 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSay It My Way: Exploring Control in Conversational Visual Question Answering with Blind Users
Feb 18, 2026Prompting and steering techniques are well established in general-purpose generative AI, yet assistive visual question answering (VQA) tools for blind users still follow rigid interaction patterns with limited opportunities for customization. User control can be helpful when system responses are misaligned with their goals and contexts, a gap that becomes especially consequential for blind users that may rely on these systems for access. We invite 11 blind users to customize their interactions with a real-world conversational VQA system. Drawing on 418 interactions, reflections, and post-study interviews, we analyze prompting-based techniques participants adopted, including those introduced in the study and those developed independently in real-world settings. VQA interactions were often lengthy: participants averaged 3 turns, sometimes up to 21, with input text typically tenfold shorter than the responses they heard. Built on state-of-the-art LLMs, the system lacked verbosity controls, was limited in estimating distance in space and time, relied on inaccessible image framing, and offered little to no camera guidance. We discuss how customization techniques such as prompt engineering can help participants work around these limitations. Alongside a new publicly available dataset, we offer insights for interaction design at both query and system levels.
Beyond Omakase: Designing Shared Control for Navigation Robots with Blind People
Mar 31, 2025



Autonomous navigation robots can increase the independence of blind people but often limit user control, following what is called in Japanese an "omakase" approach where decisions are left to the robot. This research investigates ways to enhance user control in social robot navigation, based on two studies conducted with blind participants. The first study, involving structured interviews (N=14), identified crowded spaces as key areas with significant social challenges. The second study (N=13) explored navigation tasks with an autonomous robot in these environments and identified design strategies across different modes of autonomy. Participants preferred an active role, termed the "boss" mode, where they managed crowd interactions, while the "monitor" mode helped them assess the environment, negotiate movements, and interact with the robot. These findings highlight the importance of shared control and user involvement for blind users, offering valuable insights for designing future social navigation robots.
Text to Blind Motion
Dec 06, 2024

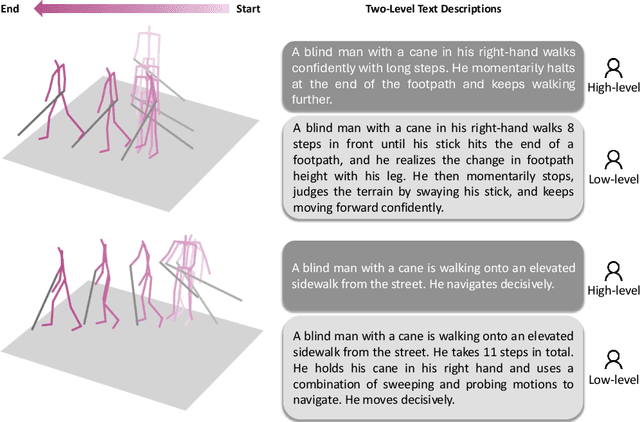
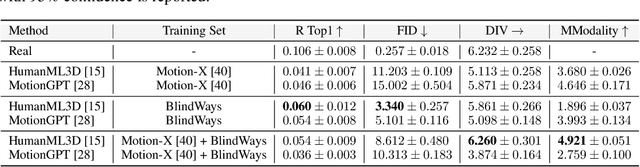
People who are blind perceive the world differently than those who are sighted, which can result in distinct motion characteristics. For instance, when crossing at an intersection, blind individuals may have different patterns of movement, such as veering more from a straight path or using touch-based exploration around curbs and obstacles. These behaviors may appear less predictable to motion models embedded in technologies such as autonomous vehicles. Yet, the ability of 3D motion models to capture such behavior has not been previously studied, as existing datasets for 3D human motion currently lack diversity and are biased toward people who are sighted. In this work, we introduce BlindWays, the first multimodal motion benchmark for pedestrians who are blind. We collect 3D motion data using wearable sensors with 11 blind participants navigating eight different routes in a real-world urban setting. Additionally, we provide rich textual descriptions that capture the distinctive movement characteristics of blind pedestrians and their interactions with both the navigation aid (e.g., a white cane or a guide dog) and the environment. We benchmark state-of-the-art 3D human prediction models, finding poor performance with off-the-shelf and pre-training-based methods for our novel task. To contribute toward safer and more reliable systems that can seamlessly reason over diverse human movements in their environments, our text-and-motion benchmark is available at https://blindways.github.io.
Understanding How Blind Users Handle Object Recognition Errors: Strategies and Challenges
Aug 06, 2024


Object recognition technologies hold the potential to support blind and low-vision people in navigating the world around them. However, the gap between benchmark performances and practical usability remains a significant challenge. This paper presents a study aimed at understanding blind users' interaction with object recognition systems for identifying and avoiding errors. Leveraging a pre-existing object recognition system, URCam, fine-tuned for our experiment, we conducted a user study involving 12 blind and low-vision participants. Through in-depth interviews and hands-on error identification tasks, we gained insights into users' experiences, challenges, and strategies for identifying errors in camera-based assistive technologies and object recognition systems. During interviews, many participants preferred independent error review, while expressing apprehension toward misrecognitions. In the error identification task, participants varied viewpoints, backgrounds, and object sizes in their images to avoid and overcome errors. Even after repeating the task, participants identified only half of the errors, and the proportion of errors identified did not significantly differ from their first attempts. Based on these insights, we offer implications for designing accessible interfaces tailored to the needs of blind and low-vision users in identifying object recognition errors.
AccessShare: Co-designing Data Access and Sharing with Blind People
Jul 27, 2024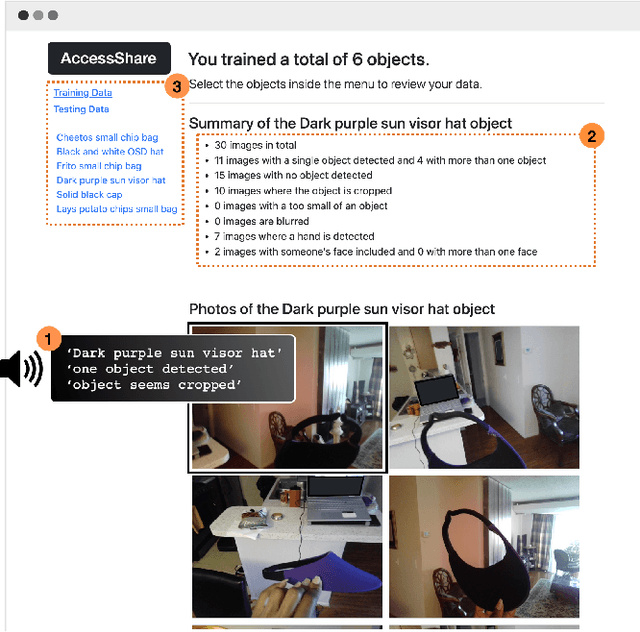
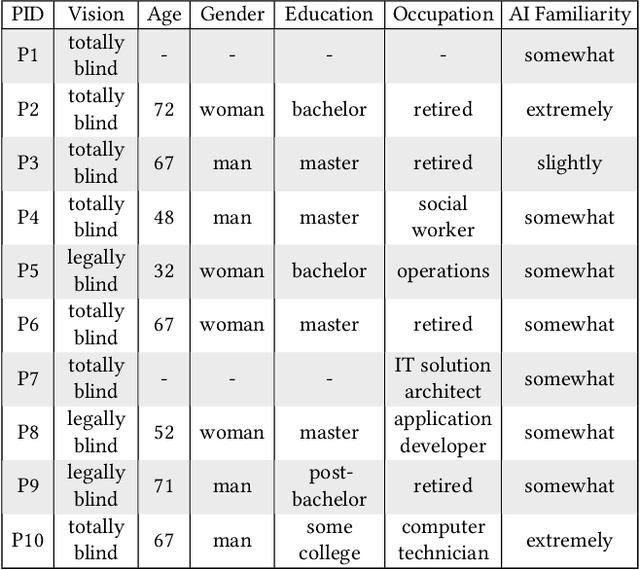
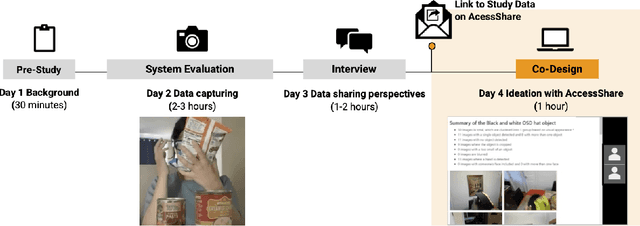
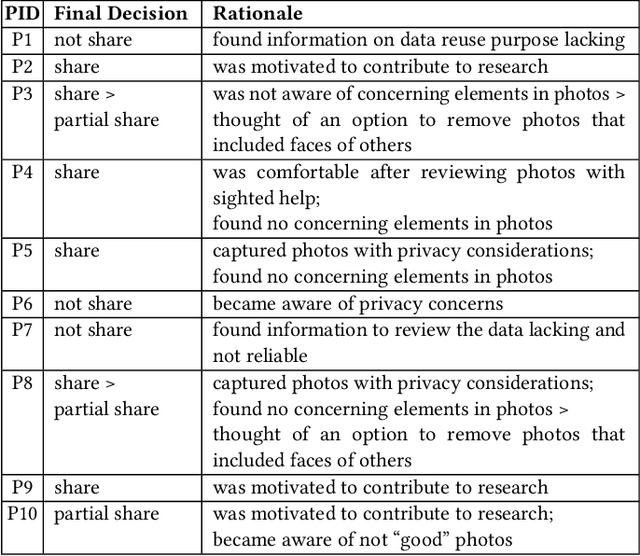
Blind people are often called to contribute image data to datasets for AI innovation with the hope for future accessibility and inclusion. Yet, the visual inspection of the contributed images is inaccessible. To this day, we lack mechanisms for data inspection and control that are accessible to the blind community. To address this gap, we engage 10 blind participants in a scenario where they wear smartglasses and collect image data using an AI-infused application in their homes. We also engineer a design probe, a novel data access interface called AccessShare, and conduct a co-design study to discuss participants' needs, preferences, and ideas on consent, data inspection, and control. Our findings reveal the impact of interactive informed consent and the complementary role of data inspection systems such as AccessShare in facilitating communication between data stewards and blind data contributors. We discuss how key insights can guide future informed consent and data control to promote inclusive and responsible data practices in AI.
"We are at the mercy of others' opinion": Supporting Blind People in Recreational Window Shopping with AI-infused Technology
May 10, 2024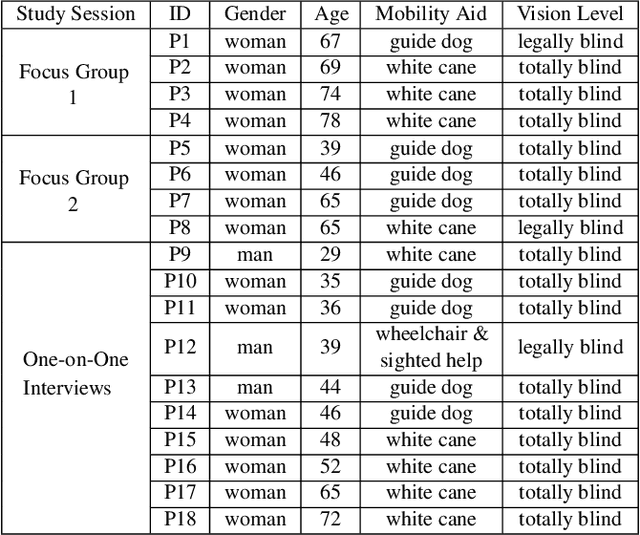
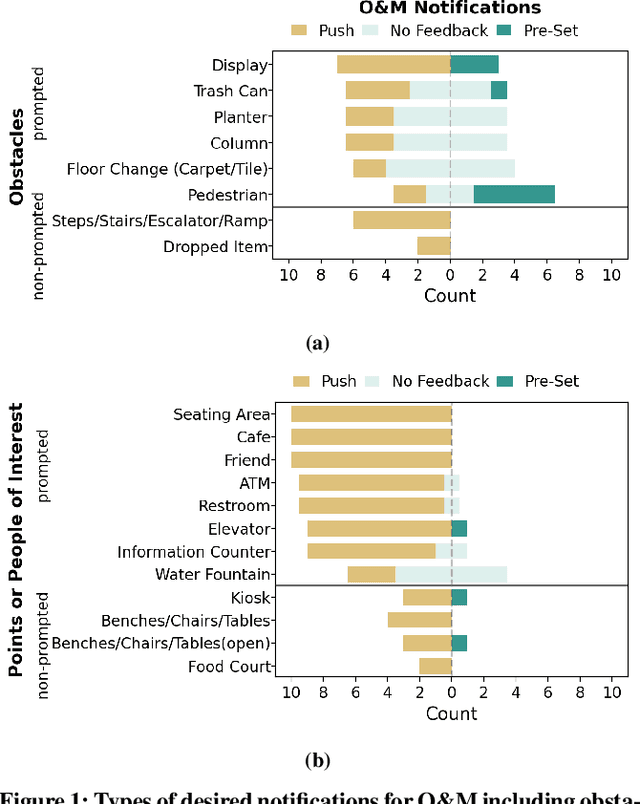
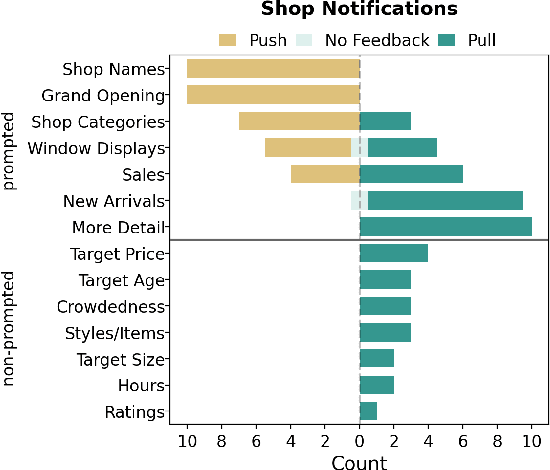
Engaging in recreational activities in public spaces poses challenges for blind people, often involving dependency on sighted help. Window shopping is a key recreational activity that remains inaccessible. In this paper, we investigate the information needs, challenges, and current approaches blind people have to recreational window shopping to inform the design of existing wayfinding and navigation technology for supporting blind shoppers in exploration and serendipitous discovery. We conduct a formative study with a total of 18 blind participants that include both focus groups (N=8) and interviews for requirements analysis (N=10). We find that there is a desire for push notifications of promotional information and pull notifications about shops of interest such as the targeted audience of a brand. Information about obstacles and points-of-interest required customization depending on one's mobility aid as well as presence of a crowd, children, and wheelchair users. We translate these findings into specific information modalities and rendering in the context of two existing AI-infused assistive applications: NavCog (a turn-by-turn navigation app) and Cabot (a navigation robot).
Examining the Values Reflected by Children during AI Problem Formulation
Sep 27, 2023
Understanding how children design and what they value in AI interfaces that allow them to explicitly train their models such as teachable machines, could help increase such activities' impact and guide the design of future technologies. In a co-design session using a modified storyboard, a team of 5 children (aged 7-13 years) and adult co-designers, engaged in AI problem formulation activities where they imagine their own teachable machines. Our findings, leveraging an established psychological value framework (the Rokeach Value Survey), illuminate how children conceptualize and embed their values in AI systems that they themselves devise to support their everyday activities. Specifically, we find that children's proposed ideas require advanced system intelligence, e.g. emotion detection and understanding the social relationships of a user. The underlying models could be trained under multiple modalities and any errors would be fixed by adding more data or by anticipating negative examples. Children's ideas showed they cared about family and expected machines to understand their social context before making decisions.
Blind Users Accessing Their Training Images in Teachable Object Recognizers
Aug 16, 2022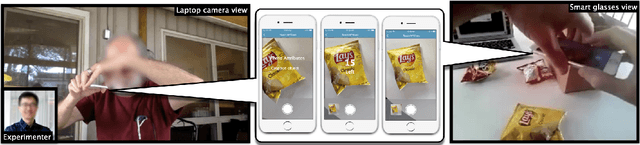

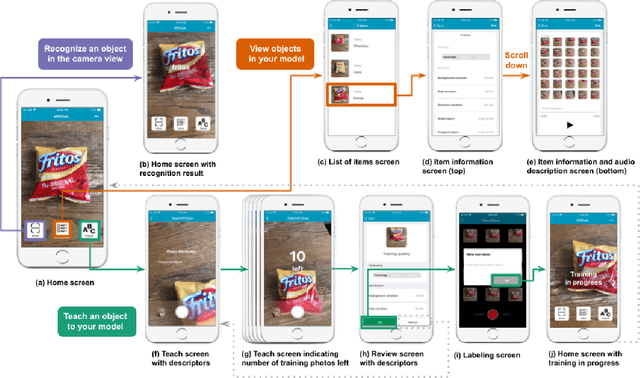

Iteration of training and evaluating a machine learning model is an important process to improve its performance. However, while teachable interfaces enable blind users to train and test an object recognizer with photos taken in their distinctive environment, accessibility of training iteration and evaluation steps has received little attention. Iteration assumes visual inspection of the training photos, which is inaccessible for blind users. We explore this challenge through MyCam, a mobile app that incorporates automatically estimated descriptors for non-visual access to the photos in the users' training sets. We explore how blind participants (N=12) interact with MyCam and the descriptors through an evaluation study in their homes. We demonstrate that the real-time photo-level descriptors enabled blind users to reduce photos with cropped objects, and that participants could add more variations by iterating through and accessing the quality of their training sets. Also, Participants found the app simple to use indicating that they could effectively train it and that the descriptors were useful. However, subjective responses were not reflected in the performance of their models, partially due to little variation in training and cluttered backgrounds.
Data Representativeness in Accessibility Datasets: A Meta-Analysis
Jul 16, 2022



As data-driven systems are increasingly deployed at scale, ethical concerns have arisen around unfair and discriminatory outcomes for historically marginalized groups that are underrepresented in training data. In response, work around AI fairness and inclusion has called for datasets that are representative of various demographic groups.In this paper, we contribute an analysis of the representativeness of age, gender, and race & ethnicity in accessibility datasets - datasets sourced from people with disabilities and older adults - that can potentially play an important role in mitigating bias for inclusive AI-infused applications. We examine the current state of representation within datasets sourced by people with disabilities by reviewing publicly-available information of 190 datasets, we call these accessibility datasets. We find that accessibility datasets represent diverse ages, but have gender and race representation gaps. Additionally, we investigate how the sensitive and complex nature of demographic variables makes classification difficult and inconsistent (e.g., gender, race & ethnicity), with the source of labeling often unknown. By reflecting on the current challenges and opportunities for representation of disabled data contributors, we hope our effort expands the space of possibility for greater inclusion of marginalized communities in AI-infused systems.
MyMove: Facilitating Older Adults to Collect In-Situ Activity Labels on a Smartwatch with Speech
Apr 01, 2022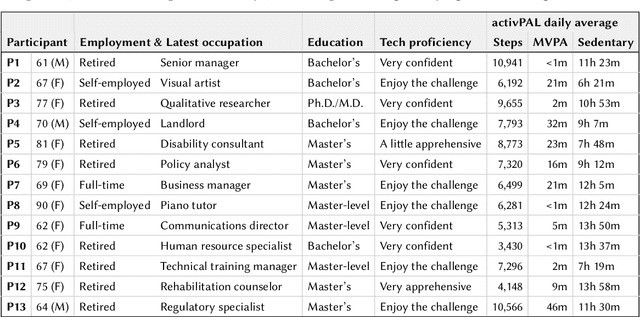

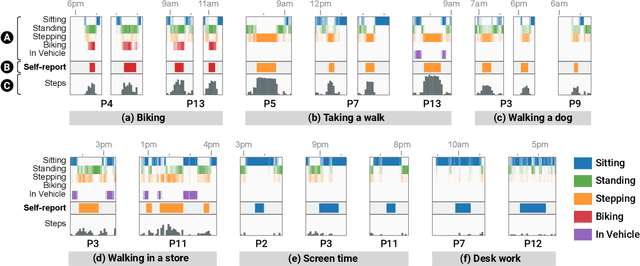
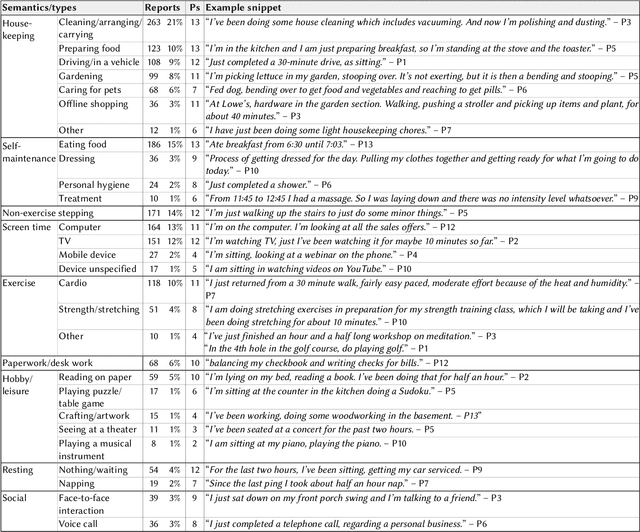
Current activity tracking technologies are largely trained on younger adults' data, which can lead to solutions that are not well-suited for older adults. To build activity trackers for older adults, it is crucial to collect training data with them. To this end, we examine the feasibility and challenges with older adults in collecting activity labels by leveraging speech. Specifically, we built MyMove, a speech-based smartwatch app to facilitate the in-situ labeling with a low capture burden. We conducted a 7-day deployment study, where 13 older adults collected their activity labels and smartwatch sensor data, while wearing a thigh-worn activity monitor. Participants were highly engaged, capturing 1,224 verbal reports in total. We extracted 1,885 activities with corresponding effort level and timespan, and examined the usefulness of these reports as activity labels. We discuss the implications of our approach and the collected dataset in supporting older adults through personalized activity tracking technologies.