 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and Reconstruction
Dec 29, 2025We introduce RealX3D, a real-capture benchmark for multi-view visual restoration and 3D reconstruction under diverse physical degradations. RealX3D groups corruptions into four families, including illumination, scattering, occlusion, and blurring, and captures each at multiple severity levels using a unified acquisition protocol that yields pixel-aligned LQ/GT views. Each scene includes high-resolution capture, RAW images, and dense laser scans, from which we derive world-scale meshes and metric depth. Benchmarking a broad range of optimization-based and feed-forward methods shows substantial degradation in reconstruction quality under physical corruptions, underscoring the fragility of current multi-view pipelines in real-world challenging environments.
Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Jan 18, 2024
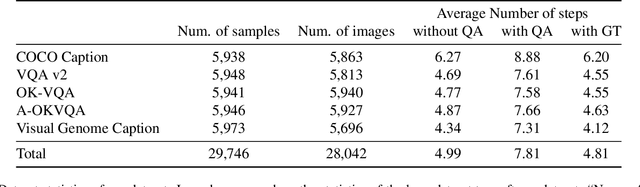


The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to imbue an LMM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. Our method comprises the development of a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. We designed an LMM, which has high capabilities on region awareness to address the intricate requirements of image-text alignment. The model undergoes a three-stage training phase, starting with large-scale image-text alignment using a large-scale datasets, followed by instruction tuning, and fine-tuning with a focus on chain-of-thought reasoning. The results demonstrate a stride toward a more robust, accurate, and interpretable LMM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.
HiPerformer: Hierarchically Permutation-Equivariant Transformer for Time Series Forecasting
May 14, 2023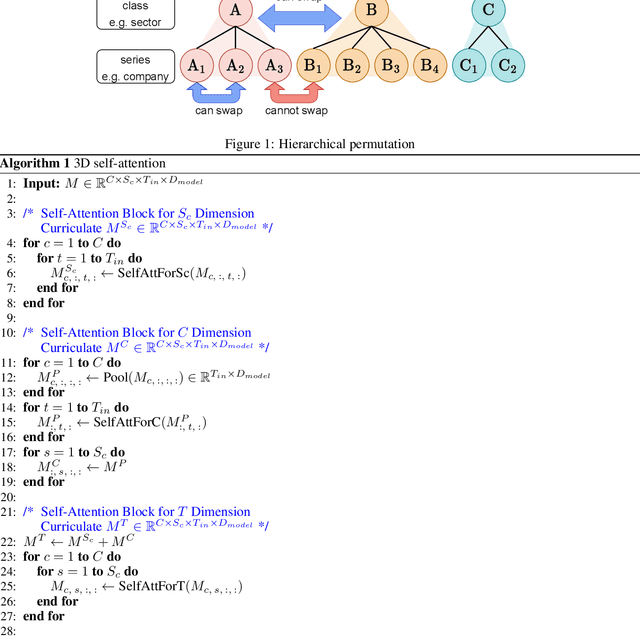

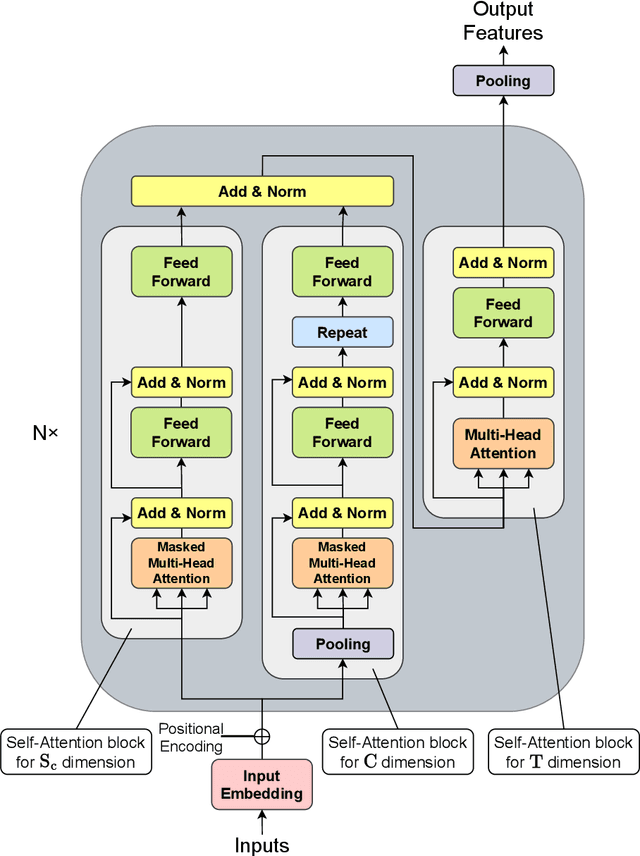
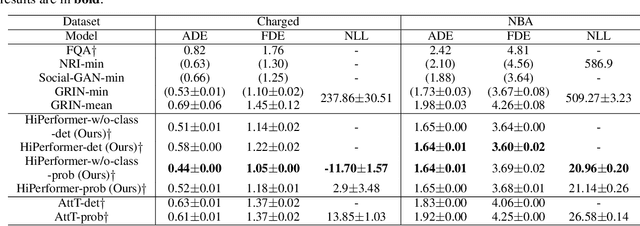
It is imperative to discern the relationships between multiple time series for accurate forecasting. In particular, for stock prices, components are often divided into groups with the same characteristics, and a model that extracts relationships consistent with this group structure should be effective. Thus, we propose the concept of hierarchical permutation-equivariance, focusing on index swapping of components within and among groups, to design a model that considers this group structure. When the prediction model has hierarchical permutation-equivariance, the prediction is consistent with the group relationships of the components. Therefore, we propose a hierarchically permutation-equivariant model that considers both the relationship among components in the same group and the relationship among groups. The experiments conducted on real-world data demonstrate that the proposed method outperforms existing state-of-the-art methods.