 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Offline Metrics for Autonomous Driving
Oct 09, 2025Real-World evaluation of perception-based planning models for robotic systems, such as autonomous vehicles, can be safely and inexpensively conducted offline, i.e., by computing model prediction error over a pre-collected validation dataset with ground-truth annotations. However, extrapolating from offline model performance to online settings remains a challenge. In these settings, seemingly minor errors can compound and result in test-time infractions or collisions. This relationship is understudied, particularly across diverse closed-loop metrics and complex urban maneuvers. In this work, we revisit this undervalued question in policy evaluation through an extensive set of experiments across diverse conditions and metrics. Based on analysis in simulation, we find an even worse correlation between offline and online settings than reported by prior studies, casting doubts on the validity of current evaluation practices and metrics for driving policies. Next, we bridge the gap between offline and online evaluation. We investigate an offline metric based on epistemic uncertainty, which aims to capture events that are likely to cause errors in closed-loop settings. The resulting metric achieves over 13% improvement in correlation compared to previous offline metrics. We further validate the generalization of our findings beyond the simulation environment in real-world settings, where even greater gains are observed.
DriveQA: Passing the Driving Knowledge Test
Aug 29, 2025



If a Large Language Model (LLM) were to take a driving knowledge test today, would it pass? Beyond standard spatial and visual question-answering (QA) tasks on current autonomous driving benchmarks, driving knowledge tests require a complete understanding of all traffic rules, signage, and right-of-way principles. To pass this test, human drivers must discern various edge cases that rarely appear in real-world datasets. In this work, we present DriveQA, an extensive open-source text and vision-based benchmark that exhaustively covers traffic regulations and scenarios. Through our experiments using DriveQA, we show that (1) state-of-the-art LLMs and Multimodal LLMs (MLLMs) perform well on basic traffic rules but exhibit significant weaknesses in numerical reasoning and complex right-of-way scenarios, traffic sign variations, and spatial layouts, (2) fine-tuning on DriveQA improves accuracy across multiple categories, particularly in regulatory sign recognition and intersection decision-making, (3) controlled variations in DriveQA-V provide insights into model sensitivity to environmental factors such as lighting, perspective, distance, and weather conditions, and (4) pretraining on DriveQA enhances downstream driving task performance, leading to improved results on real-world datasets such as nuScenes and BDD, while also demonstrating that models can internalize text and synthetic traffic knowledge to generalize effectively across downstream QA tasks.
ZeroVO: Visual Odometry with Minimal Assumptions
Jun 09, 2025We introduce ZeroVO, a novel visual odometry (VO) algorithm that achieves zero-shot generalization across diverse cameras and environments, overcoming limitations in existing methods that depend on predefined or static camera calibration setups. Our approach incorporates three main innovations. First, we design a calibration-free, geometry-aware network structure capable of handling noise in estimated depth and camera parameters. Second, we introduce a language-based prior that infuses semantic information to enhance robust feature extraction and generalization to previously unseen domains. Third, we develop a flexible, semi-supervised training paradigm that iteratively adapts to new scenes using unlabeled data, further boosting the models' ability to generalize across diverse real-world scenarios. We analyze complex autonomous driving contexts, demonstrating over 30% improvement against prior methods on three standard benchmarks, KITTI, nuScenes, and Argoverse 2, as well as a newly introduced, high-fidelity synthetic dataset derived from Grand Theft Auto (GTA). By not requiring fine-tuning or camera calibration, our work broadens the applicability of VO, providing a versatile solution for real-world deployment at scale.
Text to Blind Motion
Dec 06, 2024

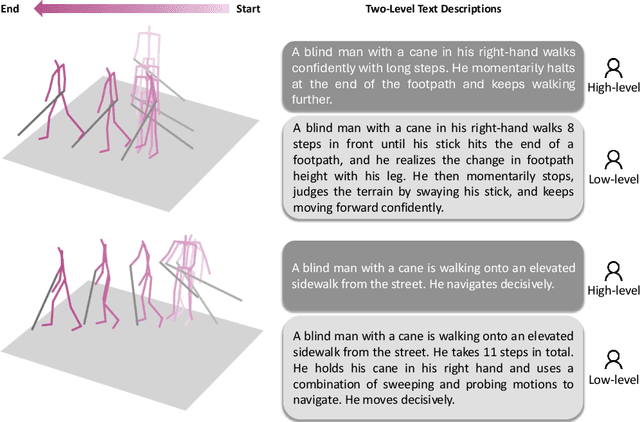
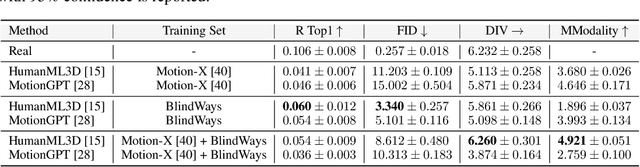
People who are blind perceive the world differently than those who are sighted, which can result in distinct motion characteristics. For instance, when crossing at an intersection, blind individuals may have different patterns of movement, such as veering more from a straight path or using touch-based exploration around curbs and obstacles. These behaviors may appear less predictable to motion models embedded in technologies such as autonomous vehicles. Yet, the ability of 3D motion models to capture such behavior has not been previously studied, as existing datasets for 3D human motion currently lack diversity and are biased toward people who are sighted. In this work, we introduce BlindWays, the first multimodal motion benchmark for pedestrians who are blind. We collect 3D motion data using wearable sensors with 11 blind participants navigating eight different routes in a real-world urban setting. Additionally, we provide rich textual descriptions that capture the distinctive movement characteristics of blind pedestrians and their interactions with both the navigation aid (e.g., a white cane or a guide dog) and the environment. We benchmark state-of-the-art 3D human prediction models, finding poor performance with off-the-shelf and pre-training-based methods for our novel task. To contribute toward safer and more reliable systems that can seamlessly reason over diverse human movements in their environments, our text-and-motion benchmark is available at https://blindways.github.io.
UniLCD: Unified Local-Cloud Decision-Making via Reinforcement Learning
Sep 17, 2024



Embodied vision-based real-world systems, such as mobile robots, require a careful balance between energy consumption, compute latency, and safety constraints to optimize operation across dynamic tasks and contexts. As local computation tends to be restricted, offloading the computation, ie, to a remote server, can save local resources while providing access to high-quality predictions from powerful and large models. However, the resulting communication and latency overhead has led to limited usability of cloud models in dynamic, safety-critical, real-time settings. To effectively address this trade-off, we introduce UniLCD, a novel hybrid inference framework for enabling flexible local-cloud collaboration. By efficiently optimizing a flexible routing module via reinforcement learning and a suitable multi-task objective, UniLCD is specifically designed to support the multiple constraints of safety-critical end-to-end mobile systems. We validate the proposed approach using a challenging, crowded navigation task requiring frequent and timely switching between local and cloud operations. UniLCD demonstrates improved overall performance and efficiency, by over 35% compared to state-of-the-art baselines based on various split computing and early exit strategies.
XVO: Generalized Visual Odometry via Cross-Modal Self-Training
Oct 08, 2023
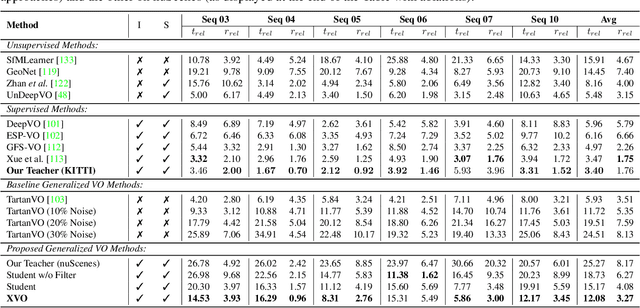
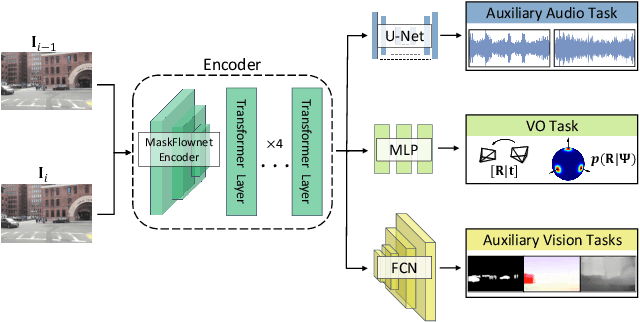
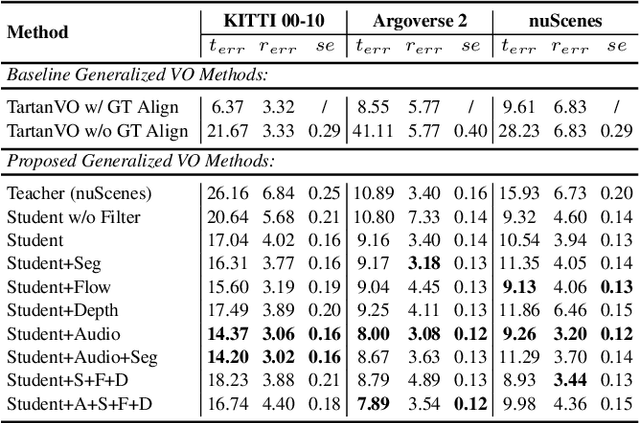
We propose XVO, a semi-supervised learning method for training generalized monocular Visual Odometry (VO) models with robust off-the-self operation across diverse datasets and settings. In contrast to standard monocular VO approaches which often study a known calibration within a single dataset, XVO efficiently learns to recover relative pose with real-world scale from visual scene semantics, i.e., without relying on any known camera parameters. We optimize the motion estimation model via self-training from large amounts of unconstrained and heterogeneous dash camera videos available on YouTube. Our key contribution is twofold. First, we empirically demonstrate the benefits of semi-supervised training for learning a general-purpose direct VO regression network. Second, we demonstrate multi-modal supervision, including segmentation, flow, depth, and audio auxiliary prediction tasks, to facilitate generalized representations for the VO task. Specifically, we find audio prediction task to significantly enhance the semi-supervised learning process while alleviating noisy pseudo-labels, particularly in highly dynamic and out-of-domain video data. Our proposed teacher network achieves state-of-the-art performance on the commonly used KITTI benchmark despite no multi-frame optimization or knowledge of camera parameters. Combined with the proposed semi-supervised step, XVO demonstrates off-the-shelf knowledge transfer across diverse conditions on KITTI, nuScenes, and Argoverse without fine-tuning.
Learning to Drive Anywhere
Sep 25, 2023



Human drivers can seamlessly adapt their driving decisions across geographical locations with diverse conditions and rules of the road, e.g., left vs. right-hand traffic. In contrast, existing models for autonomous driving have been thus far only deployed within restricted operational domains, i.e., without accounting for varying driving behaviors across locations or model scalability. In this work, we propose AnyD, a single geographically-aware conditional imitation learning (CIL) model that can efficiently learn from heterogeneous and globally distributed data with dynamic environmental, traffic, and social characteristics. Our key insight is to introduce a high-capacity geo-location-based channel attention mechanism that effectively adapts to local nuances while also flexibly modeling similarities among regions in a data-driven manner. By optimizing a contrastive imitation objective, our proposed approach can efficiently scale across inherently imbalanced data distributions and location-dependent events. We demonstrate the benefits of our AnyD agent across multiple datasets, cities, and scalable deployment paradigms, i.e., centralized, semi-supervised, and distributed agent training. Specifically, AnyD outperforms CIL baselines by over 14% in open-loop evaluation and 30% in closed-loop testing on CARLA.
Coaching a Teachable Student
Jun 16, 2023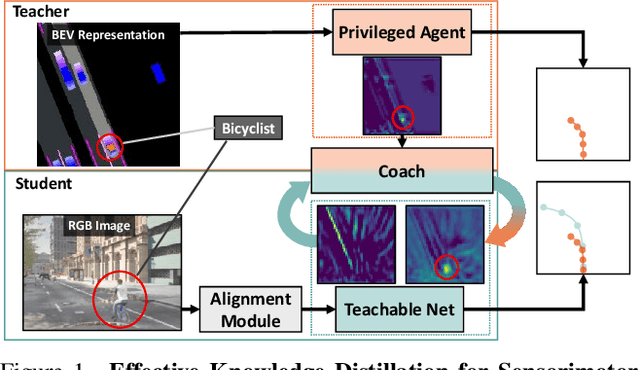
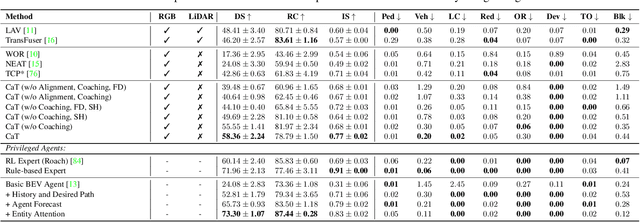
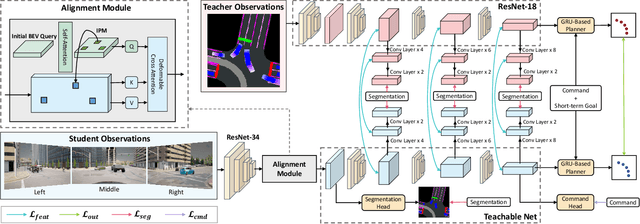
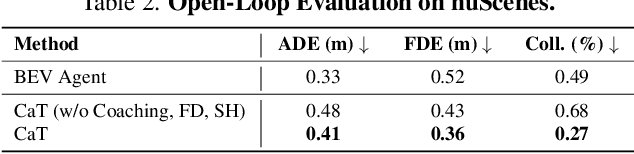
We propose a novel knowledge distillation framework for effectively teaching a sensorimotor student agent to drive from the supervision of a privileged teacher agent. Current distillation for sensorimotor agents methods tend to result in suboptimal learned driving behavior by the student, which we hypothesize is due to inherent differences between the input, modeling capacity, and optimization processes of the two agents. We develop a novel distillation scheme that can address these limitations and close the gap between the sensorimotor agent and its privileged teacher. Our key insight is to design a student which learns to align their input features with the teacher's privileged Bird's Eye View (BEV) space. The student then can benefit from direct supervision by the teacher over the internal representation learning. To scaffold the difficult sensorimotor learning task, the student model is optimized via a student-paced coaching mechanism with various auxiliary supervision. We further propose a high-capacity imitation learned privileged agent that surpasses prior privileged agents in CARLA and ensures the student learns safe driving behavior. Our proposed sensorimotor agent results in a robust image-based behavior cloning agent in CARLA, improving over current models by over 20.6% in driving score without requiring LiDAR, historical observations, ensemble of models, on-policy data aggregation or reinforcement learning.
SelfD: Self-Learning Large-Scale Driving Policies From the Web
Apr 21, 2022
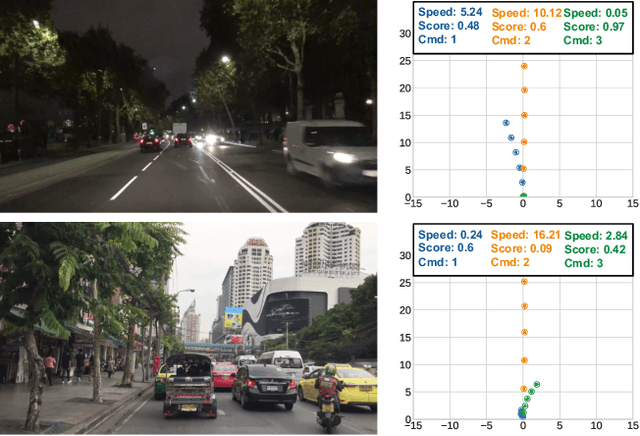
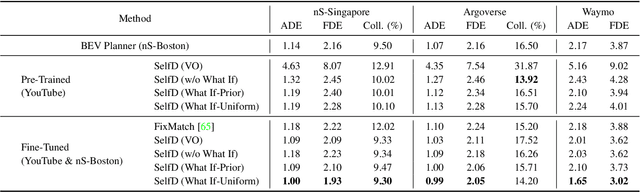

Effectively utilizing the vast amounts of ego-centric navigation data that is freely available on the internet can advance generalized intelligent systems, i.e., to robustly scale across perspectives, platforms, environmental conditions, scenarios, and geographical locations. However, it is difficult to directly leverage such large amounts of unlabeled and highly diverse data for complex 3D reasoning and planning tasks. Consequently, researchers have primarily focused on its use for various auxiliary pixel- and image-level computer vision tasks that do not consider an ultimate navigational objective. In this work, we introduce SelfD, a framework for learning scalable driving by utilizing large amounts of online monocular images. Our key idea is to leverage iterative semi-supervised training when learning imitative agents from unlabeled data. To handle unconstrained viewpoints, scenes, and camera parameters, we train an image-based model that directly learns to plan in the Bird's Eye View (BEV) space. Next, we use unlabeled data to augment the decision-making knowledge and robustness of an initially trained model via self-training. In particular, we propose a pseudo-labeling step which enables making full use of highly diverse demonstration data through "hypothetical" planning-based data augmentation. We employ a large dataset of publicly available YouTube videos to train SelfD and comprehensively analyze its generalization benefits across challenging navigation scenarios. Without requiring any additional data collection or annotation efforts, SelfD demonstrates consistent improvements (by up to 24%) in driving performance evaluation on nuScenes, Argoverse, Waymo, and CARLA.
Learning by Watching
Jun 10, 2021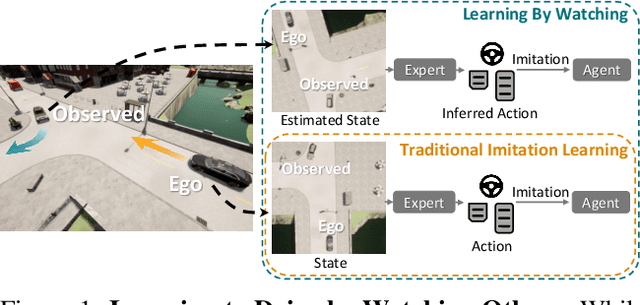

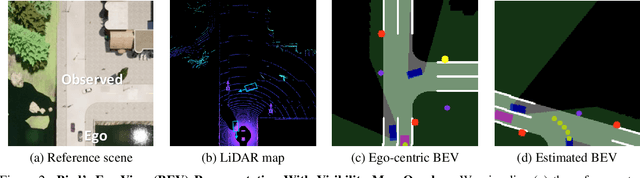
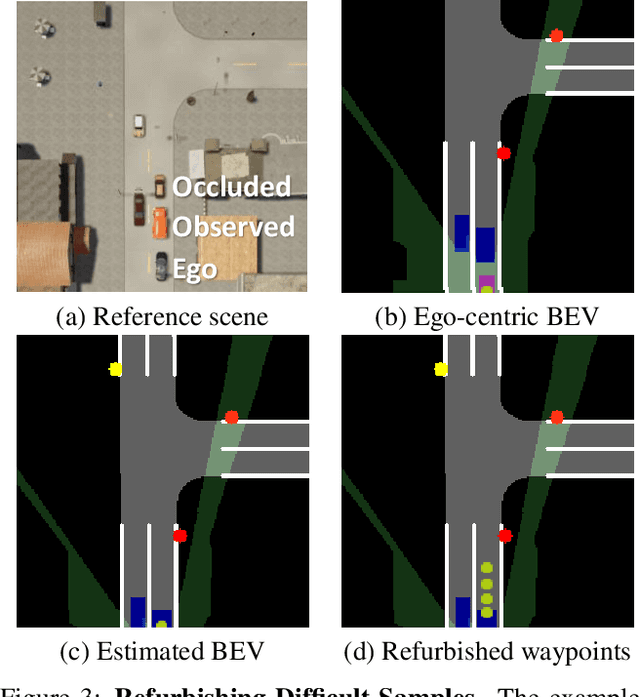
When in a new situation or geographical location, human drivers have an extraordinary ability to watch others and learn maneuvers that they themselves may have never performed. In contrast, existing techniques for learning to drive preclude such a possibility as they assume direct access to an instrumented ego-vehicle with fully known observations and expert driver actions. However, such measurements cannot be directly accessed for the non-ego vehicles when learning by watching others. Therefore, in an application where data is regarded as a highly valuable asset, current approaches completely discard the vast portion of the training data that can be potentially obtained through indirect observation of surrounding vehicles. Motivated by this key insight, we propose the Learning by Watching (LbW) framework which enables learning a driving policy without requiring full knowledge of neither the state nor expert actions. To increase its data, i.e., with new perspectives and maneuvers, LbW makes use of the demonstrations of other vehicles in a given scene by (1) transforming the ego-vehicle's observations to their points of view, and (2) inferring their expert actions. Our LbW agent learns more robust driving policies while enabling data-efficient learning, including quick adaptation of the policy to rare and novel scenarios. In particular, LbW drives robustly even with a fraction of available driving data required by existing methods, achieving an average success rate of 92% on the original CARLA benchmark with only 30 minutes of total driving data and 82% with only 10 minutes.