 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rigid 3D Shape Correspondences: From Foundations to Open Challenges and Opportunities
Apr 01, 2026Estimating correspondences between deformed shape instances is a long-standing problem in computer graphics; numerous applications, from texture transfer to statistical modelling, rely on recovering an accurate correspondence map. Many methods have thus been proposed to tackle this challenging problem from varying perspectives, depending on the downstream application. This state-of-the-art report is geared towards researchers, practitioners, and students seeking to understand recent trends and advances in the field. We categorise developments into three paradigms: spectral methods based on functional maps, combinatorial formulations that impose discrete constraints, and deformation-based methods that directly recover a global alignment. Each school of thought offers different advantages and disadvantages, which we discuss throughout the report. Meanwhile, we highlight the latest developments in each area and suggest new potential research directions. Finally, we provide an overview of emerging challenges and opportunities in this growing field, including the recent use of vision foundation models for zero-shot correspondence and the particularly challenging task of matching partial shapes.
Understanding and Supporting Formal Email Exchange by Answering AI-Generated Questions
Feb 06, 2025



Replying to formal emails is time-consuming and cognitively demanding, as it requires polite phrasing and ensuring an adequate response to the sender's demands. Although systems with Large Language Models (LLM) were designed to simplify the email replying process, users still needed to provide detailed prompts to obtain the expected output. Therefore, we proposed and evaluated an LLM-powered question-and-answer (QA)-based approach for users to reply to emails by answering a set of simple and short questions generated from the incoming email. We developed a prototype system, ResQ, and conducted controlled and field experiments with 12 and 8 participants. Our results demonstrated that QA-based approach improves the efficiency of replying to emails and reduces workload while maintaining email quality compared to a conventional prompt-based approach that requires users to craft appropriate prompts to obtain email drafts. We discuss how QA-based approach influences the email reply process and interpersonal relationship dynamics, as well as the opportunities and challenges associated with using a QA-based approach in AI-mediated communication.
SyncViolinist: Music-Oriented Violin Motion Generation Based on Bowing and Fingering
Dec 11, 2024



Automatically generating realistic musical performance motion can greatly enhance digital media production, often involving collaboration between professionals and musicians. However, capturing the intricate body, hand, and finger movements required for accurate musical performances is challenging. Existing methods often fall short due to the complex mapping between audio and motion, typically requiring additional inputs like scores or MIDI data. In this work, we present SyncViolinist, a multi-stage end-to-end framework that generates synchronized violin performance motion solely from audio input. Our method overcomes the challenge of capturing both global and fine-grained performance features through two key modules: a bowing/fingering module and a motion generation module. The bowing/fingering module extracts detailed playing information from the audio, which the motion generation module uses to create precise, coordinated body motions reflecting the temporal granularity and nature of the violin performance. We demonstrate the effectiveness of SyncViolinist with significantly improved qualitative and quantitative results from unseen violin performance audio, outperforming state-of-the-art methods. Extensive subjective evaluations involving professional violinists further validate our approach. The code and dataset are available at https://github.com/Kakanat/SyncViolinist.
Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection
Sep 13, 2024Are general-purpose visual representations acquired solely from synthetic data useful for detecting fake images? In this work, we show the effectiveness of synthetic data-driven representations for synthetic image detection. Upon analysis, we find that vision transformers trained by the latest visual representation learners with synthetic data can effectively distinguish fake from real images without seeing any real images during pre-training. Notably, using SynCLR as the backbone in a state-of-the-art detection method demonstrates a performance improvement of +10.32 mAP and +4.73% accuracy over the widely used CLIP, when tested on previously unseen GAN models. Code is available at https://github.com/cvpaperchallenge/detect-fake-with-fake.
Monte Carlo Path Tracing and Statistical Event Detection for Event Camera Simulation
Aug 15, 2024

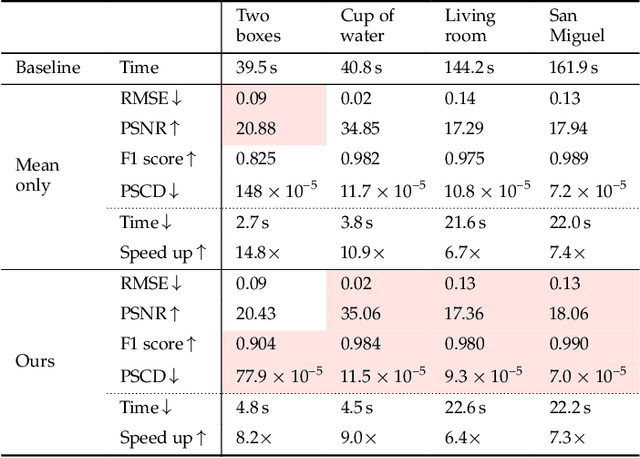
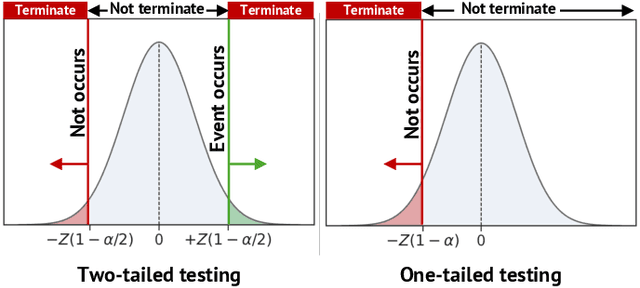
This paper presents a novel event camera simulation system fully based on physically based Monte Carlo path tracing with adaptive path sampling. The adaptive sampling performed in the proposed method is based on a statistical technique, hypothesis testing for the hypothesis whether the difference of logarithmic luminances at two distant periods is significantly larger than a predefined event threshold. To this end, our rendering system collects logarithmic luminances rather than raw luminance in contrast to the conventional rendering system imitating conventional RGB cameras. Then, based on the central limit theorem, we reasonably assume that the distribution of the population mean of logarithmic luminance can be modeled as a normal distribution, allowing us to model the distribution of the difference of logarithmic luminance as a normal distribution. Then, using Student's t-test, we can test the hypothesis and determine whether to discard the null hypothesis for event non-occurrence. When we sample a sufficiently large number of path samples to satisfy the central limit theorem and obtain a clean set of events, our method achieves significant speed up compared to a simple approach of sampling paths uniformly at every pixel. To our knowledge, we are the first to simulate the behavior of event cameras in a physically accurate manner using an adaptive sampling technique in Monte Carlo path tracing, and we believe this study will contribute to the development of computer vision applications using event cameras.
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
May 11, 2024

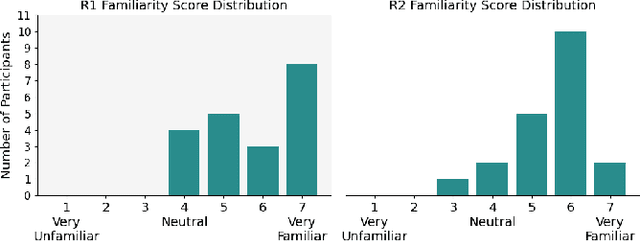
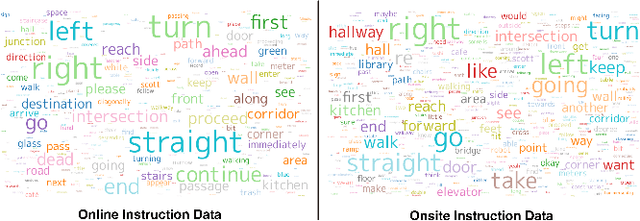
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.
Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability
Sep 30, 2023



Language learners should regularly engage in reading challenging materials as part of their study routine. Nevertheless, constantly referring to dictionaries is time-consuming and distracting. This paper presents a novel gaze-driven sentence simplification system designed to enhance reading comprehension while maintaining their focus on the content. Our system incorporates machine learning models tailored to individual learners, combining eye gaze features and linguistic features to assess sentence comprehension. When the system identifies comprehension difficulties, it provides simplified versions by replacing complex vocabulary and grammar with simpler alternatives via GPT-3.5. We conducted an experiment with 19 English learners, collecting data on their eye movements while reading English text. The results demonstrated that our system is capable of accurately estimating sentence-level comprehension. Additionally, we found that GPT-3.5 simplification improved readability in terms of traditional readability metrics and individual word difficulty, paraphrasing across different linguistic levels.
Pointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue
Sep 19, 2023



Effective communication between humans and intelligent agents has promising applications for solving complex problems. One such approach is visual dialogue, which leverages multimodal context to assist humans. However, real-world scenarios occasionally involve human mistakes, which can cause intelligent agents to fail. While most prior research assumes perfect answers from human interlocutors, we focus on a setting where the agent points out unintentional mistakes for the interlocutor to review, better reflecting real-world situations. In this paper, we show that human answer mistakes depend on question type and QA turn in the visual dialogue by analyzing a previously unused data collection of human mistakes. We demonstrate the effectiveness of those factors for the model's accuracy in a pointing-human-mistake task through experiments using a simple MLP model and a Visual Language Model.
Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation
Aug 24, 2023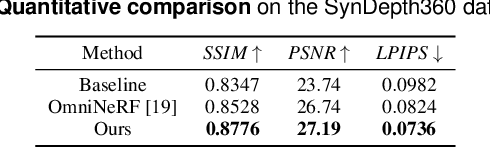



Pre-captured immersive environments using omnidirectional cameras provide a wide range of virtual reality applications. Previous research has shown that manipulating the eye height in egocentric virtual environments can significantly affect distance perception and immersion. However, the influence of eye height in pre-captured real environments has received less attention due to the difficulty of altering the perspective after finishing the capture process. To explore this influence, we first propose a pilot study that captures real environments with multiple eye heights and asks participants to judge the egocentric distances and immersion. If a significant influence is confirmed, an effective image-based approach to adapt pre-captured real-world environments to the user's eye height would be desirable. Motivated by the study, we propose a learning-based approach for synthesizing novel views for omnidirectional images with altered eye heights. This approach employs a multitask architecture that learns depth and semantic segmentation in two formats, and generates high-quality depth and semantic segmentation to facilitate the inpainting stage. With the improved omnidirectional-aware layered depth image, our approach synthesizes natural and realistic visuals for eye height adaptation. Quantitative and qualitative evaluation shows favorable results against state-of-the-art methods, and an extensive user study verifies improved perception and immersion for pre-captured real-world environments.
Audio-Visual Speech Enhancement With Selective Off-Screen Speech Extraction
Jun 10, 2023



This paper describes an audio-visual speech enhancement (AV-SE) method that estimates from noisy input audio a mixture of the speech of the speaker appearing in an input video (on-screen target speech) and of a selected speaker not appearing in the video (off-screen target speech). Although conventional AV-SE methods have suppressed all off-screen sounds, it is necessary to listen to a specific pre-known speaker's speech (e.g., family member's voice and announcements in stations) in future applications of AV-SE (e.g., hearing aids), even when users' sight does not capture the speaker. To overcome this limitation, we extract a visual clue for the on-screen target speech from the input video and a voiceprint clue for the off-screen one from a pre-recorded speech of the speaker. Two clues from different domains are integrated as an audio-visual clue, and the proposed model directly estimates the target mixture. To improve the estimation accuracy, we introduce a temporal attention mechanism for the voiceprint clue and propose a training strategy called the muting strategy. Experimental results show that our method outperforms a baseline method that uses the state-of-the-art AV-SE and speaker extraction methods individually in terms of estimation accuracy and computational efficiency.