 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessShare: Co-designing Data Access and Sharing with Blind People
Jul 27, 2024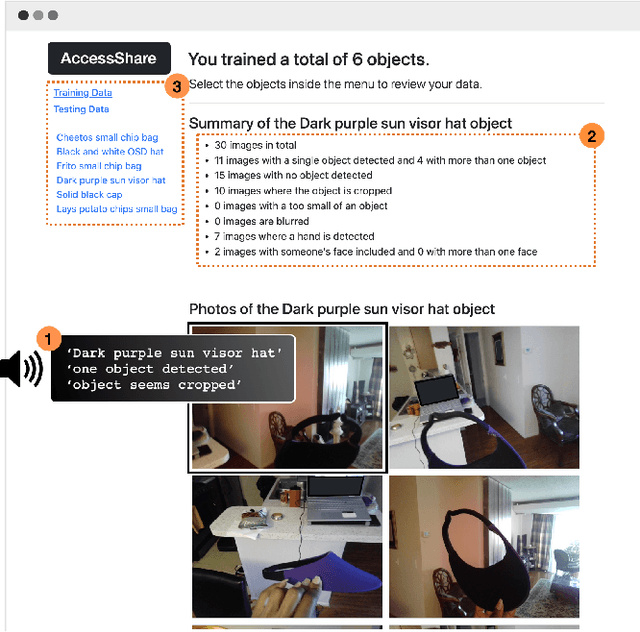
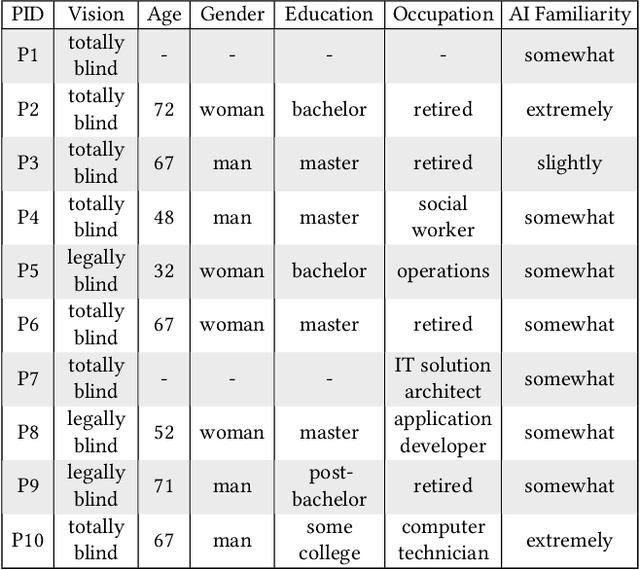
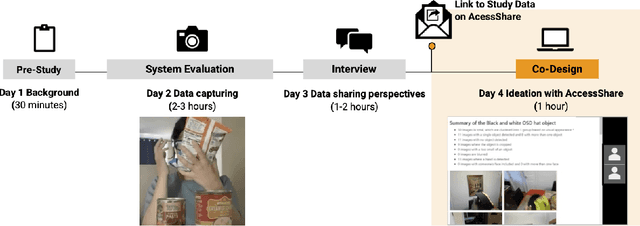
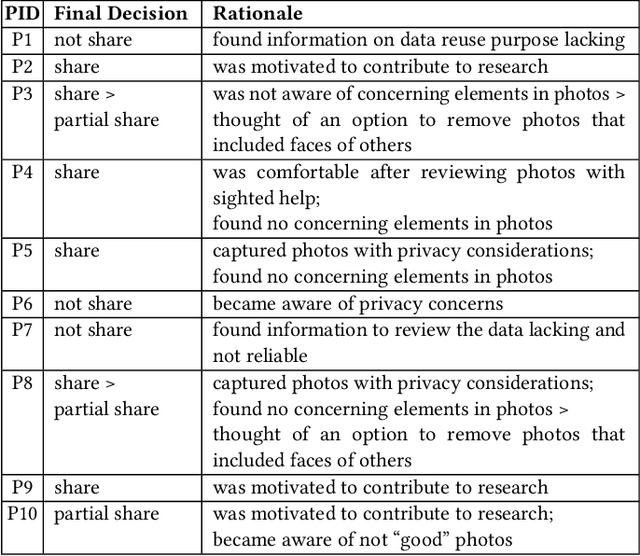
Blind people are often called to contribute image data to datasets for AI innovation with the hope for future accessibility and inclusion. Yet, the visual inspection of the contributed images is inaccessible. To this day, we lack mechanisms for data inspection and control that are accessible to the blind community. To address this gap, we engage 10 blind participants in a scenario where they wear smartglasses and collect image data using an AI-infused application in their homes. We also engineer a design probe, a novel data access interface called AccessShare, and conduct a co-design study to discuss participants' needs, preferences, and ideas on consent, data inspection, and control. Our findings reveal the impact of interactive informed consent and the complementary role of data inspection systems such as AccessShare in facilitating communication between data stewards and blind data contributors. We discuss how key insights can guide future informed consent and data control to promote inclusive and responsible data practices in AI.
What's Different between Visual Question Answering for Machine "Understanding" Versus for Accessibility?
Oct 26, 2022



In visual question answering (VQA), a machine must answer a question given an associated image. Recently, accessibility researchers have explored whether VQA can be deployed in a real-world setting where users with visual impairments learn about their environment by capturing their visual surroundings and asking questions. However, most of the existing benchmarking datasets for VQA focus on machine "understanding" and it remains unclear how progress on those datasets corresponds to improvements in this real-world use case. We aim to answer this question by evaluating discrepancies between machine "understanding" datasets (VQA-v2) and accessibility datasets (VizWiz) by evaluating a variety of VQA models. Based on our findings, we discuss opportunities and challenges in VQA for accessibility and suggest directions for future work.
Blind Users Accessing Their Training Images in Teachable Object Recognizers
Aug 16, 2022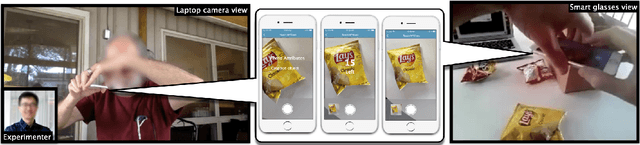

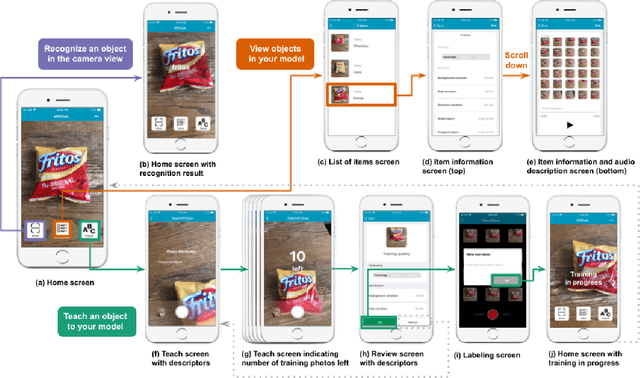

Iteration of training and evaluating a machine learning model is an important process to improve its performance. However, while teachable interfaces enable blind users to train and test an object recognizer with photos taken in their distinctive environment, accessibility of training iteration and evaluation steps has received little attention. Iteration assumes visual inspection of the training photos, which is inaccessible for blind users. We explore this challenge through MyCam, a mobile app that incorporates automatically estimated descriptors for non-visual access to the photos in the users' training sets. We explore how blind participants (N=12) interact with MyCam and the descriptors through an evaluation study in their homes. We demonstrate that the real-time photo-level descriptors enabled blind users to reduce photos with cropped objects, and that participants could add more variations by iterating through and accessing the quality of their training sets. Also, Participants found the app simple to use indicating that they could effectively train it and that the descriptors were useful. However, subjective responses were not reflected in the performance of their models, partially due to little variation in training and cluttered backgrounds.
Pedestrian Detection with Wearable Cameras for the Blind: A Two-way Perspective
Mar 26, 2020

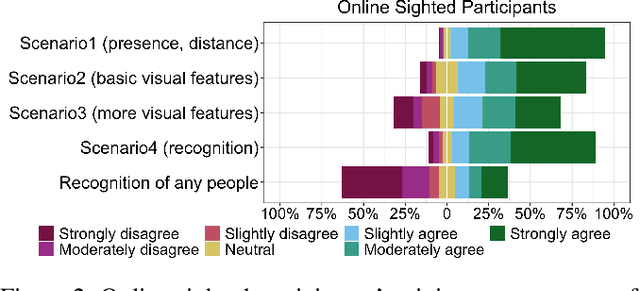

Blind people have limited access to information about their surroundings, which is important for ensuring one's safety, managing social interactions, and identifying approaching pedestrians. With advances in computer vision, wearable cameras can provide equitable access to such information. However, the always-on nature of these assistive technologies poses privacy concerns for parties that may get recorded. We explore this tension from both perspectives, those of sighted passersby and blind users, taking into account camera visibility, in-person versus remote experience, and extracted visual information. We conduct two studies: an online survey with MTurkers (N=206) and an in-person experience study between pairs of blind (N=10) and sighted (N=40) participants, where blind participants wear a working prototype for pedestrian detection and pass by sighted participants. Our results suggest that both of the perspectives of users and bystanders and the several factors mentioned above need to be carefully considered to mitigate potential social tensions.
Hand-Priming in Object Localization for Assistive Egocentric Vision
Feb 28, 2020
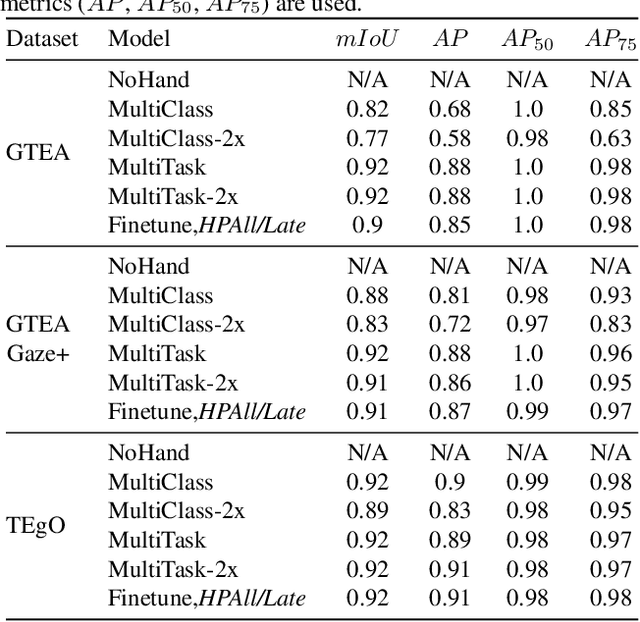
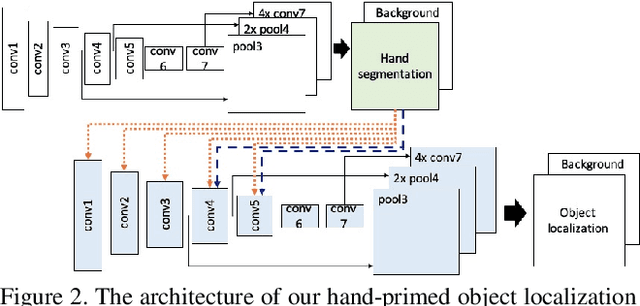
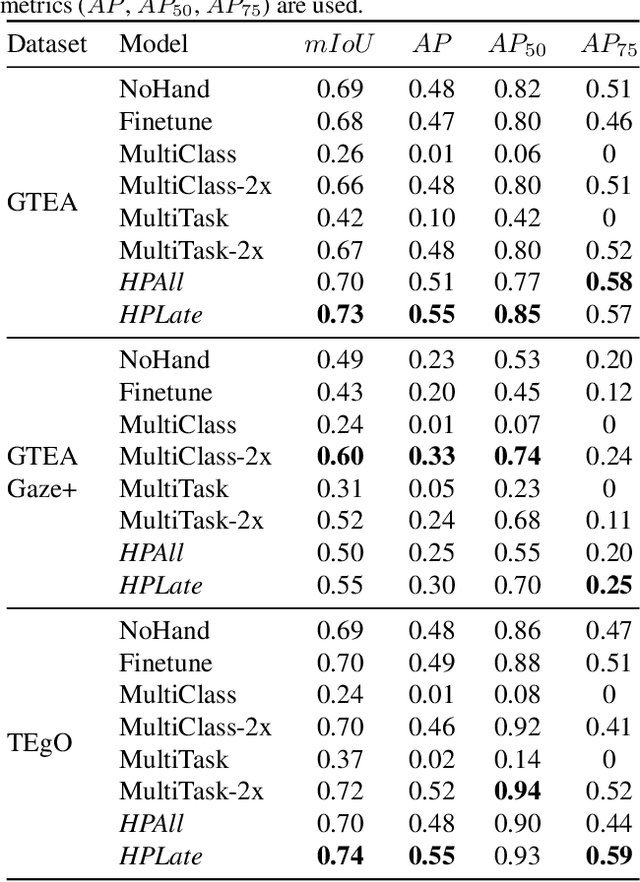
Egocentric vision holds great promises for increasing access to visual information and improving the quality of life for people with visual impairments, with object recognition being one of the daily challenges for this population. While we strive to improve recognition performance, it remains difficult to identify which object is of interest to the user; the object may not even be included in the frame due to challenges in camera aiming without visual feedback. Also, gaze information, commonly used to infer the area of interest in egocentric vision, is often not dependable. However, blind users often tend to include their hand either interacting with the object that they wish to recognize or simply placing it in proximity for better camera aiming. We propose localization models that leverage the presence of the hand as the contextual information for priming the center area of the object of interest. In our approach, hand segmentation is fed to either the entire localization network or its last convolutional layers. Using egocentric datasets from sighted and blind individuals, we show that the hand-priming achieves higher precision than other approaches, such as fine-tuning, multi-class, and multi-task learning, which also encode hand-object interactions in localization.
Crowdsourcing the Perception of Machine Teaching
Feb 05, 2020
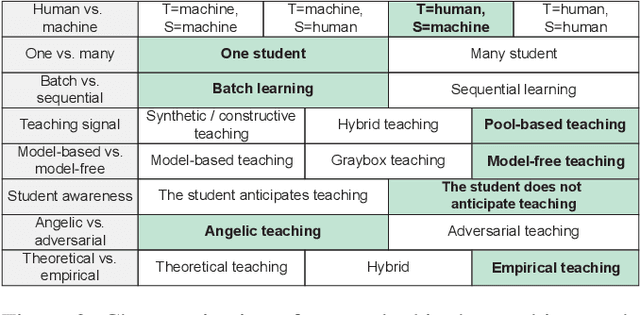
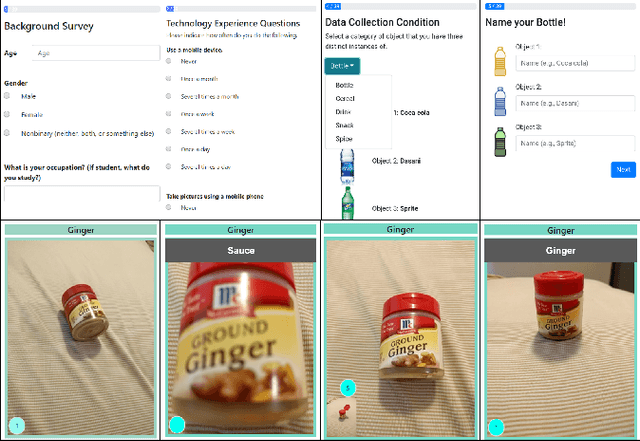
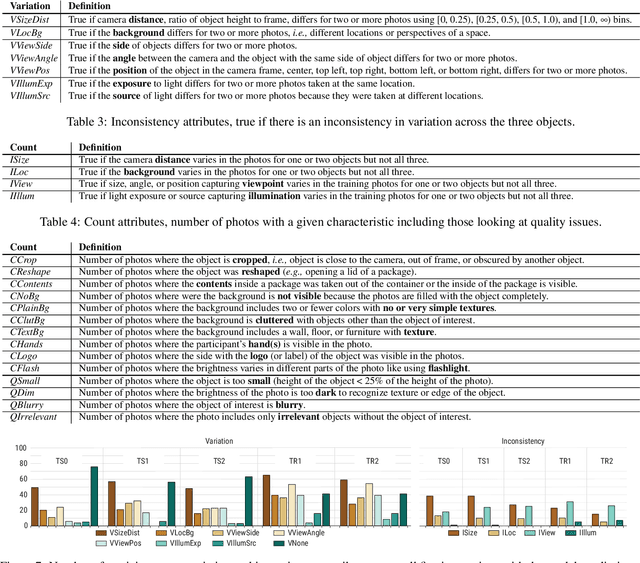
Teachable interfaces can empower end-users to attune machine learning systems to their idiosyncratic characteristics and environment by explicitly providing pertinent training examples. While facilitating control, their effectiveness can be hindered by the lack of expertise or misconceptions. We investigate how users may conceptualize, experience, and reflect on their engagement in machine teaching by deploying a mobile teachable testbed in Amazon Mechanical Turk. Using a performance-based payment scheme, Mechanical Turkers (N = 100) are called to train, test, and re-train a robust recognition model in real-time with a few snapshots taken in their environment. We find that participants incorporate diversity in their examples drawing from parallels to how humans recognize objects independent of size, viewpoint, location, and illumination. Many of their misconceptions relate to consistency and model capabilities for reasoning. With limited variation and edge cases in testing, the majority of them do not change strategies on a second training attempt.
* 10 pages, 8 figures, 5 tables, CHI2020 conference
Texture Synthesis with Recurrent Variational Auto-Encoder
Dec 23, 2017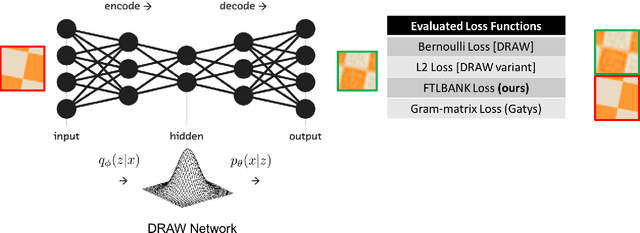

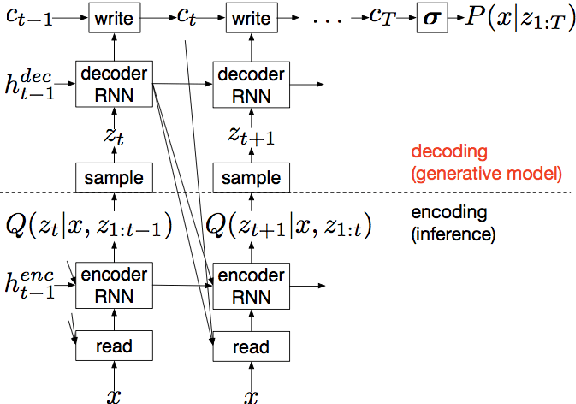

We propose a recurrent variational auto-encoder for texture synthesis. A novel loss function, FLTBNK, is used for training the texture synthesizer. It is rotational and partially color invariant loss function. Unlike L2 loss, FLTBNK explicitly models the correlation of color intensity between pixels. Our texture synthesizer generates neighboring tiles to expand a sample texture and is evaluated using various texture patterns from Describable Textures Dataset (DTD). We perform both quantitative and qualitative experiments with various loss functions to evaluate the performance of our proposed loss function (FLTBNK) --- a mini-human subject study is used for the qualitative evaluation.