 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-aware multi-scale heatmap regression for 2D hand pose estimation
May 23, 2021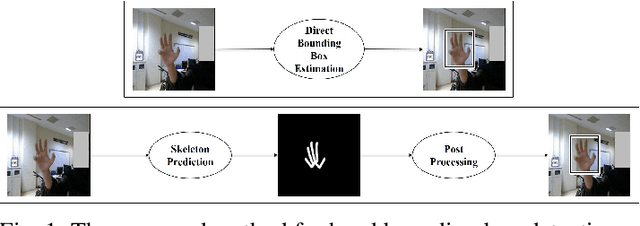
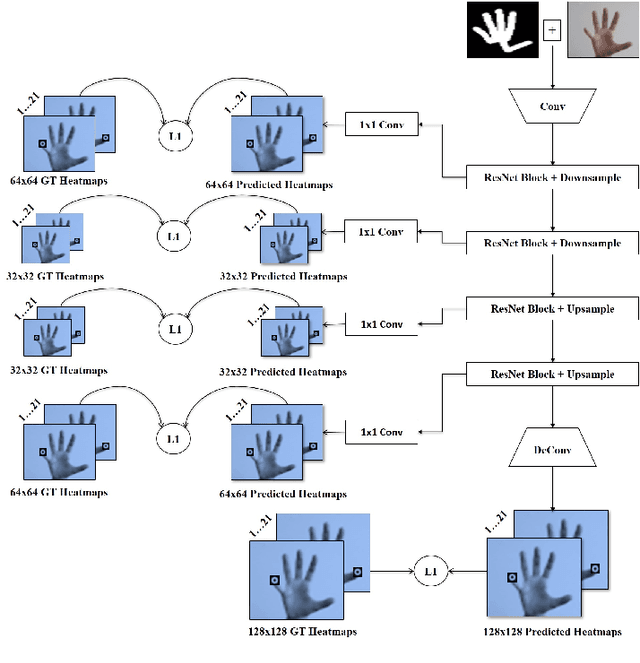


Existing RGB-based 2D hand pose estimation methods learn the joint locations from a single resolution, which is not suitable for different hand sizes. To tackle this problem, we propose a new deep learning-based framework that consists of two main modules. The former presents a segmentation-based approach to detect the hand skeleton and localize the hand bounding box. The second module regresses the 2D joint locations through a multi-scale heatmap regression approach that exploits the predicted hand skeleton as a constraint to guide the model. Furthermore, we construct a new dataset that is suitable for both hand detection and pose estimation. We qualitatively and quantitatively validate our method on two datasets. Results demonstrate that the proposed method outperforms state-of-the-art and can recover the pose even in cluttered images and complex poses.
A hybrid classification-regression approach for 3D hand pose estimation using graph convolutional networks
May 23, 2021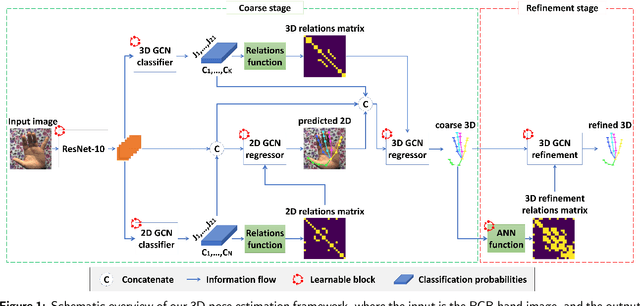
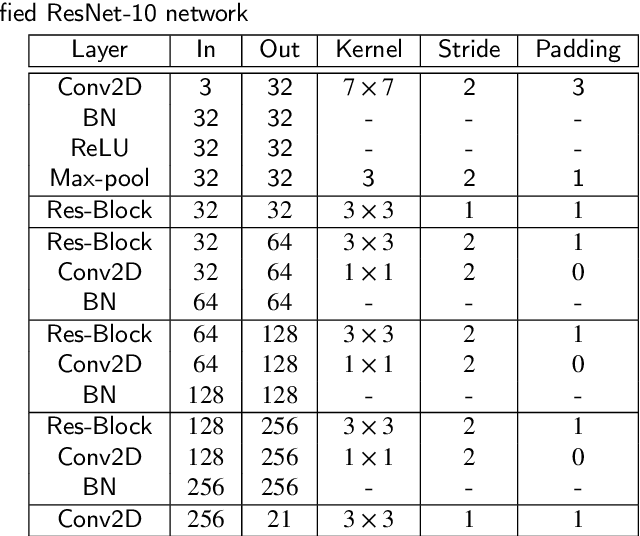
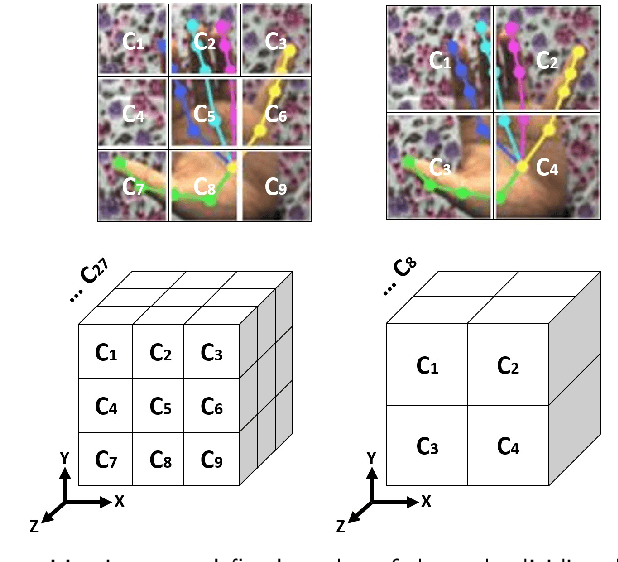
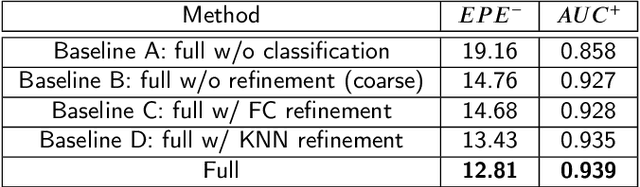
Hand pose estimation is a crucial part of a wide range of augmented reality and human-computer interaction applications. Predicting the 3D hand pose from a single RGB image is challenging due to occlusion and depth ambiguities. GCN-based (Graph Convolutional Networks) methods exploit the structural relationship similarity between graphs and hand joints to model kinematic dependencies between joints. These techniques use predefined or globally learned joint relationships, which may fail to capture pose-dependent constraints. To address this problem, we propose a two-stage GCN-based framework that learns per-pose relationship constraints. Specifically, the first phase quantizes the 2D/3D space to classify the joints into 2D/3D blocks based on their locality. This spatial dependency information guides this phase to estimate reliable 2D and 3D poses. The second stage further improves the 3D estimation through a GCN-based module that uses an adaptative nearest neighbor algorithm to determine joint relationships. Extensive experiments show that our multi-stage GCN approach yields an efficient model that produces accurate 2D/3D hand poses and outperforms the state-of-the-art on two public datasets.
Texture-aware Multi-resolution Image Inpainting
Sep 30, 2020
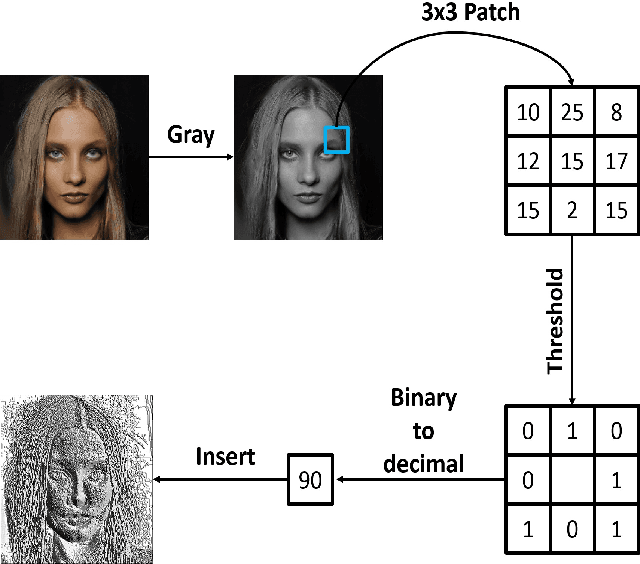
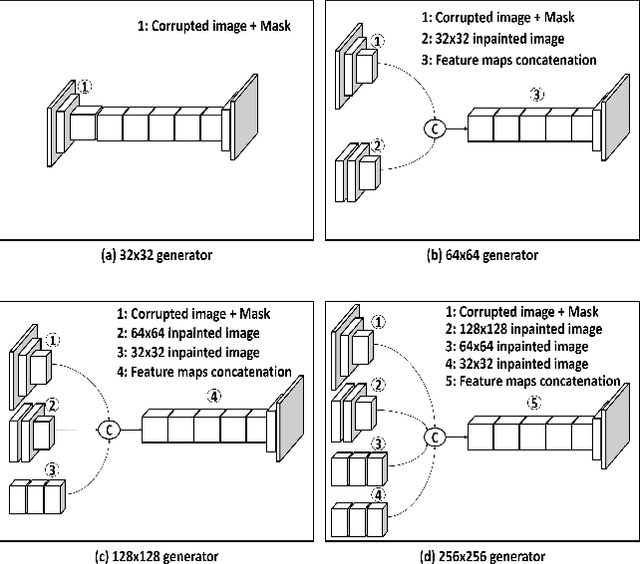

Recent GAN-based inpainting methods have shown remarkable performance using multi-stage networks and/or contextual attention modules (CAM). However, these models require heavy computational resources and may fail to restore realistic texture details. This is mainly due to their training approaches and loss functions. Furthermore, GANs are hard to train on high-resolution images leading to unstable models and poor performance. Inspired by these observations, we propose a novel multi-resolution generators architecture allowing stable training and increased performance. Specifically, our training schema optimizes the parameters of four successive generators such that higher resolution generators exploit the inpainted images produced by lower resolution generators. To restore fine-grained textures, we present a new LBP-based loss function that minimizes the difference between the generated and ground truth textures. We conduct our experiments on Places2 and CelebHQ datasets, and we report qualitative and quantitative results against the state-of-the-art methods. Results show that the computationally efficient model achieves competitive performance.
RSSI-based Outdoor Localization with Single Unmanned Aerial Vehicle
Apr 20, 2020

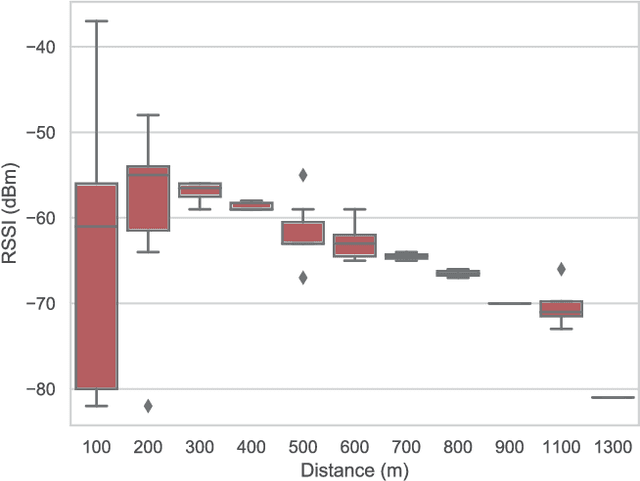
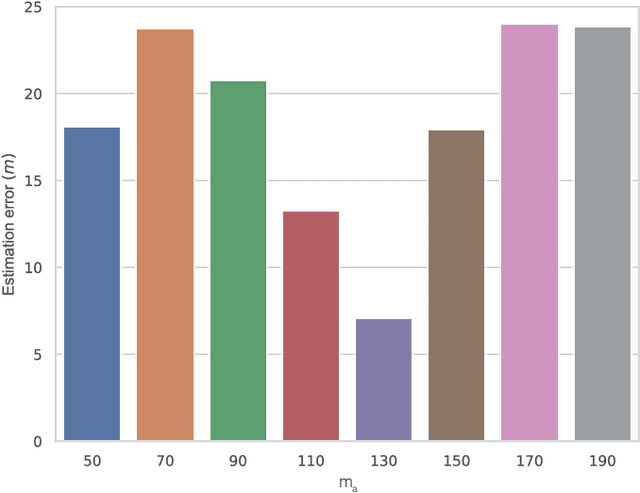
Localization of a target object has been performed conventionally using multiple terrestrial reference nodes. This paradigm is recently shifted towards utilization of unmanned aerial vehicles (UAVs) for locating target objects. Since locating of a target using simultaneous multiple UAVs is costly and impractical, achieving this task by utilizing single UAV becomes desirable. Hence, in this paper, we propose an RSSI-based localization method that utilizes only a single UAV. The proposed approach is based on clustering method along with the Singular Value Decomposition (SVD). The performance of the proposed method is verified by the experimental measurements collected by a UAV that we have designed and computer simulations. The results show that the proposed method can achieve location accuracy as low as 7m depending on the number of iterations.
Learning to Inpaint by Progressively Growing the Mask Regions
Feb 21, 2020

Image inpainting is one of the most challenging tasks in computer vision. Recently, generative-based image inpainting methods have been shown to produce visually plausible images. However, they still have difficulties to generate the correct structures and colors as the masked region grows large. This drawback is due to the training stability issue of the generative models. This work introduces a new curriculum-style training approach in the context of image inpainting. The proposed method increases the masked region size progressively in training time, during test time the user gives variable size and multiple holes at arbitrary locations. Incorporating such an approach in GANs may stabilize the training and provides better color consistencies and captures object continuities. We validate our approach on the MSCOCO and CelebA datasets. We report qualitative and quantitative comparisons of our training approach in different models.