 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation
Paper and Code

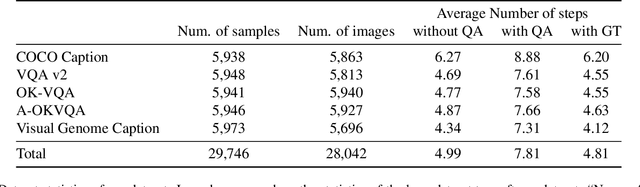


The increasing demand for intelligent systems capable of interpreting and reasoning about visual content requires the development of Large Multi-Modal Models (LMMs) that are not only accurate but also have explicit reasoning capabilities. This paper presents a novel approach to imbue an LMM with the ability to conduct explicit reasoning based on visual content and textual instructions. We introduce a system that can ask a question to acquire necessary knowledge, thereby enhancing the robustness and explicability of the reasoning process. Our method comprises the development of a novel dataset generated by a Large Language Model (LLM), designed to promote chain-of-thought reasoning combined with a question-asking mechanism. We designed an LMM, which has high capabilities on region awareness to address the intricate requirements of image-text alignment. The model undergoes a three-stage training phase, starting with large-scale image-text alignment using a large-scale datasets, followed by instruction tuning, and fine-tuning with a focus on chain-of-thought reasoning. The results demonstrate a stride toward a more robust, accurate, and interpretable LMM, capable of reasoning explicitly and seeking information proactively when confronted with ambiguous visual input.