 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised structured object representation learning
Aug 27, 2025Self-supervised learning (SSL) has emerged as a powerful technique for learning visual representations. While recent SSL approaches achieve strong results in global image understanding, they are limited in capturing the structured representation in scenes. In this work, we propose a self-supervised approach that progressively builds structured visual representations by combining semantic grouping, instance level separation, and hierarchical structuring. Our approach, based on a novel ProtoScale module, captures visual elements across multiple spatial scales. Unlike common strategies like DINO that rely on random cropping and global embeddings, we preserve full scene context across augmented views to improve performance in dense prediction tasks. We validate our method on downstream object detection tasks using a combined subset of multiple datasets (COCO and UA-DETRAC). Experimental results show that our method learns object centric representations that enhance supervised object detection and outperform the state-of-the-art methods, even when trained with limited annotated data and fewer fine-tuning epochs.
Enhancing knowledge retention for continual learning with domain-specific adapters and features gating
Apr 11, 2025Continual learning empowers models to learn from a continuous stream of data while preserving previously acquired knowledge, effectively addressing the challenge of catastrophic forgetting. In this study, we propose a new approach that integrates adapters within the self-attention mechanisms of Vision Transformers to enhance knowledge retention when sequentially adding datasets from different domains. Unlike previous methods that continue learning with only one dataset, our approach introduces domain-specific output heads and feature gating, allowing the model to maintain high accuracy on previously learned tasks while incorporating only the essential information from multiple domains. The proposed method is compared to prominent parameter-efficient fine-tuning methods in the current state of the art. The results provide evidence that our method effectively alleviates the limitations of previous works. Furthermore, we conduct a comparative analysis using three datasets, CIFAR-100, Flowers102, and DTD, each representing a distinct domain, to investigate the impact of task order on model performance. Our findings underscore the critical role of dataset sequencing in shaping learning outcomes, demonstrating that strategic ordering can significantly improve the model's ability to adapt to evolving data distributions over time while preserving the integrity of previously learned knowledge.
Single image calibration using knowledge distillation approaches
Dec 05, 2022Although recent deep learning-based calibration methods can predict extrinsic and intrinsic camera parameters from a single image, their generalization remains limited by the number and distribution of training data samples. The huge computational and space requirement prevents convolutional neural networks (CNNs) from being implemented in resource-constrained environments. This challenge motivated us to learn a CNN gradually, by training new data while maintaining performance on previously learned data. Our approach builds upon a CNN architecture to automatically estimate camera parameters (focal length, pitch, and roll) using different incremental learning strategies to preserve knowledge when updating the network for new data distributions. Precisely, we adapt four common incremental learning, namely: LwF , iCaRL, LU CIR, and BiC by modifying their loss functions to our regression problem. We evaluate on two datasets containing 299008 indoor and outdoor images. Experiment results were significant and indicated which method was better for the camera calibration estimation.
Texture-aware Multi-resolution Image Inpainting
Sep 30, 2020
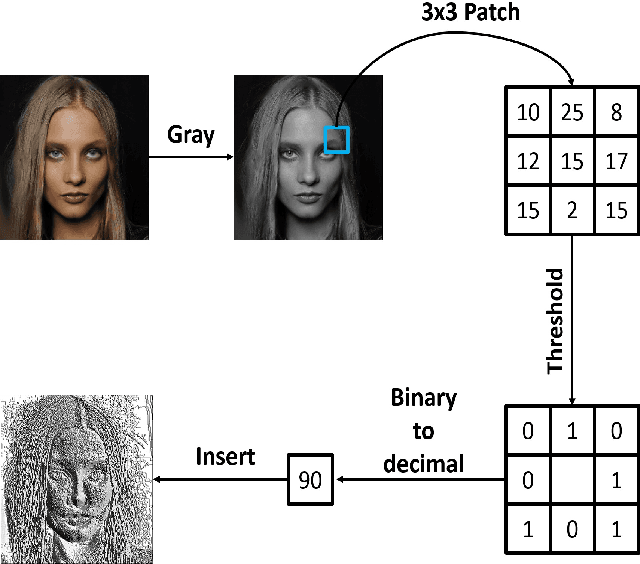
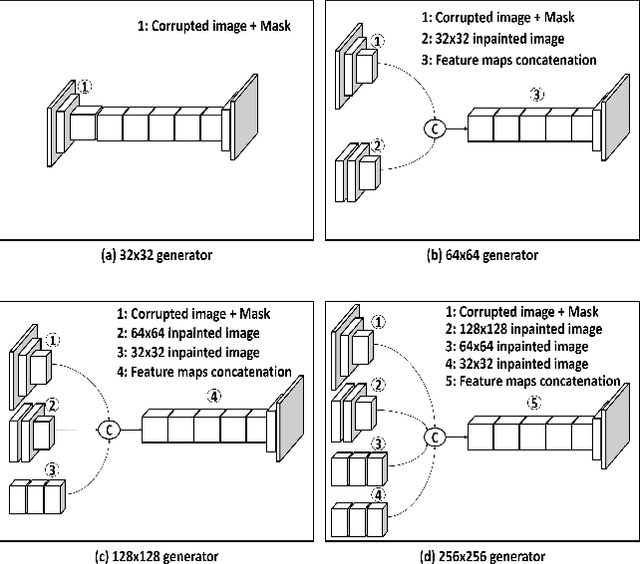

Recent GAN-based inpainting methods have shown remarkable performance using multi-stage networks and/or contextual attention modules (CAM). However, these models require heavy computational resources and may fail to restore realistic texture details. This is mainly due to their training approaches and loss functions. Furthermore, GANs are hard to train on high-resolution images leading to unstable models and poor performance. Inspired by these observations, we propose a novel multi-resolution generators architecture allowing stable training and increased performance. Specifically, our training schema optimizes the parameters of four successive generators such that higher resolution generators exploit the inpainted images produced by lower resolution generators. To restore fine-grained textures, we present a new LBP-based loss function that minimizes the difference between the generated and ground truth textures. We conduct our experiments on Places2 and CelebHQ datasets, and we report qualitative and quantitative results against the state-of-the-art methods. Results show that the computationally efficient model achieves competitive performance.
Learning to Inpaint by Progressively Growing the Mask Regions
Feb 21, 2020

Image inpainting is one of the most challenging tasks in computer vision. Recently, generative-based image inpainting methods have been shown to produce visually plausible images. However, they still have difficulties to generate the correct structures and colors as the masked region grows large. This drawback is due to the training stability issue of the generative models. This work introduces a new curriculum-style training approach in the context of image inpainting. The proposed method increases the masked region size progressively in training time, during test time the user gives variable size and multiple holes at arbitrary locations. Incorporating such an approach in GANs may stabilize the training and provides better color consistencies and captures object continuities. We validate our approach on the MSCOCO and CelebA datasets. We report qualitative and quantitative comparisons of our training approach in different models.