 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved 3D Scene Stylization via Text-Guided Generative Image Editing with Region-Based Control
Sep 04, 2025Recent advances in text-driven 3D scene editing and stylization, which leverage the powerful capabilities of 2D generative models, have demonstrated promising outcomes. However, challenges remain in ensuring high-quality stylization and view consistency simultaneously. Moreover, applying style consistently to different regions or objects in the scene with semantic correspondence is a challenging task. To address these limitations, we introduce techniques that enhance the quality of 3D stylization while maintaining view consistency and providing optional region-controlled style transfer. Our method achieves stylization by re-training an initial 3D representation using stylized multi-view 2D images of the source views. Therefore, ensuring both style consistency and view consistency of stylized multi-view images is crucial. We achieve this by extending the style-aligned depth-conditioned view generation framework, replacing the fully shared attention mechanism with a single reference-based attention-sharing mechanism, which effectively aligns style across different viewpoints. Additionally, inspired by recent 3D inpainting methods, we utilize a grid of multiple depth maps as a single-image reference to further strengthen view consistency among stylized images. Finally, we propose Multi-Region Importance-Weighted Sliced Wasserstein Distance Loss, allowing styles to be applied to distinct image regions using segmentation masks from off-the-shelf models. We demonstrate that this optional feature enhances the faithfulness of style transfer and enables the mixing of different styles across distinct regions of the scene. Experimental evaluations, both qualitative and quantitative, demonstrate that our pipeline effectively improves the results of text-driven 3D stylization.
Gradual Transition from Bellman Optimality Operator to Bellman Operator in Online Reinforcement Learning
Jun 06, 2025For continuous action spaces, actor-critic methods are widely used in online reinforcement learning (RL). However, unlike RL algorithms for discrete actions, which generally model the optimal value function using the Bellman optimality operator, RL algorithms for continuous actions typically model Q-values for the current policy using the Bellman operator. These algorithms for continuous actions rely exclusively on policy updates for improvement, which often results in low sample efficiency. This study examines the effectiveness of incorporating the Bellman optimality operator into actor-critic frameworks. Experiments in a simple environment show that modeling optimal values accelerates learning but leads to overestimation bias. To address this, we propose an annealing approach that gradually transitions from the Bellman optimality operator to the Bellman operator, thereby accelerating learning while mitigating bias. Our method, combined with TD3 and SAC, significantly outperforms existing approaches across various locomotion and manipulation tasks, demonstrating improved performance and robustness to hyperparameters related to optimality.
Style-NeRF2NeRF: 3D Style Transfer From Style-Aligned Multi-View Images
Jun 19, 2024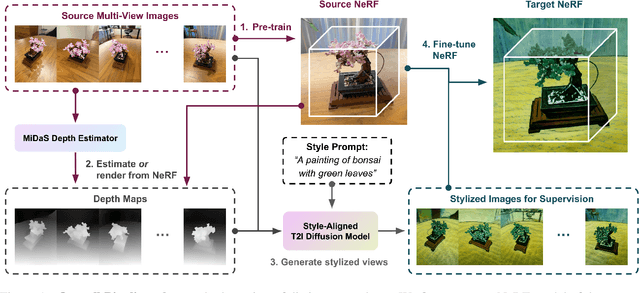


We propose a simple yet effective pipeline for stylizing a 3D scene, harnessing the power of 2D image diffusion models. Given a NeRF model reconstructed from a set of multi-view images, we perform 3D style transfer by refining the source NeRF model using stylized images generated by a style-aligned image-to-image diffusion model. Given a target style prompt, we first generate perceptually similar multi-view images by leveraging a depth-conditioned diffusion model with an attention-sharing mechanism. Next, based on the stylized multi-view images, we propose to guide the style transfer process with the sliced Wasserstein loss based on the feature maps extracted from a pre-trained CNN model. Our pipeline consists of decoupled steps, allowing users to test various prompt ideas and preview the stylized 3D result before proceeding to the NeRF fine-tuning stage. We demonstrate that our method can transfer diverse artistic styles to real-world 3D scenes with competitive quality.
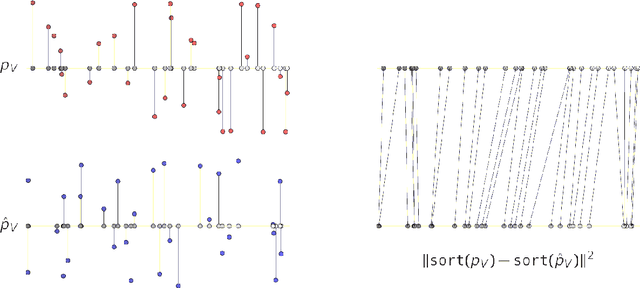
Stabilizing Extreme Q-learning by Maclaurin Expansion
Jun 07, 2024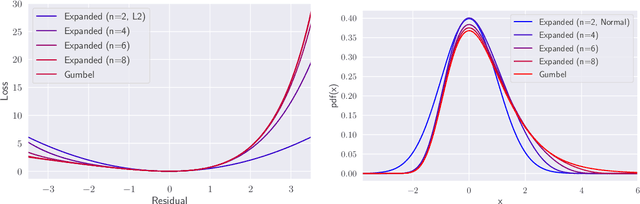
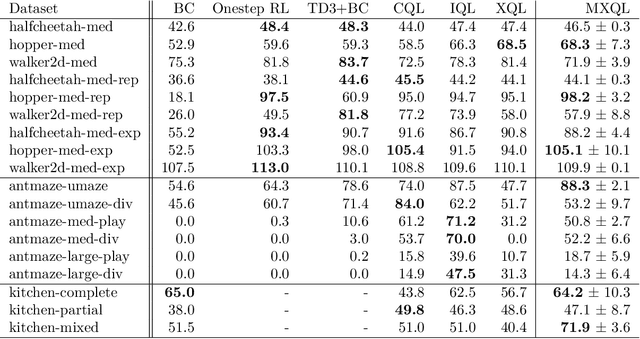
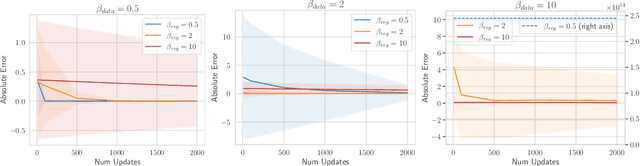
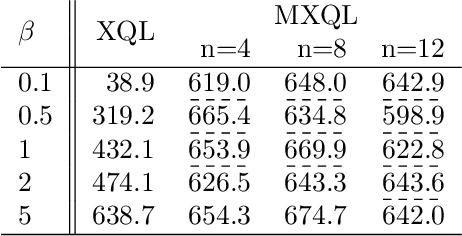
In Extreme Q-learning (XQL), Gumbel Regression is performed with an assumed Gumbel distribution for the error distribution. This allows learning of the value function without sampling out-of-distribution actions and has shown excellent performance mainly in Offline RL. However, issues remained, including the exponential term in the loss function causing instability and the potential for an error distribution diverging from the Gumbel distribution. Therefore, we propose Maclaurin Expanded Extreme Q-learning to enhance stability. In this method, applying Maclaurin expansion to the loss function in XQL enhances stability against large errors. It also allows adjusting the error distribution assumption from normal to Gumbel based on the expansion order. Our method significantly stabilizes learning in Online RL tasks from DM Control, where XQL was previously unstable. Additionally, it improves performance in several Offline RL tasks from D4RL, where XQL already showed excellent results.
HyperVQ: MLR-based Vector Quantization in Hyperbolic Space
Mar 18, 2024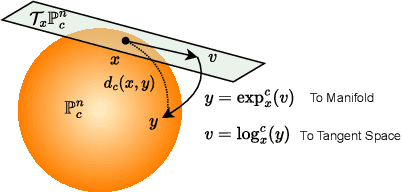

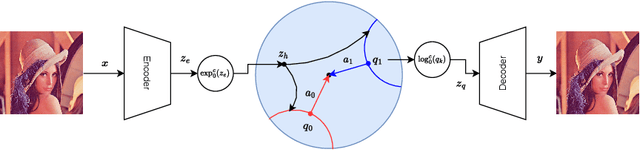

The success of models operating on tokenized data has led to an increased demand for effective tokenization methods, particularly when applied to vision or auditory tasks, which inherently involve non-discrete data. One of the most popular tokenization methods is Vector Quantization (VQ), a key component of several recent state-of-the-art methods across various domains. Typically, a VQ Variational Autoencoder (VQVAE) is trained to transform data to and from its tokenized representation. However, since the VQVAE is trained with a reconstruction objective, there is no constraint for the embeddings to be well disentangled, a crucial aspect for using them in discriminative tasks. Recently, several works have demonstrated the benefits of utilizing hyperbolic spaces for representation learning. Hyperbolic spaces induce compact latent representations due to their exponential volume growth and inherent ability to model hierarchical and structured data. In this work, we explore the use of hyperbolic spaces for vector quantization (HyperVQ), formulating the VQ operation as a hyperbolic Multinomial Logistic Regression (MLR) problem, in contrast to the Euclidean K-Means clustering used in VQVAE. Through extensive experiments, we demonstrate that hyperVQ performs comparably in reconstruction and generative tasks while outperforming VQ in discriminative tasks and learning a highly disentangled latent space.
Symmetric Q-learning: Reducing Skewness of Bellman Error in Online Reinforcement Learning
Mar 12, 2024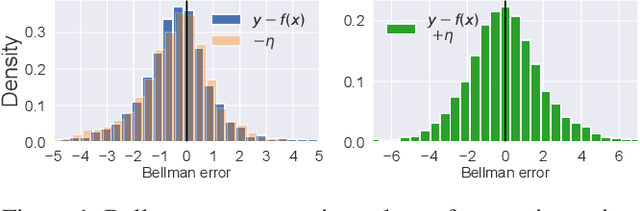

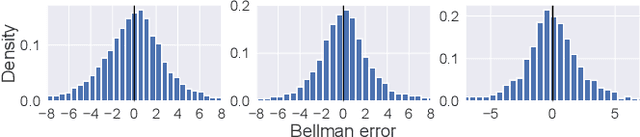
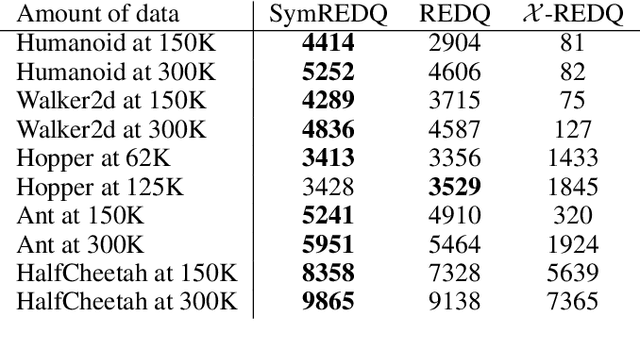
In deep reinforcement learning, estimating the value function to evaluate the quality of states and actions is essential. The value function is often trained using the least squares method, which implicitly assumes a Gaussian error distribution. However, a recent study suggested that the error distribution for training the value function is often skewed because of the properties of the Bellman operator, and violates the implicit assumption of normal error distribution in the least squares method. To address this, we proposed a method called Symmetric Q-learning, in which the synthetic noise generated from a zero-mean distribution is added to the target values to generate a Gaussian error distribution. We evaluated the proposed method on continuous control benchmark tasks in MuJoCo. It improved the sample efficiency of a state-of-the-art reinforcement learning method by reducing the skewness of the error distribution.
Fully Spiking Denoising Diffusion Implicit Models
Dec 04, 2023Spiking neural networks (SNNs) have garnered considerable attention owing to their ability to run on neuromorphic devices with super-high speeds and remarkable energy efficiencies. SNNs can be used in conventional neural network-based time- and energy-consuming applications. However, research on generative models within SNNs remains limited, despite their advantages. In particular, diffusion models are a powerful class of generative models, whose image generation quality surpass that of the other generative models, such as GANs. However, diffusion models are characterized by high computational costs and long inference times owing to their iterative denoising feature. Therefore, we propose a novel approach fully spiking denoising diffusion implicit model (FSDDIM) to construct a diffusion model within SNNs and leverage the high speed and low energy consumption features of SNNs via synaptic current learning (SCL). SCL fills the gap in that diffusion models use a neural network to estimate real-valued parameters of a predefined probabilistic distribution, whereas SNNs output binary spike trains. The SCL enables us to complete the entire generative process of diffusion models exclusively using SNNs. We demonstrate that the proposed method outperforms the state-of-the-art fully spiking generative model.
HiPerformer: Hierarchically Permutation-Equivariant Transformer for Time Series Forecasting
May 14, 2023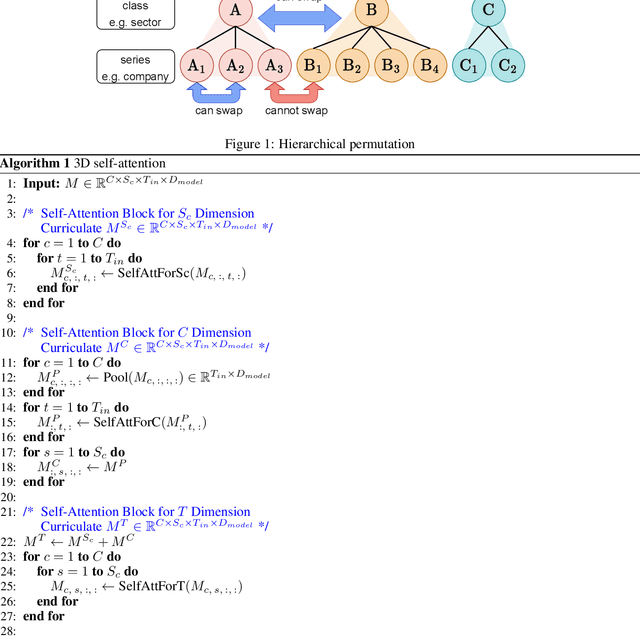

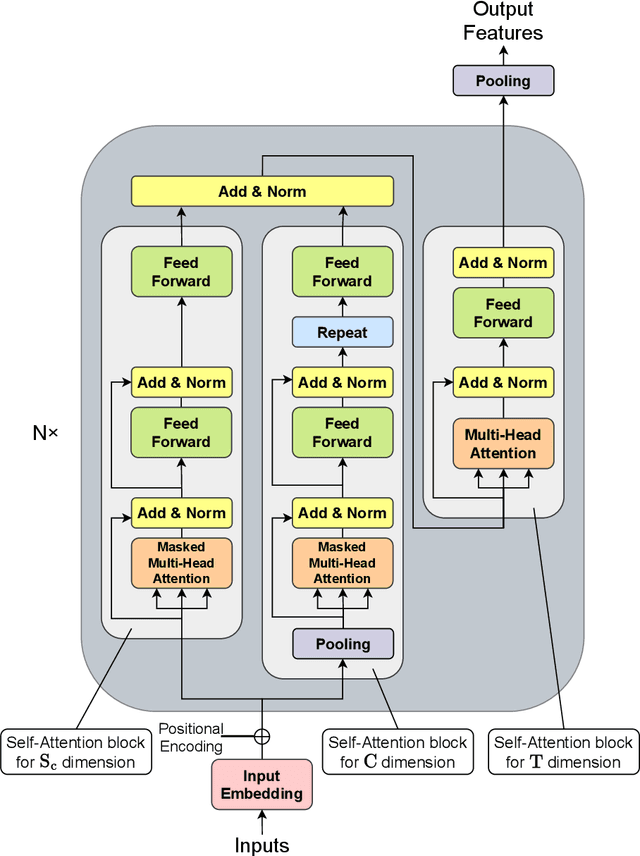
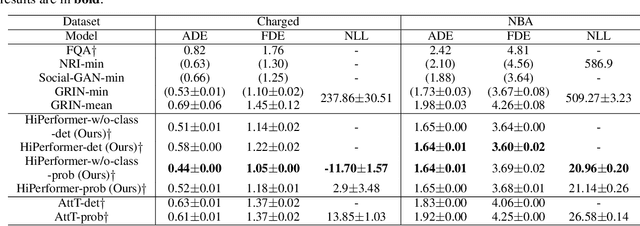
It is imperative to discern the relationships between multiple time series for accurate forecasting. In particular, for stock prices, components are often divided into groups with the same characteristics, and a model that extracts relationships consistent with this group structure should be effective. Thus, we propose the concept of hierarchical permutation-equivariance, focusing on index swapping of components within and among groups, to design a model that considers this group structure. When the prediction model has hierarchical permutation-equivariance, the prediction is consistent with the group relationships of the components. Therefore, we propose a hierarchically permutation-equivariant model that considers both the relationship among components in the same group and the relationship among groups. The experiments conducted on real-world data demonstrate that the proposed method outperforms existing state-of-the-art methods.
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Apr 07, 2023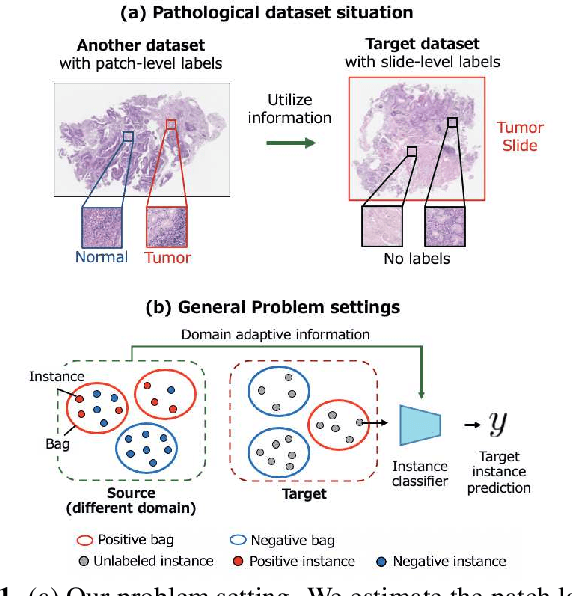
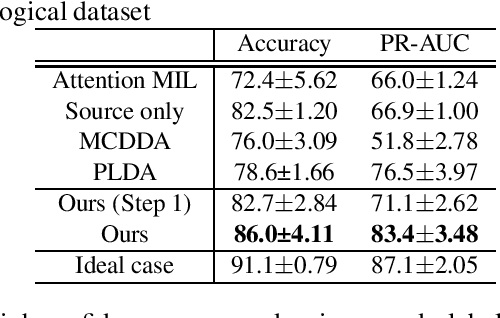
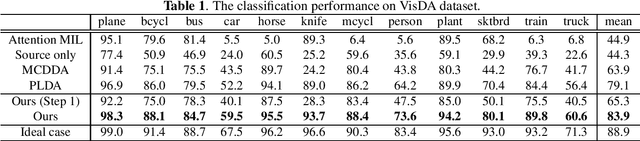
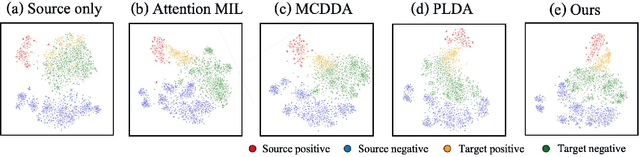
Pathological image analysis is an important process for detecting abnormalities such as cancer from cell images. However, since the image size is generally very large, the cost of providing detailed annotations is high, which makes it difficult to apply machine learning techniques. One way to improve the performance of identifying abnormalities while keeping the annotation cost low is to use only labels for each slide, or to use information from another dataset that has already been labeled. However, such weak supervisory information often does not provide sufficient performance. In this paper, we proposed a new task setting to improve the classification performance of the target dataset without increasing annotation costs. And to solve this problem, we propose a pipeline that uses multiple instance learning (MIL) and domain adaptation (DA) methods. Furthermore, in order to combine the supervisory information of both methods effectively, we propose a method to create pseudo-labels with high confidence. We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.
Self-Supervised Learning for Group Equivariant Neural Networks
Mar 08, 2023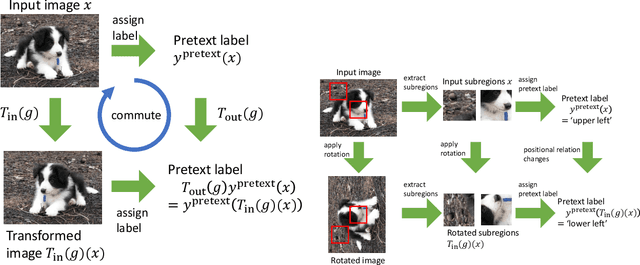


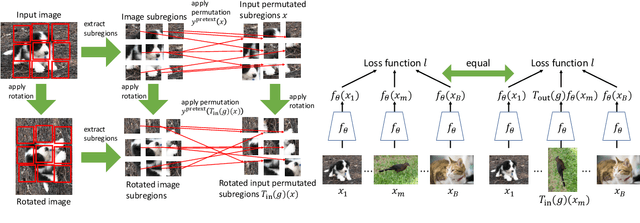
This paper proposes a method to construct pretext tasks for self-supervised learning on group equivariant neural networks. Group equivariant neural networks are the models whose structure is restricted to commute with the transformations on the input. Therefore, it is important to construct pretext tasks for self-supervised learning that do not contradict this equivariance. To ensure that training is consistent with the equivariance, we propose two concepts for self-supervised tasks: equivariant pretext labels and invariant contrastive loss. Equivariant pretext labels use a set of labels on which we can define the transformations that correspond to the input change. Invariant contrastive loss uses a modified contrastive loss that absorbs the effect of transformations on each input. Experiments on standard image recognition benchmarks demonstrate that the equivariant neural networks exploit the proposed equivariant self-supervised tasks.