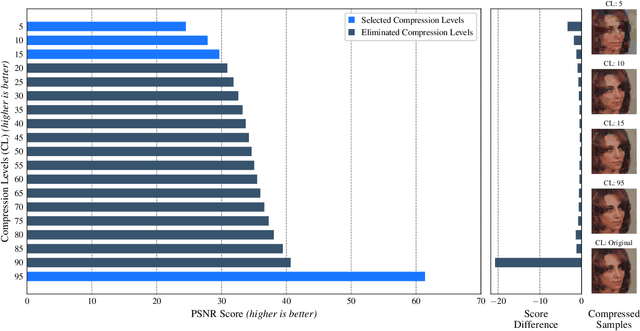

Yes - This study investigates the impact of commonplace lossy image compression on face recognition algorithms with regard to the racial characteristics of the subject. We adopt a recently proposed racial phenotype-based bias analysis methodology to measure the effect of varying levels of lossy compression across racial phenotype categories. Additionally, we determine the relationship between chroma-subsampling and race-related phenotypes for recognition performance. Prior work investigates the impact of lossy JPEG compression algorithm on contemporary face recognition performance. However, there is a gap in how this impact varies with different race-related inter-sectional groups and the cause of this impact. Via an extensive experimental setup, we demonstrate that common lossy image compression approaches have a more pronounced negative impact on facial recognition performance for specific racial phenotype categories such as darker skin tones (by up to 34.55\%). Furthermore, removing chroma-subsampling during compression improves the false matching rate (up to 15.95\%) across all phenotype categories affected by the compression, including darker skin tones, wide noses, big lips, and monolid eye categories. In addition, we outline the characteristics that may be attributable as the underlying cause of such phenomenon for lossy compression algorithms such as JPEG.
Measuring Hidden Bias within Face Recognition via Racial Phenotypes
Oct 19, 2021
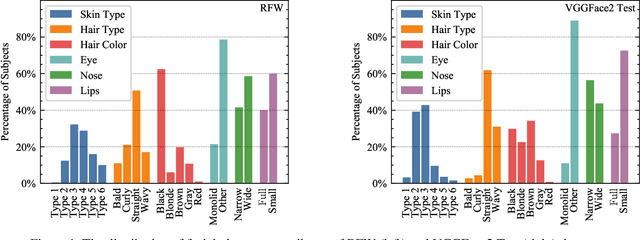

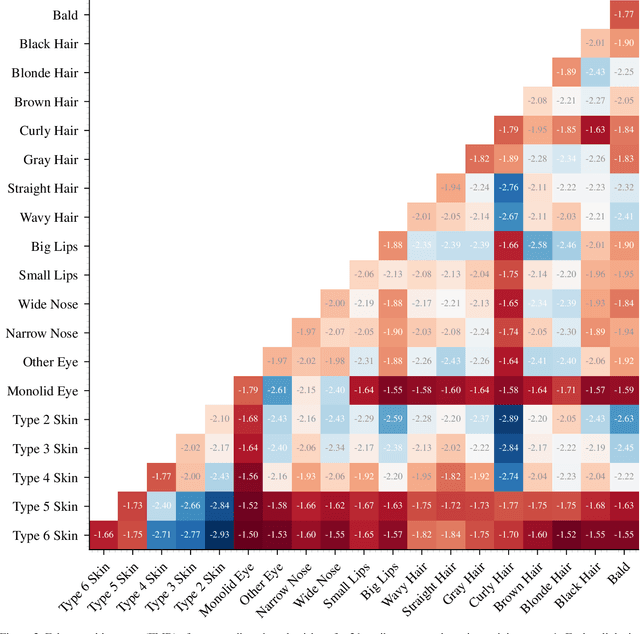
Recent work reports disparate performance for intersectional racial groups across face recognition tasks: face verification and identification. However, the definition of those racial groups has a significant impact on the underlying findings of such racial bias analysis. Previous studies define these groups based on either demographic information (e.g. African, Asian etc.) or skin tone (e.g. lighter or darker skins). The use of such sensitive or broad group definitions has disadvantages for bias investigation and subsequent counter-bias solutions design. By contrast, this study introduces an alternative racial bias analysis methodology via facial phenotype attributes for face recognition. We use the set of observable characteristics of an individual face where a race-related facial phenotype is hence specific to the human face and correlated to the racial profile of the subject. We propose categorical test cases to investigate the individual influence of those attributes on bias within face recognition tasks. We compare our phenotype-based grouping methodology with previous grouping strategies and show that phenotype-based groupings uncover hidden bias without reliance upon any potentially protected attributes or ill-defined grouping strategies. Furthermore, we contribute corresponding phenotype attribute category labels for two face recognition tasks: RFW for face verification and VGGFace2 (test set) for face identification.
RSSI-based Outdoor Localization with Single Unmanned Aerial Vehicle
Apr 20, 2020

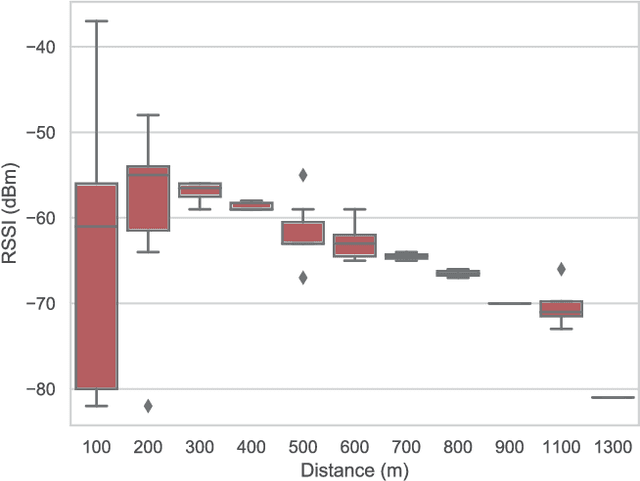
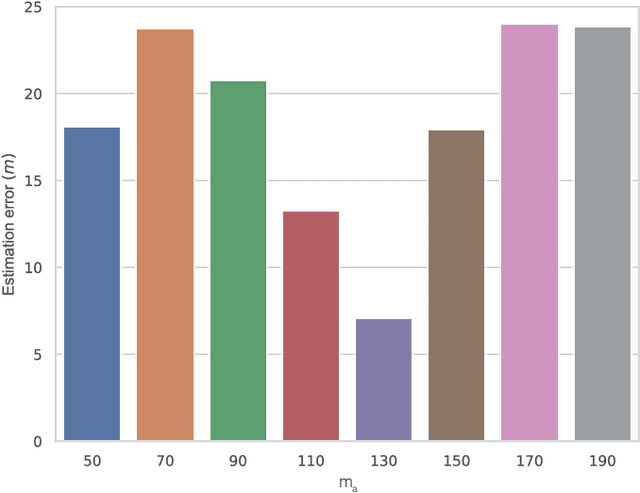
Localization of a target object has been performed conventionally using multiple terrestrial reference nodes. This paradigm is recently shifted towards utilization of unmanned aerial vehicles (UAVs) for locating target objects. Since locating of a target using simultaneous multiple UAVs is costly and impractical, achieving this task by utilizing single UAV becomes desirable. Hence, in this paper, we propose an RSSI-based localization method that utilizes only a single UAV. The proposed approach is based on clustering method along with the Singular Value Decomposition (SVD). The performance of the proposed method is verified by the experimental measurements collected by a UAV that we have designed and computer simulations. The results show that the proposed method can achieve location accuracy as low as 7m depending on the number of iterations.
Exploring Racial Bias within Face Recognition via per-subject Adversarially-Enabled Data Augmentation
Apr 19, 2020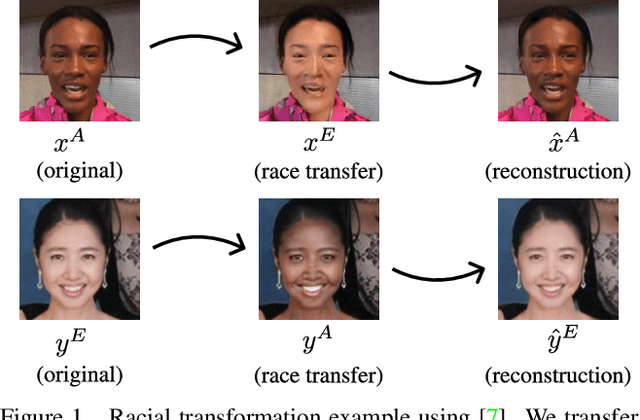
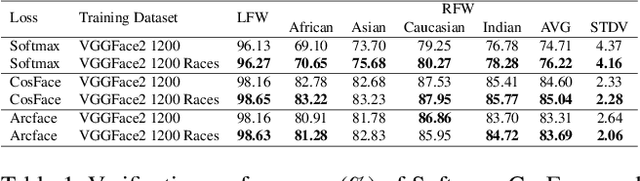
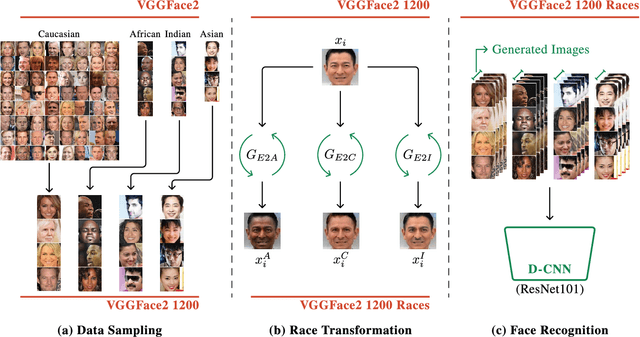

Whilst face recognition applications are becoming increasingly prevalent within our daily lives, leading approaches in the field still suffer from performance bias to the detriment of some racial profiles within society. In this study, we propose a novel adversarial derived data augmentation methodology that aims to enable dataset balance at a per-subject level via the use of image-to-image transformation for the transfer of sensitive racial characteristic facial features. Our aim is to automatically construct a synthesised dataset by transforming facial images across varying racial domains, while still preserving identity-related features, such that racially dependant features subsequently become irrelevant within the determination of subject identity. We construct our experiments on three significant face recognition variants: Softmax, CosFace and ArcFace loss over a common convolutional neural network backbone. In a side-by-side comparison, we show the positive impact our proposed technique can have on the recognition performance for (racial) minority groups within an originally imbalanced training dataset by reducing the pre-race variance in performance.
3D Human Action Recognition with Siamese-LSTM Based Deep Metric Learning
Jul 05, 2018
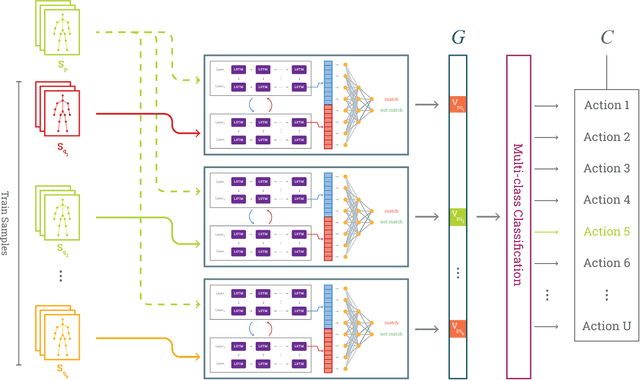

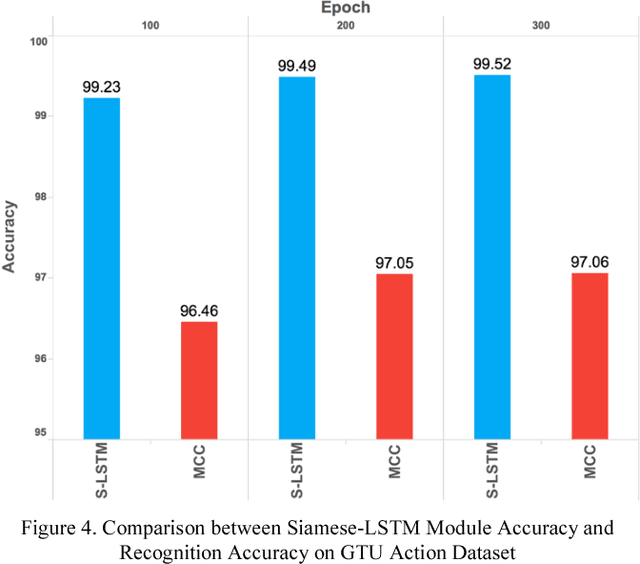
This paper proposes a new 3D Human Action Recognition system as a two-phase system: (1) Deep Metric Learning Module which learns a similarity metric between two 3D joint sequences using Siamese-LSTM networks; (2) A Multiclass Classification Module that uses the output of the first module to produce the final recognition output. This model has several advantages: the first module is trained with a larger set of data because it uses many combinations of sequence pairs.Our deep metric learning module can also be trained independently of the datasets, which makes our system modular and generalizable. We tested the proposed system on standard and newly introduced datasets that showed us that initial results are promising. We will continue developing this system by adding more sophisticated LSTM blocks and by cross-training between different datasets.