 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot-Assisted Group Tours for Blind People
Feb 04, 2026Group interactions are essential to social functioning, yet effective engagement relies on the ability to recognize and interpret visual cues, making such engagement a significant challenge for blind people. In this paper, we investigate how a mobile robot can support group interactions for blind people. We used the scenario of a guided tour with mixed-visual groups involving blind and sighted visitors. Based on insights from an interview study with blind people (n=5) and museum experts (n=5), we designed and prototyped a robotic system that supported blind visitors to join group tours. We conducted a field study in a science museum where each blind participant (n=8) joined a group tour with one guide and two sighted participants (n=8). Findings indicated users' sense of safety from the robot's navigational support, concerns in the group participation, and preferences for obtaining environmental information. We present design implications for future robotic systems to support blind people's mixed-visual group participation.
How Does Delegation in Social Interaction Evolve Over Time? Navigation with a Robot for Blind People
Jan 27, 2026Autonomy and independent navigation are vital to daily life but remain challenging for individuals with blindness. Robotic systems can enhance mobility and confidence by providing intelligent navigation assistance. However, fully autonomous systems may reduce users' sense of control, even when they wish to remain actively involved. Although collaboration between user and robot has been recognized as important, little is known about how perceptions of this relationship change with repeated use. We present a repeated exposure study with six blind participants who interacted with a navigation-assistive robot in a real-world museum. Participants completed tasks such as navigating crowds, approaching lines, and encountering obstacles. Findings show that participants refined their strategies over time, developing clearer preferences about when to rely on the robot versus act independently. This work provides insights into how strategies and preferences evolve with repeated interaction and offers design implications for robots that adapt to user needs over time.
Understanding and Supporting Formal Email Exchange by Answering AI-Generated Questions
Feb 06, 2025



Replying to formal emails is time-consuming and cognitively demanding, as it requires polite phrasing and ensuring an adequate response to the sender's demands. Although systems with Large Language Models (LLM) were designed to simplify the email replying process, users still needed to provide detailed prompts to obtain the expected output. Therefore, we proposed and evaluated an LLM-powered question-and-answer (QA)-based approach for users to reply to emails by answering a set of simple and short questions generated from the incoming email. We developed a prototype system, ResQ, and conducted controlled and field experiments with 12 and 8 participants. Our results demonstrated that QA-based approach improves the efficiency of replying to emails and reduces workload while maintaining email quality compared to a conventional prompt-based approach that requires users to craft appropriate prompts to obtain email drafts. We discuss how QA-based approach influences the email reply process and interpersonal relationship dynamics, as well as the opportunities and challenges associated with using a QA-based approach in AI-mediated communication.
Text to Blind Motion
Dec 06, 2024

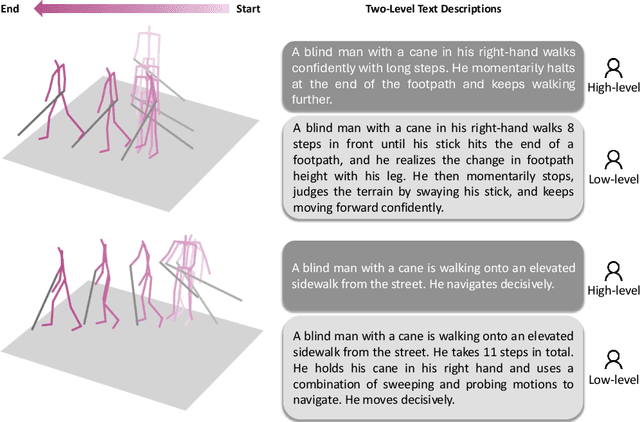
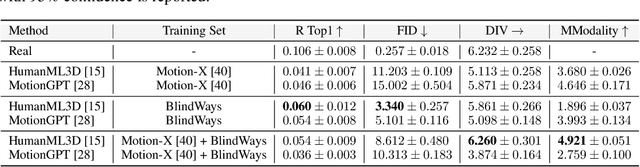
People who are blind perceive the world differently than those who are sighted, which can result in distinct motion characteristics. For instance, when crossing at an intersection, blind individuals may have different patterns of movement, such as veering more from a straight path or using touch-based exploration around curbs and obstacles. These behaviors may appear less predictable to motion models embedded in technologies such as autonomous vehicles. Yet, the ability of 3D motion models to capture such behavior has not been previously studied, as existing datasets for 3D human motion currently lack diversity and are biased toward people who are sighted. In this work, we introduce BlindWays, the first multimodal motion benchmark for pedestrians who are blind. We collect 3D motion data using wearable sensors with 11 blind participants navigating eight different routes in a real-world urban setting. Additionally, we provide rich textual descriptions that capture the distinctive movement characteristics of blind pedestrians and their interactions with both the navigation aid (e.g., a white cane or a guide dog) and the environment. We benchmark state-of-the-art 3D human prediction models, finding poor performance with off-the-shelf and pre-training-based methods for our novel task. To contribute toward safer and more reliable systems that can seamlessly reason over diverse human movements in their environments, our text-and-motion benchmark is available at https://blindways.github.io.
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
May 11, 2024

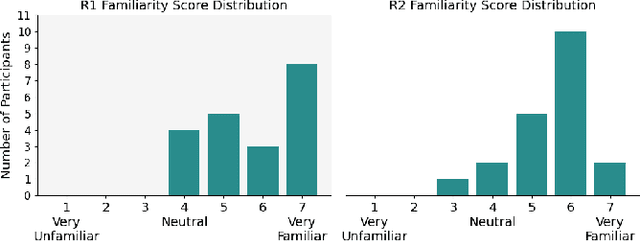
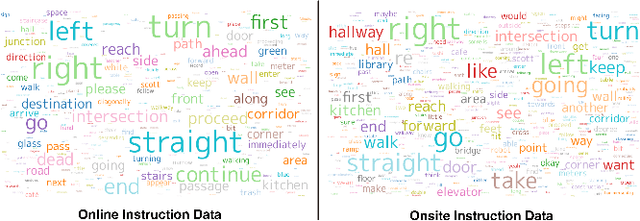
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.