 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-Driven Intention Decoding: Offline Deep Learning Benchmarking on a Robotic Rover
Feb 23, 2026Brain-computer interfaces (BCIs) provide a hands-free control modality for mobile robotics, yet decoding user intent during real-world navigation remains challenging. This work presents a brain-robot control framework for offline decoding of driving commands during robotic rover operation. A 4WD Rover Pro platform was remotely operated by 12 participants who navigated a predefined route using a joystick, executing the commands forward, reverse, left, right, and stop. Electroencephalogram (EEG) signals were recorded with a 16-channel OpenBCI cap and aligned with motor actions at Delta = 0 ms and future prediction horizons (Delta > 0 ms). After preprocessing, several deep learning models were benchmarked, including convolutional neural networks, recurrent neural networks, and Transformer architectures. ShallowConvNet achieved the highest performance for both action prediction and intent prediction. By combining real-world robotic control with multi-horizon EEG intention decoding, this study introduces a reproducible benchmark and reveals key design insights for predictive deep learning-based BCI systems.
KD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
Dec 17, 2025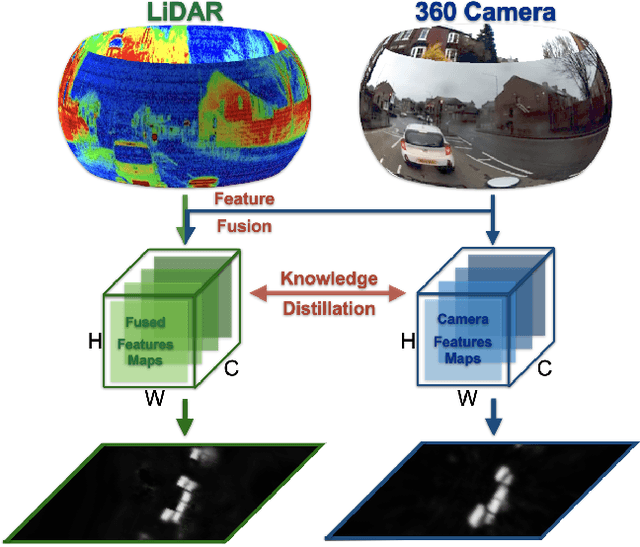
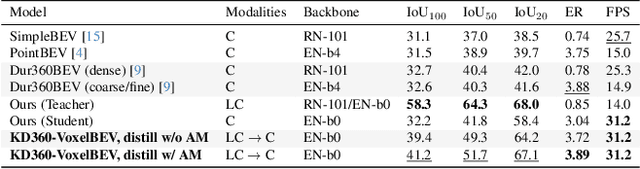


We present the first cross-modality distillation framework specifically tailored for single-panoramic-camera Bird's-Eye-View (BEV) segmentation. Our approach leverages a novel LiDAR image representation fused from range, intensity and ambient channels, together with a voxel-aligned view transformer that preserves spatial fidelity while enabling efficient BEV processing. During training, a high-capacity LiDAR and camera fusion Teacher network extracts both rich spatial and semantic features for cross-modality knowledge distillation into a lightweight Student network that relies solely on a single 360-degree panoramic camera image. Extensive experiments on the Dur360BEV dataset demonstrate that our teacher model significantly outperforms existing camera-based BEV segmentation methods, achieving a 25.6\% IoU improvement. Meanwhile, the distilled Student network attains competitive performance with an 8.5\% IoU gain and state-of-the-art inference speed of 31.2 FPS. Moreover, evaluations on KITTI-360 (two fisheye cameras) confirm that our distillation framework generalises to diverse camera setups, underscoring its feasibility and robustness. This approach reduces sensor complexity and deployment costs while providing a practical solution for efficient, low-cost BEV segmentation in real-world autonomous driving.
DDS-NAS: Dynamic Data Selection within Neural Architecture Search via On-line Hard Example Mining applied to Image Classification
Jun 17, 2025In order to address the scalability challenge within Neural Architecture Search (NAS), we speed up NAS training via dynamic hard example mining within a curriculum learning framework. By utilizing an autoencoder that enforces an image similarity embedding in latent space, we construct an efficient kd-tree structure to order images by furthest neighbour dissimilarity in a low-dimensional embedding. From a given query image from our subsample dataset, we can identify the most dissimilar image within the global dataset in logarithmic time. Via curriculum learning, we then dynamically re-formulate an unbiased subsample dataset for NAS optimisation, upon which the current NAS solution architecture performs poorly. We show that our DDS-NAS framework speeds up gradient-based NAS strategies by up to 27x without loss in performance. By maximising the contribution of each image sample during training, we reduce the duration of a NAS training cycle and the number of iterations required for convergence.
Dream-Box: Object-wise Outlier Generation for Out-of-Distribution Detection
Apr 25, 2025Deep neural networks have demonstrated great generalization capabilities for tasks whose training and test sets are drawn from the same distribution. Nevertheless, out-of-distribution (OOD) detection remains a challenging task that has received significant attention in recent years. Specifically, OOD detection refers to the detection of instances that do not belong to the training distribution, while still having good performance on the in-distribution task (e.g., classification or object detection). Recent work has focused on generating synthetic outliers and using them to train an outlier detector, generally achieving improved OOD detection than traditional OOD methods. In this regard, outliers can be generated either in feature or pixel space. Feature space driven methods have shown strong performance on both the classification and object detection tasks, at the expense that the visualization of training outliers remains unknown, making further analysis on OOD failure modes challenging. On the other hand, pixel space outlier generation techniques enabled by diffusion models have been used for image classification using, providing improved OOD detection performance and outlier visualization, although their adaption to the object detection task is as yet unexplored. We therefore introduce Dream-Box, a method that provides a link to object-wise outlier generation in the pixel space for OOD detection. Specifically, we use diffusion models to generate object-wise outliers that are used to train an object detector for an in-distribution task and OOD detection. Our method achieves comparable performance to previous traditional methods while being the first technique to provide concrete visualization of generated OOD objects.
TFDM: Time-Variant Frequency-Based Point Cloud Diffusion with Mamba
Mar 17, 2025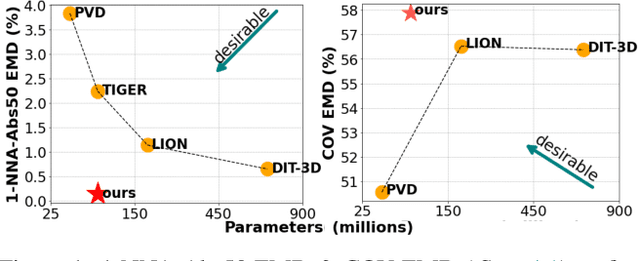



Diffusion models currently demonstrate impressive performance over various generative tasks. Recent work on image diffusion highlights the strong capabilities of Mamba (state space models) due to its efficient handling of long-range dependencies and sequential data modeling. Unfortunately, joint consideration of state space models with 3D point cloud generation remains limited. To harness the powerful capabilities of the Mamba model for 3D point cloud generation, we propose a novel diffusion framework containing dual latent Mamba block (DM-Block) and a time-variant frequency encoder (TF-Encoder). The DM-Block apply a space-filling curve to reorder points into sequences suitable for Mamba state-space modeling, while operating in a latent space to mitigate the computational overhead that arises from direct 3D data processing. Meanwhile, the TF-Encoder takes advantage of the ability of the diffusion model to refine fine details in later recovery stages by prioritizing key points within the U-Net architecture. This frequency-based mechanism ensures enhanced detail quality in the final stages of generation. Experimental results on the ShapeNet-v2 dataset demonstrate that our method achieves state-of-the-art performance (ShapeNet-v2: 0.14\% on 1-NNA-Abs50 EMD and 57.90\% on COV EMD) on certain metrics for specific categories while reducing computational parameters and inference time by up to 10$\times$ and 9$\times$, respectively. Source code is available in Supplementary Materials and will be released upon accpetance.
FEVER-OOD: Free Energy Vulnerability Elimination for Robust Out-of-Distribution Detection
Dec 02, 2024



Modern machine learning models, that excel on computer vision tasks such as classification and object detection, are often overconfident in their predictions for Out-of-Distribution (OOD) examples, resulting in unpredictable behaviour for open-set environments. Recent works have demonstrated that the free energy score is an effective measure of uncertainty for OOD detection given its close relationship to the data distribution. However, despite free energy-based methods representing a significant empirical advance in OOD detection, our theoretical analysis reveals previously unexplored and inherent vulnerabilities within the free energy score formulation such that in-distribution and OOD instances can have distinct feature representations yet identical free energy scores. This phenomenon occurs when the vector direction representing the feature space difference between the in-distribution and OOD sample lies within the null space of the last layer of a neural-based classifier. To mitigate these issues, we explore lower-dimensional feature spaces to reduce the null space footprint and introduce novel regularisation to maximize the least singular value of the final linear layer, hence enhancing inter-sample free energy separation. We refer to these techniques as Free Energy Vulnerability Elimination for Robust Out-of-Distribution Detection (FEVER-OOD). Our experiments show that FEVER-OOD techniques achieve state of the art OOD detection in Imagenet-100, with average OOD false positive rate (at 95% true positive rate) of 35.83% when used with the baseline Dream-OOD model.
TraIL-Det: Transformation-Invariant Local Feature Networks for 3D LiDAR Object Detection with Unsupervised Pre-Training
Aug 25, 2024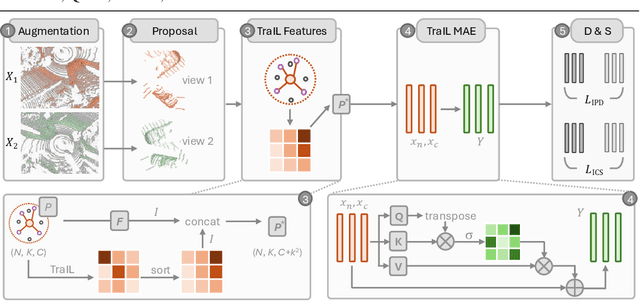
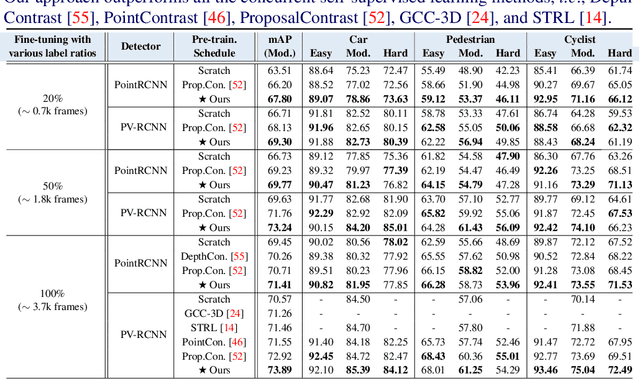
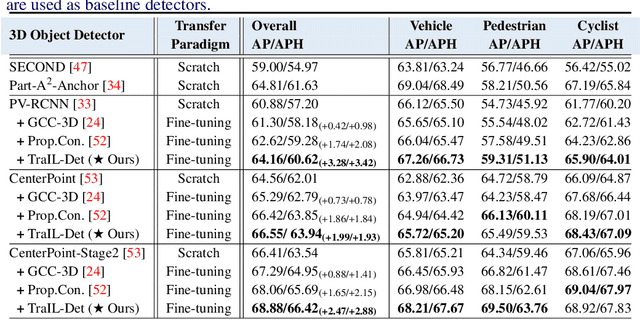

3D point clouds are essential for perceiving outdoor scenes, especially within the realm of autonomous driving. Recent advances in 3D LiDAR Object Detection focus primarily on the spatial positioning and distribution of points to ensure accurate detection. However, despite their robust performance in variable conditions, these methods are hindered by their sole reliance on coordinates and point intensity, resulting in inadequate isometric invariance and suboptimal detection outcomes. To tackle this challenge, our work introduces Transformation-Invariant Local (TraIL) features and the associated TraIL-Det architecture. Our TraIL features exhibit rigid transformation invariance and effectively adapt to variations in point density, with a design focus on capturing the localized geometry of neighboring structures. They utilize the inherent isotropic radiation of LiDAR to enhance local representation, improve computational efficiency, and boost detection performance. To effectively process the geometric relations among points within each proposal, we propose a Multi-head self-Attention Encoder (MAE) with asymmetric geometric features to encode high-dimensional TraIL features into manageable representations. Our method outperforms contemporary self-supervised 3D object detection approaches in terms of mAP on KITTI (67.8, 20% label, moderate) and Waymo (68.9, 20% label, moderate) datasets under various label ratios (20%, 50%, and 100%).
* BMVC 2024; 15 pages, 3 figures, 3 tables; Code at https://github.com/l1997i/rapid_seg
Towards Open-World Object-based Anomaly Detection via Self-Supervised Outlier Synthesis
Jul 22, 2024Object detection is a pivotal task in computer vision that has received significant attention in previous years. Nonetheless, the capability of a detector to localise objects out of the training distribution remains unexplored. Whilst recent approaches in object-level out-of-distribution (OoD) detection heavily rely on class labels, such approaches contradict truly open-world scenarios where the class distribution is often unknown. In this context, anomaly detection focuses on detecting unseen instances rather than classifying detections as OoD. This work aims to bridge this gap by leveraging an open-world object detector and an OoD detector via virtual outlier synthesis. This is achieved by using the detector backbone features to first learn object pseudo-classes via self-supervision. These pseudo-classes serve as the basis for class-conditional virtual outlier sampling of anomalous features that are classified by an OoD head. Our approach empowers our overall object detector architecture to learn anomaly-aware feature representations without relying on class labels, hence enabling truly open-world object anomaly detection. Empirical validation of our approach demonstrates its effectiveness across diverse datasets encompassing various imaging modalities (visible, infrared, and X-ray). Moreover, our method establishes state-of-the-art performance on object-level anomaly detection, achieving an average recall score improvement of over 5.4% for natural images and 23.5% for a security X-ray dataset compared to the current approaches. In addition, our method detects anomalies in datasets where current approaches fail. Code available at https://github.com/KostadinovShalon/oln-ssos.
RAPiD-Seg: Range-Aware Pointwise Distance Distribution Networks for 3D LiDAR Segmentation
Jul 14, 20243D point clouds play a pivotal role in outdoor scene perception, especially in the context of autonomous driving. Recent advancements in 3D LiDAR segmentation often focus intensely on the spatial positioning and distribution of points for accurate segmentation. However, these methods, while robust in variable conditions, encounter challenges due to sole reliance on coordinates and point intensity, leading to poor isometric invariance and suboptimal segmentation. To tackle this challenge, our work introduces Range-Aware Pointwise Distance Distribution (RAPiD) features and the associated RAPiD-Seg architecture. Our RAPiD features exhibit rigid transformation invariance and effectively adapt to variations in point density, with a design focus on capturing the localized geometry of neighboring structures. They utilize inherent LiDAR isotropic radiation and semantic categorization for enhanced local representation and computational efficiency, while incorporating a 4D distance metric that integrates geometric and surface material reflectivity for improved semantic segmentation. To effectively embed high-dimensional RAPiD features, we propose a double-nested autoencoder structure with a novel class-aware embedding objective to encode high-dimensional features into manageable voxel-wise embeddings. Additionally, we propose RAPiD-Seg which incorporates a channel-wise attention fusion and two effective RAPiD-Seg variants, further optimizing the embedding for enhanced performance and generalization. Our method outperforms contemporary LiDAR segmentation work in terms of mIoU on SemanticKITTI (76.1) and nuScenes (83.6) datasets.
* ECCV 2024; 18 pages, 6 figures, 7 tables; Code at https://github.com/l1997i/rapid_seg
DurLAR: A High-fidelity 128-channel LiDAR Dataset with Panoramic Ambient and Reflectivity Imagery for Multi-modal Autonomous Driving Applications
Jun 14, 2024



We present DurLAR, a high-fidelity 128-channel 3D LiDAR dataset with panoramic ambient (near infrared) and reflectivity imagery, as well as a sample benchmark task using depth estimation for autonomous driving applications. Our driving platform is equipped with a high resolution 128 channel LiDAR, a 2MPix stereo camera, a lux meter and a GNSS/INS system. Ambient and reflectivity images are made available along with the LiDAR point clouds to facilitate multi-modal use of concurrent ambient and reflectivity scene information. Leveraging DurLAR, with a resolution exceeding that of prior benchmarks, we consider the task of monocular depth estimation and use this increased availability of higher resolution, yet sparse ground truth scene depth information to propose a novel joint supervised/self-supervised loss formulation. We compare performance over both our new DurLAR dataset, the established KITTI benchmark and the Cityscapes dataset. Our evaluation shows our joint use supervised and self-supervised loss terms, enabled via the superior ground truth resolution and availability within DurLAR improves the quantitative and qualitative performance of leading contemporary monocular depth estimation approaches (RMSE=3.639, Sq Rel=0.936).
* Accepted by 3DV 2021; 13 pages, 14 figures; Dataset at https://github.com/l1997i/durlar