 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClearFairy: Capturing Creative Workflows through Decision Structuring, In-Situ Questioning, and Rationale Inference
Sep 18, 2025Capturing professionals' decision-making in creative workflows is essential for reflection, collaboration, and knowledge sharing, yet existing methods often leave rationales incomplete and implicit decisions hidden. To address this, we present CLEAR framework that structures reasoning into cognitive decision steps-linked units of actions, artifacts, and self-explanations that make decisions traceable. Building on this framework, we introduce ClearFairy, a think-aloud AI assistant for UI design that detects weak explanations, asks lightweight clarifying questions, and infers missing rationales to ease the knowledge-sharing burden. In a study with twelve creative professionals, 85% of ClearFairy's inferred rationales were accepted, increasing strong explanations from 14% to over 83% of decision steps without adding cognitive demand. The captured steps also enhanced generative AI agents in Figma, yielding next-action predictions better aligned with professionals and producing more coherent design outcomes. For future research on human knowledge-grounded creative AI agents, we release a dataset of captured 417 decision steps.
Guidance for Intra-cardiac Echocardiography Manipulation to Maintain Continuous Therapy Device Tip Visibility
May 08, 2025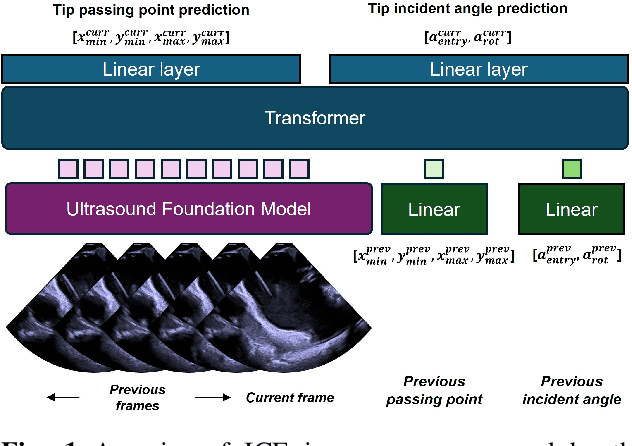
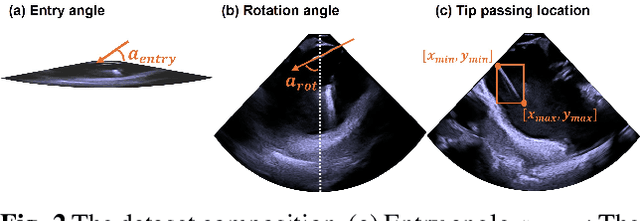
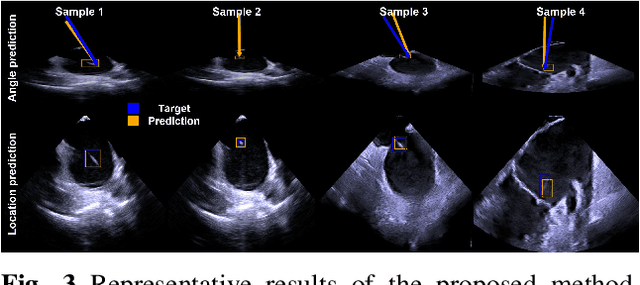
Intra-cardiac Echocardiography (ICE) plays a critical role in Electrophysiology (EP) and Structural Heart Disease (SHD) interventions by providing real-time visualization of intracardiac structures. However, maintaining continuous visibility of the therapy device tip remains a challenge due to frequent adjustments required during manual ICE catheter manipulation. To address this, we propose an AI-driven tracking model that estimates the device tip incident angle and passing point within the ICE imaging plane, ensuring continuous visibility and facilitating robotic ICE catheter control. A key innovation of our approach is the hybrid dataset generation strategy, which combines clinical ICE sequences with synthetic data augmentation to enhance model robustness. We collected ICE images in a water chamber setup, equipping both the ICE catheter and device tip with electromagnetic (EM) sensors to establish precise ground-truth locations. Synthetic sequences were created by overlaying catheter tips onto real ICE images, preserving motion continuity while simulating diverse anatomical scenarios. The final dataset consists of 5,698 ICE-tip image pairs, ensuring comprehensive training coverage. Our model architecture integrates a pretrained ultrasound (US) foundation model, trained on 37.4M echocardiography images, for feature extraction. A transformer-based network processes sequential ICE frames, leveraging historical passing points and incident angles to improve prediction accuracy. Experimental results demonstrate that our method achieves 3.32 degree entry angle error, 12.76 degree rotation angle error. This AI-driven framework lays the foundation for real-time robotic ICE catheter adjustments, minimizing operator workload while ensuring consistent therapy device visibility. Future work will focus on expanding clinical datasets to further enhance model generalization.
Pose Estimation for Intra-cardiac Echocardiography Catheter via AI-Based Anatomical Understanding
May 07, 2025



Intra-cardiac Echocardiography (ICE) plays a crucial role in Electrophysiology (EP) and Structural Heart Disease (SHD) interventions by providing high-resolution, real-time imaging of cardiac structures. However, existing navigation methods rely on electromagnetic (EM) tracking, which is susceptible to interference and position drift, or require manual adjustments based on operator expertise. To overcome these limitations, we propose a novel anatomy-aware pose estimation system that determines the ICE catheter position and orientation solely from ICE images, eliminating the need for external tracking sensors. Our approach leverages a Vision Transformer (ViT)-based deep learning model, which captures spatial relationships between ICE images and anatomical structures. The model is trained on a clinically acquired dataset of 851 subjects, including ICE images paired with position and orientation labels normalized to the left atrium (LA) mesh. ICE images are patchified into 16x16 embeddings and processed through a transformer network, where a [CLS] token independently predicts position and orientation via separate linear layers. The model is optimized using a Mean Squared Error (MSE) loss function, balancing positional and orientational accuracy. Experimental results demonstrate an average positional error of 9.48 mm and orientation errors of (16.13 deg, 8.98 deg, 10.47 deg) across x, y, and z axes, confirming the model accuracy. Qualitative assessments further validate alignment between predicted and target views within 3D cardiac meshes. This AI-driven system enhances procedural efficiency, reduces operator workload, and enables real-time ICE catheter localization for tracking-free procedures. The proposed method can function independently or complement existing mapping systems like CARTO, offering a transformative approach to ICE-guided interventions.
AI-driven View Guidance System in Intra-cardiac Echocardiography Imaging
Sep 26, 2024



Intra-cardiac Echocardiography (ICE) is a crucial imaging modality used in electrophysiology (EP) and structural heart disease (SHD) interventions, providing real-time, high-resolution views from within the heart. Despite its advantages, effective manipulation of the ICE catheter requires significant expertise, which can lead to inconsistent outcomes, particularly among less experienced operators. To address this challenge, we propose an AI-driven closed-loop view guidance system with human-in-the-loop feedback, designed to assist users in navigating ICE imaging without requiring specialized knowledge. Our method models the relative position and orientation vectors between arbitrary views and clinically defined ICE views in a spatial coordinate system, guiding users on how to manipulate the ICE catheter to transition from the current view to the desired view over time. Operating in a closed-loop configuration, the system continuously predicts and updates the necessary catheter manipulations, ensuring seamless integration into existing clinical workflows. The effectiveness of the proposed system is demonstrated through a simulation-based evaluation, achieving an 89% success rate with the 6532 test dataset, highlighting its potential to improve the accuracy and efficiency of ICE imaging procedures.
AACessTalk: Fostering Communication between Minimally Verbal Autistic Children and Parents with Contextual Guidance and Card Recommendation
Sep 17, 2024



As minimally verbal autistic (MVA) children communicate with parents through few words and nonverbal cues, parents often struggle to encourage their children to express subtle emotions and needs and to grasp their nuanced signals. We present AACessTalk, a tablet-based, AI-mediated communication system that facilitates meaningful exchanges between an MVA child and a parent. AACessTalk provides real-time guides to the parent to engage the child in conversation and, in turn, recommends contextual vocabulary cards to the child. Through a two-week deployment study with 11 MVA child-parent dyads, we examine how AACessTalk fosters everyday conversation practice and mutual engagement. Our findings show high engagement from all dyads, leading to increased frequency of conversation and turn-taking. AACessTalk also encouraged parents to explore their own interaction strategies and empowered the children to have more agency in communication. We discuss the implications of designing technologies for balanced communication dynamics in parent-MVA child interaction.
ExploreSelf: Fostering User-driven Exploration and Reflection on Personal Challenges with Adaptive Guidance by Large Language Models
Sep 17, 2024Expressing stressful experiences in words is proven to improve mental and physical health, but individuals often disengage with writing interventions as they struggle to organize their thoughts and emotions. Reflective prompts have been used to provide direction, and large language models (LLMs) have demonstrated the potential to provide tailored guidance. Current systems often limit users' flexibility to direct their reflections. We thus present ExploreSelf, an LLM-driven application designed to empower users to control their reflective journey. ExploreSelf allows users to receive adaptive support through dynamically generated questions. Through an exploratory study with 19 participants, we examine how participants explore and reflect on personal challenges using ExploreSelf. Our findings demonstrate that participants valued the balance between guided support and freedom to control their reflective journey, leading to deeper engagement and insight. Building on our findings, we discuss implications for designing LLM-driven tools that promote user empowerment through effective reflective practices.
ELMI: Interactive and Intelligent Sign Language Translation of Lyrics for Song Signing
Sep 15, 2024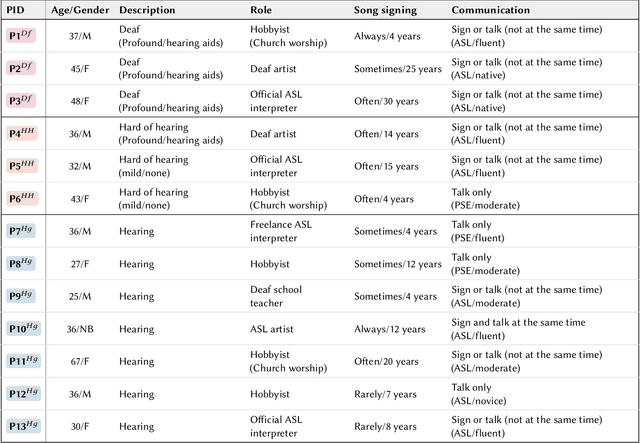


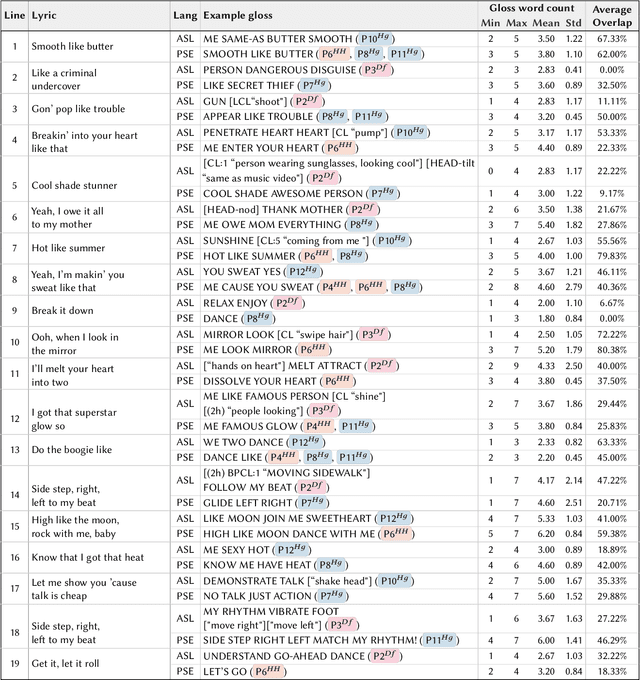
d/Deaf and hearing song-signers become prevalent on video-sharing platforms, but translating songs into sign language remains cumbersome and inaccessible. Our formative study revealed the challenges song-signers face, including semantic, syntactic, expressive, and rhythmic considerations in translations. We present ELMI, an accessible song-signing tool that assists in translating lyrics into sign language. ELMI enables users to edit glosses line-by-line, with real-time synced lyric highlighting and music video snippets. Users can also chat with a large language model-driven AI to discuss meaning, glossing, emoting, and timing. Through an exploratory study with 13 song-signers, we examined how ELMI facilitates their workflows and how song-signers leverage and receive an LLM-driven chat for translation. Participants successfully adopted ELMI to song-signing, with active discussions on the fly. They also reported improved confidence and independence in their translations, finding ELMI encouraging, constructive, and informative. We discuss design implications for leveraging LLMs in culturally sensitive song-signing translations.
Goal-conditioned reinforcement learning for ultrasound navigation guidance
May 02, 2024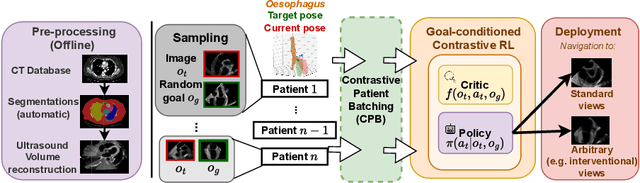
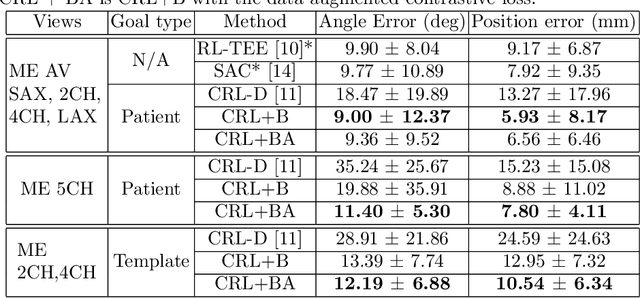
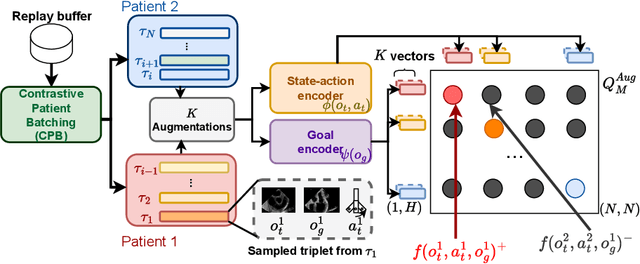
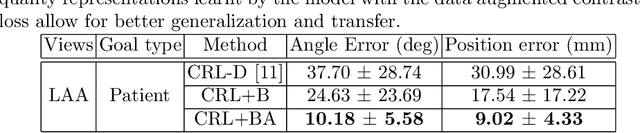
Transesophageal echocardiography (TEE) plays a pivotal role in cardiology for diagnostic and interventional procedures. However, using it effectively requires extensive training due to the intricate nature of image acquisition and interpretation. To enhance the efficiency of novice sonographers and reduce variability in scan acquisitions, we propose a novel ultrasound (US) navigation assistance method based on contrastive learning as goal-conditioned reinforcement learning (GCRL). We augment the previous framework using a novel contrastive patient batching method (CPB) and a data-augmented contrastive loss, both of which we demonstrate are essential to ensure generalization to anatomical variations across patients. The proposed framework enables navigation to both standard diagnostic as well as intricate interventional views with a single model. Our method was developed with a large dataset of 789 patients and obtained an average error of 6.56 mm in position and 9.36 degrees in angle on a testing dataset of 140 patients, which is competitive or superior to models trained on individual views. Furthermore, we quantitatively validate our method's ability to navigate to interventional views such as the Left Atrial Appendage (LAA) view used in LAA closure. Our approach holds promise in providing valuable guidance during transesophageal ultrasound examinations, contributing to the advancement of skill acquisition for cardiac ultrasound practitioners.
Understanding the Impact of Long-Term Memory on Self-Disclosure with Large Language Model-Driven Chatbots for Public Health Intervention
Feb 17, 2024Recent large language models (LLMs) offer the potential to support public health monitoring by facilitating health disclosure through open-ended conversations but rarely preserve the knowledge gained about individuals across repeated interactions. Augmenting LLMs with long-term memory (LTM) presents an opportunity to improve engagement and self-disclosure, but we lack an understanding of how LTM impacts people's interaction with LLM-driven chatbots in public health interventions. We examine the case of CareCall -- an LLM-driven voice chatbot with LTM -- through the analysis of 1,252 call logs and interviews with nine users. We found that LTM enhanced health disclosure and fostered positive perceptions of the chatbot by offering familiarity. However, we also observed challenges in promoting self-disclosure through LTM, particularly around addressing chronic health conditions and privacy concerns. We discuss considerations for LTM integration in LLM-driven chatbots for public health monitoring, including carefully deciding what topics need to be remembered in light of public health goals.
* Accepted to ACM CHI 2024 as a full paper
Cardiac ultrasound simulation for autonomous ultrasound navigation
Feb 09, 2024



Ultrasound is well-established as an imaging modality for diagnostic and interventional purposes. However, the image quality varies with operator skills as acquiring and interpreting ultrasound images requires extensive training due to the imaging artefacts, the range of acquisition parameters and the variability of patient anatomies. Automating the image acquisition task could improve acquisition reproducibility and quality but training such an algorithm requires large amounts of navigation data, not saved in routine examinations. Thus, we propose a method to generate large amounts of ultrasound images from other modalities and from arbitrary positions, such that this pipeline can later be used by learning algorithms for navigation. We present a novel simulation pipeline which uses segmentations from other modalities, an optimized volumetric data representation and GPU-accelerated Monte Carlo path tracing to generate view-dependent and patient-specific ultrasound images. We extensively validate the correctness of our pipeline with a phantom experiment, where structures' sizes, contrast and speckle noise properties are assessed. Furthermore, we demonstrate its usability to train neural networks for navigation in an echocardiography view classification experiment by generating synthetic images from more than 1000 patients. Networks pre-trained with our simulations achieve significantly superior performance in settings where large real datasets are not available, especially for under-represented classes. The proposed approach allows for fast and accurate patient-specific ultrasound image generation, and its usability for training networks for navigation-related tasks is demonstrated.