 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTE: Virtual Graph Trajectory Expert Router for Pedestrian Trajectory Prediction
Nov 15, 2025Pedestrian trajectory prediction is critical for ensuring safety in autonomous driving, surveillance systems, and urban planning applications. While early approaches primarily focus on one-hop pairwise relationships, recent studies attempt to capture high-order interactions by stacking multiple Graph Neural Network (GNN) layers. However, these approaches face a fundamental trade-off: insufficient layers may lead to under-reaching problems that limit the model's receptive field, while excessive depth can result in prohibitive computational costs. We argue that an effective model should be capable of adaptively modeling both explicit one-hop interactions and implicit high-order dependencies, rather than relying solely on architectural depth. To this end, we propose ViTE (Virtual graph Trajectory Expert router), a novel framework for pedestrian trajectory prediction. ViTE consists of two key modules: a Virtual Graph that introduces dynamic virtual nodes to model long-range and high-order interactions without deep GNN stacks, and an Expert Router that adaptively selects interaction experts based on social context using a Mixture-of-Experts design. This combination enables flexible and scalable reasoning across varying interaction patterns. Experiments on three benchmarks (ETH/UCY, NBA, and SDD) demonstrate that our method consistently achieves state-of-the-art performance, validating both its effectiveness and practical efficiency.
Unified Spatial-Temporal Edge-Enhanced Graph Networks for Pedestrian Trajectory Prediction
Feb 04, 2025Pedestrian trajectory prediction aims to forecast future movements based on historical paths. Spatial-temporal (ST) methods often separately model spatial interactions among pedestrians and temporal dependencies of individuals. They overlook the direct impacts of interactions among different pedestrians across various time steps (i.e., high-order cross-time interactions). This limits their ability to capture ST inter-dependencies and hinders prediction performance. To address these limitations, we propose UniEdge with three major designs. Firstly, we introduce a unified ST graph data structure that simplifies high-order cross-time interactions into first-order relationships, enabling the learning of ST inter-dependencies in a single step. This avoids the information loss caused by multi-step aggregation. Secondly, traditional GNNs focus on aggregating pedestrian node features, neglecting the propagation of implicit interaction patterns encoded in edge features. We propose the Edge-to-Edge-Node-to-Node Graph Convolution (E2E-N2N-GCN), a novel dual-graph network that jointly models explicit N2N social interactions among pedestrians and implicit E2E influence propagation across these interaction patterns. Finally, to overcome the limited receptive fields and challenges in capturing long-range dependencies of auto-regressive architectures, we introduce a transformer encoder-based predictor that enables global modeling of temporal correlation. UniEdge outperforms state-of-the-arts on multiple datasets, including ETH, UCY, and SDD.
TraIL-Det: Transformation-Invariant Local Feature Networks for 3D LiDAR Object Detection with Unsupervised Pre-Training
Aug 25, 2024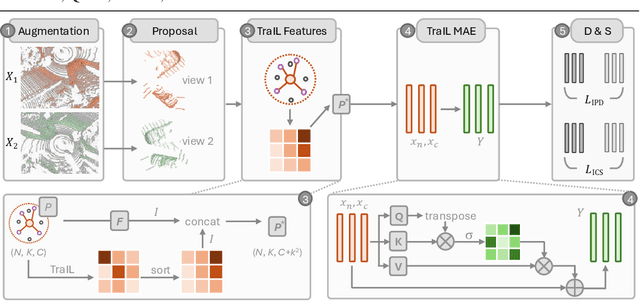
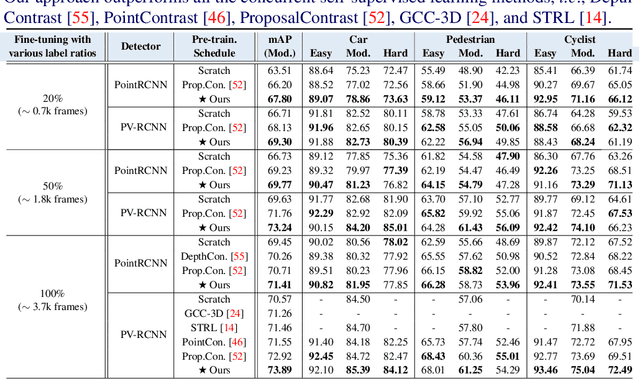
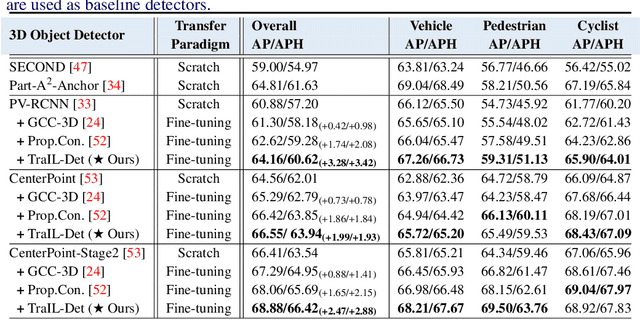

3D point clouds are essential for perceiving outdoor scenes, especially within the realm of autonomous driving. Recent advances in 3D LiDAR Object Detection focus primarily on the spatial positioning and distribution of points to ensure accurate detection. However, despite their robust performance in variable conditions, these methods are hindered by their sole reliance on coordinates and point intensity, resulting in inadequate isometric invariance and suboptimal detection outcomes. To tackle this challenge, our work introduces Transformation-Invariant Local (TraIL) features and the associated TraIL-Det architecture. Our TraIL features exhibit rigid transformation invariance and effectively adapt to variations in point density, with a design focus on capturing the localized geometry of neighboring structures. They utilize the inherent isotropic radiation of LiDAR to enhance local representation, improve computational efficiency, and boost detection performance. To effectively process the geometric relations among points within each proposal, we propose a Multi-head self-Attention Encoder (MAE) with asymmetric geometric features to encode high-dimensional TraIL features into manageable representations. Our method outperforms contemporary self-supervised 3D object detection approaches in terms of mAP on KITTI (67.8, 20% label, moderate) and Waymo (68.9, 20% label, moderate) datasets under various label ratios (20%, 50%, and 100%).
* BMVC 2024; 15 pages, 3 figures, 3 tables; Code at https://github.com/l1997i/rapid_seg
From Category to Scenery: An End-to-End Framework for Multi-Person Human-Object Interaction Recognition in Videos
Jul 01, 2024Video-based Human-Object Interaction (HOI) recognition explores the intricate dynamics between humans and objects, which are essential for a comprehensive understanding of human behavior and intentions. While previous work has made significant strides, effectively integrating geometric and visual features to model dynamic relationships between humans and objects in a graph framework remains a challenge. In this work, we propose a novel end-to-end category to scenery framework, CATS, starting by generating geometric features for various categories through graphs respectively, then fusing them with corresponding visual features. Subsequently, we construct a scenery interactive graph with these enhanced geometric-visual features as nodes to learn the relationships among human and object categories. This methodological advance facilitates a deeper, more structured comprehension of interactions, bridging category-specific insights with broad scenery dynamics. Our method demonstrates state-of-the-art performance on two pivotal HOI benchmarks, including the MPHOI-72 dataset for multi-person HOIs and the single-person HOI CAD-120 dataset.
Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos
Jul 19, 2022



Human-Object Interaction (HOI) recognition in videos is important for analyzing human activity. Most existing work focusing on visual features usually suffer from occlusion in the real-world scenarios. Such a problem will be further complicated when multiple people and objects are involved in HOIs. Consider that geometric features such as human pose and object position provide meaningful information to understand HOIs, we argue to combine the benefits of both visual and geometric features in HOI recognition, and propose a novel Two-level Geometric feature-informed Graph Convolutional Network (2G-GCN). The geometric-level graph models the interdependency between geometric features of humans and objects, while the fusion-level graph further fuses them with visual features of humans and objects. To demonstrate the novelty and effectiveness of our method in challenging scenarios, we propose a new multi-person HOI dataset (MPHOI-72). Extensive experiments on MPHOI-72 (multi-person HOI), CAD-120 (single-human HOI) and Bimanual Actions (two-hand HOI) datasets demonstrate our superior performance compared to state-of-the-arts.