 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
Aug 06, 2025Prior work synthesizes tool-use LLM datasets by first generating a user query, followed by complex tool-use annotations like DFS. This leads to inevitable annotation failures and low efficiency in data generation. We introduce ToolGrad, an agentic framework that inverts this paradigm. ToolGrad first constructs valid tool-use chains through an iterative process guided by textual "gradients", and then synthesizes corresponding user queries. This "answer-first" approach led to ToolGrad-5k, a dataset generated with more complex tool use, lower cost, and 100% pass rate. Experiments show that models trained on ToolGrad-5k outperform those on expensive baseline datasets and proprietary LLMs, even on OOD benchmarks.
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
May 11, 2024

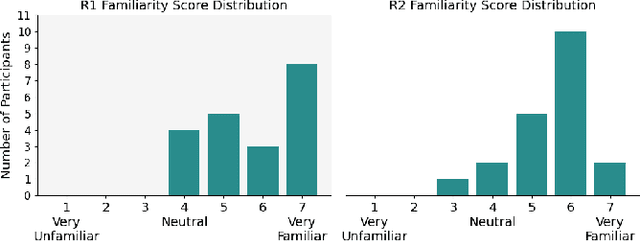
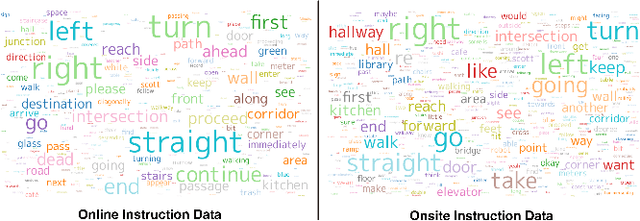
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Jan 18, 2024
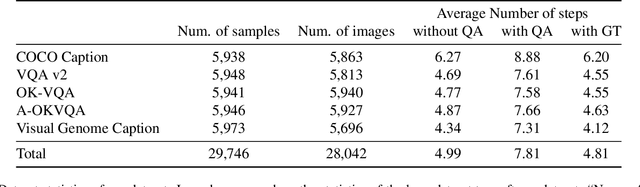


The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to imbue an LMM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. Our method comprises the development of a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. We designed an LMM, which has high capabilities on region awareness to address the intricate requirements of image-text alignment. The model undergoes a three-stage training phase, starting with large-scale image-text alignment using a large-scale datasets, followed by instruction tuning, and fine-tuning with a focus on chain-of-thought reasoning. The results demonstrate a stride toward a more robust, accurate, and interpretable LMM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.
Learning by Asking Questions for Knowledge-based Novel Object Recognition
Oct 12, 2022


In real-world object recognition, there are numerous object classes to be recognized. Conventional image recognition based on supervised learning can only recognize object classes that exist in the training data, and thus has limited applicability in the real world. On the other hand, humans can recognize novel objects by asking questions and acquiring knowledge about them. Inspired by this, we study a framework for acquiring external knowledge through question generation that would help the model instantly recognize novel objects. Our pipeline consists of two components: the Object Classifier, which performs knowledge-based object recognition, and the Question Generator, which generates knowledge-aware questions to acquire novel knowledge. We also propose a question generation strategy based on the confidence of the knowledge-aware prediction of the Object Classifier. To train the Question Generator, we construct a dataset that contains knowledge-aware questions about objects in the images. Our experiments show that the proposed pipeline effectively acquires knowledge about novel objects compared to several baselines.
K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition
Mar 15, 2022
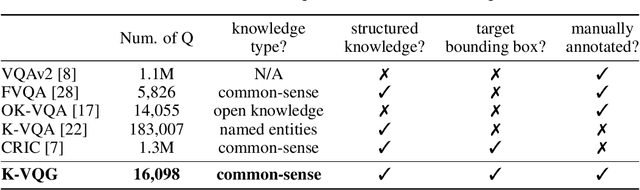

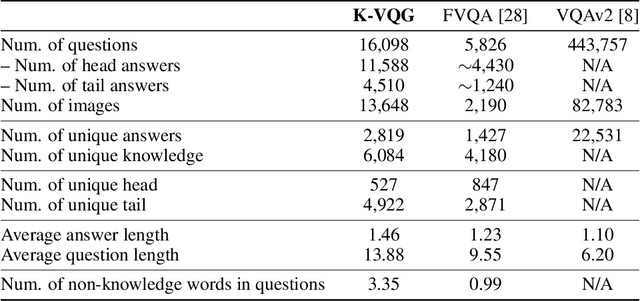
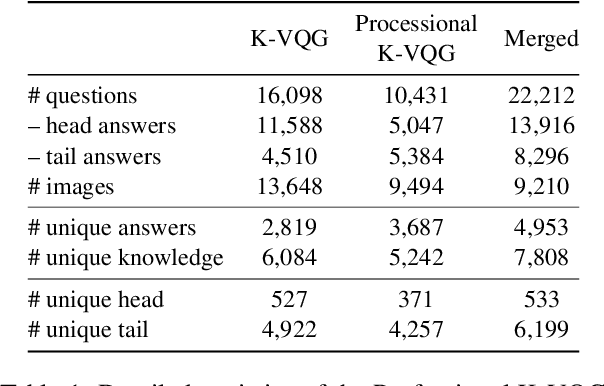
Visual Question Generation (VQG) is a task to generate questions from images. When humans ask questions about an image, their goal is often to acquire some new knowledge. However, existing studies on VQG have mainly addressed question generation from answers or question categories, overlooking the objectives of knowledge acquisition. To introduce a knowledge acquisition perspective into VQG, we constructed a novel knowledge-aware VQG dataset called K-VQG. This is the first large, humanly annotated dataset in which questions regarding images are tied to structured knowledge. We also developed a new VQG model that can encode and use knowledge as the target for a question. The experiment results show that our model outperforms existing models on the K-VQG dataset.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Feb 15, 2022
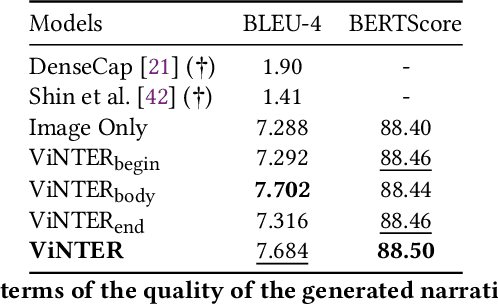
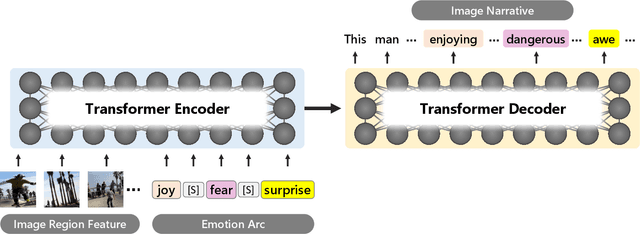
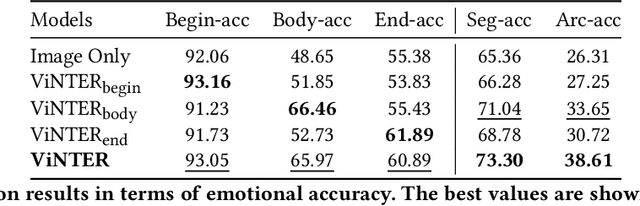
Image narrative generation describes the creation of stories regarding the content of image data from a subjective viewpoint. Given the importance of the subjective feelings of writers, characters, and readers in storytelling, image narrative generation methods must consider human emotion, which is their major difference from descriptive caption generation tasks. The development of automated methods to generate story-like text associated with images may be considered to be of considerable social significance, because stories serve essential functions both as entertainment and also for many practical purposes such as education and advertising. In this study, we propose a model called ViNTER (Visual Narrative Transformer with Emotion arc Representation) to generate image narratives that focus on time series representing varying emotions as "emotion arcs," to take advantage of recent advances in multimodal Transformer-based pre-trained models. We present experimental results of both manual and automatic evaluations, which demonstrate the effectiveness of the proposed emotion-aware approach to image narrative generation.
Unsupervised Keyword Extraction for Full-sentence VQA
Nov 23, 2019
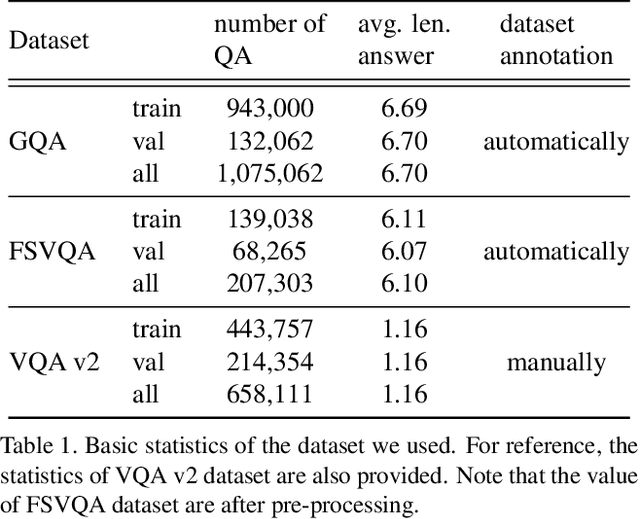
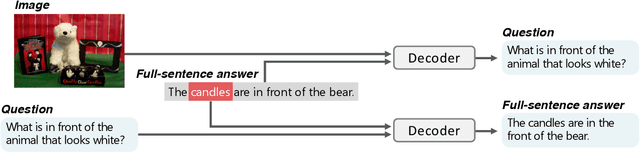

In existing studies on Visual Question Answering (VQA), which aims to train an intelligent system to be able to answer questions about images, the answers corresponding to the questions consists of short, almost single words. However, considering the natural conversation with humans, the answers would more likely to be sentences, rather than single words. In such a situation, the system needs to focus on a keyword, i.e., the most important word in the sentence, to answer the question. Therefore, we have proposed a novel keyword extraction method for VQA. Because collecting keywords and full-sentence annotations for VQA can be highly costly, we perform the keyword extraction in an unsupervised manner. Our key insight is that the full-sentence answer can be decomposed into two parts: the part contains new information for the question and the part only contains information already included in the question. Since the keyword is considered as the part which contains new information as the answer, we need to identify which words in the full-sentence answer are the part of new information and which words are not. To ensure such decomposition, we extracted two features from the full-sentence answers, and designed discriminative decoders to make each feature to include the information of the question and answers respectively. We conducted experiments on existing VQA datasets, which contains full-sentence annotations, and show that our proposed model can correctly extract the keyword without any keyword annotations.
Interactive Video Retrieval with Dialog
May 07, 2019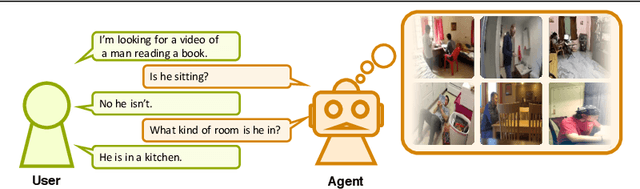

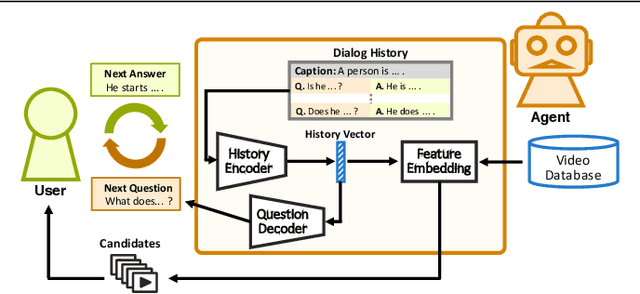

Now that everyone can easily record videos, the quantity of which is continuously increasing, research on methods for improved video retrieval is important in the contemporary world. In cases where target videos are to be identified within a large collection gathered by individuals, the appropriate information must be obtained to retrieve the correct video within a large number of similar items in the target database. The purpose of this research is to retrieve target videos in such cases by introducing an interaction, or a dialog, between the system and the user. We propose a system to retrieve videos by asking questions about the content of the videos and leveraging the user's responses to the questions. Additionally, we confirmed the usefulness of the proposed system through experiments using the dataset called AVSD which includes videos and dialogs about the videos.
Visual Question Generation for Class Acquisition of Unknown Objects
Aug 06, 2018

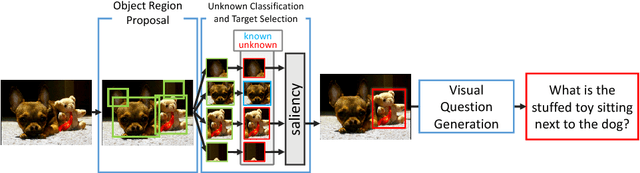
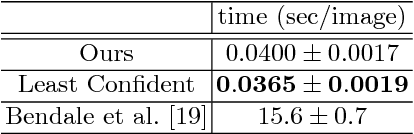
Traditional image recognition methods only consider objects belonging to already learned classes. However, since training a recognition model with every object class in the world is unfeasible, a way of getting information on unknown objects (i.e., objects whose class has not been learned) is necessary. A way for an image recognition system to learn new classes could be asking a human about objects that are unknown. In this paper, we propose a method for generating questions about unknown objects in an image, as means to get information about classes that have not been learned. Our method consists of a module for proposing objects, a module for identifying unknown objects, and a module for generating questions about unknown objects. The experimental results via human evaluation show that our method can successfully get information about unknown objects in an image dataset. Our code and dataset are available at https://github.com/mil-tokyo/vqg-unknown.