 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCritic: A Symbolic Evaluator for 3D Indoor Scene Synthesis
Apr 14, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) increasingly generate indoor scenes through intermediate structures such as layouts and scene graphs, yet evaluation still relies on LLM or VLM judges that score rendered views, making judgments sensitive to viewpoint, prompt phrasing, and hallucination. When the evaluator is unstable, it becomes difficult to determine whether a model has produced a spatially plausible scene or whether the output score reflects the choice of viewpoint, rendering, or prompt. We introduce SceneCritic, a symbolic evaluator for floor-plan-level layouts. SceneCritic's constraints are grounded in SceneOnto, a structured spatial ontology we construct by aggregating indoor scene priors from 3D-FRONT, ScanNet, and Visual Genome. SceneOnto traverses this ontology to jointly verify semantic, orientation, and geometric coherence across object relationships, providing object-level and relationship-level assessments that identify specific violations and successful placements. Furthermore, we pair SceneCritic with an iterative refinement test bed that probes how models build and revise spatial structure under different critic modalities: a rule-based critic using collision constraints as feedback, an LLM critic operating on the layout as text, and a VLM critic operating on rendered observations. Through extensive experiments, we show that (a) SceneCritic aligns substantially better with human judgments than VLM-based evaluators, (b) text-only LLMs can outperform VLMs on semantic layout quality, and (c) image-based VLM refinement is the most effective critic modality for semantic and orientation correction.
Text to Blind Motion
Dec 06, 2024

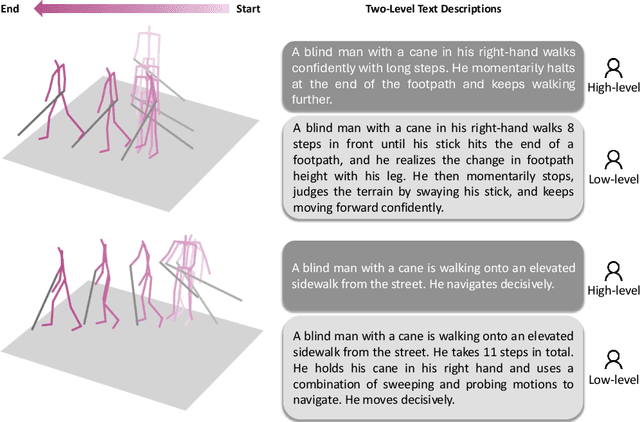
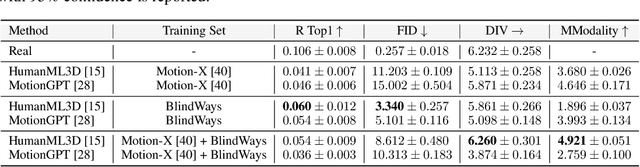
People who are blind perceive the world differently than those who are sighted, which can result in distinct motion characteristics. For instance, when crossing at an intersection, blind individuals may have different patterns of movement, such as veering more from a straight path or using touch-based exploration around curbs and obstacles. These behaviors may appear less predictable to motion models embedded in technologies such as autonomous vehicles. Yet, the ability of 3D motion models to capture such behavior has not been previously studied, as existing datasets for 3D human motion currently lack diversity and are biased toward people who are sighted. In this work, we introduce BlindWays, the first multimodal motion benchmark for pedestrians who are blind. We collect 3D motion data using wearable sensors with 11 blind participants navigating eight different routes in a real-world urban setting. Additionally, we provide rich textual descriptions that capture the distinctive movement characteristics of blind pedestrians and their interactions with both the navigation aid (e.g., a white cane or a guide dog) and the environment. We benchmark state-of-the-art 3D human prediction models, finding poor performance with off-the-shelf and pre-training-based methods for our novel task. To contribute toward safer and more reliable systems that can seamlessly reason over diverse human movements in their environments, our text-and-motion benchmark is available at https://blindways.github.io.
UniLCD: Unified Local-Cloud Decision-Making via Reinforcement Learning
Sep 17, 2024



Embodied vision-based real-world systems, such as mobile robots, require a careful balance between energy consumption, compute latency, and safety constraints to optimize operation across dynamic tasks and contexts. As local computation tends to be restricted, offloading the computation, ie, to a remote server, can save local resources while providing access to high-quality predictions from powerful and large models. However, the resulting communication and latency overhead has led to limited usability of cloud models in dynamic, safety-critical, real-time settings. To effectively address this trade-off, we introduce UniLCD, a novel hybrid inference framework for enabling flexible local-cloud collaboration. By efficiently optimizing a flexible routing module via reinforcement learning and a suitable multi-task objective, UniLCD is specifically designed to support the multiple constraints of safety-critical end-to-end mobile systems. We validate the proposed approach using a challenging, crowded navigation task requiring frequent and timely switching between local and cloud operations. UniLCD demonstrates improved overall performance and efficiency, by over 35% compared to state-of-the-art baselines based on various split computing and early exit strategies.