 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture-aware Multi-resolution Image Inpainting
Paper and Code
Sep 30, 2020
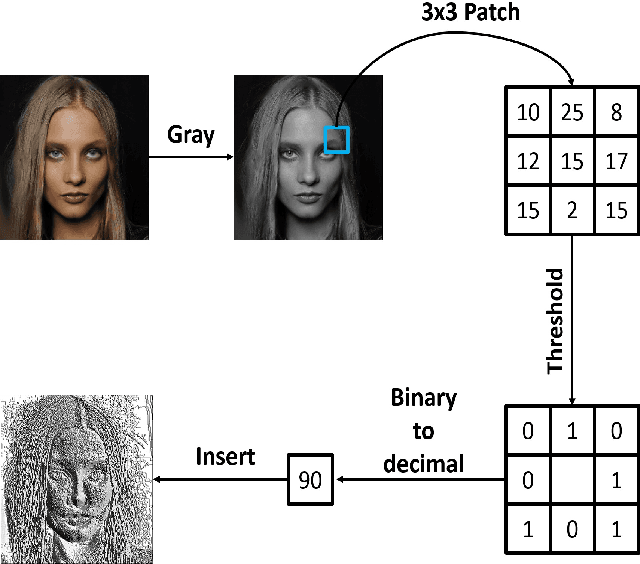
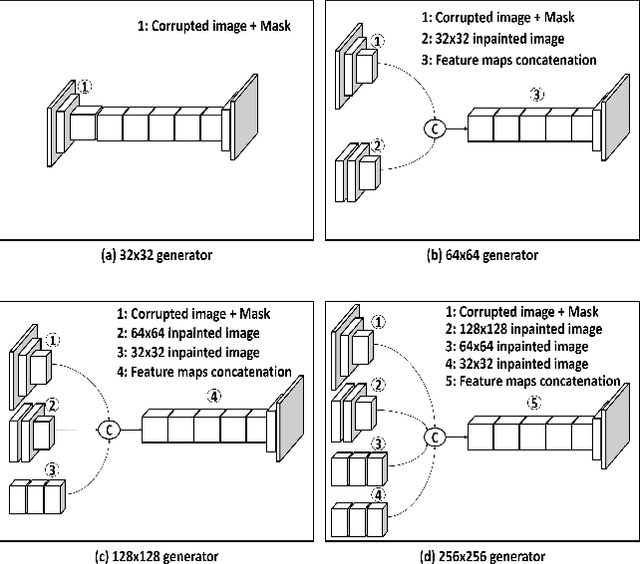

Recent GAN-based inpainting methods have shown remarkable performance using multi-stage networks and/or contextual attention modules (CAM). However, these models require heavy computational resources and may fail to restore realistic texture details. This is mainly due to their training approaches and loss functions. Furthermore, GANs are hard to train on high-resolution images leading to unstable models and poor performance. Inspired by these observations, we propose a novel multi-resolution generators architecture allowing stable training and increased performance. Specifically, our training schema optimizes the parameters of four successive generators such that higher resolution generators exploit the inpainted images produced by lower resolution generators. To restore fine-grained textures, we present a new LBP-based loss function that minimizes the difference between the generated and ground truth textures. We conduct our experiments on Places2 and CelebHQ datasets, and we report qualitative and quantitative results against the state-of-the-art methods. Results show that the computationally efficient model achieves competitive performance.