 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing the Perception of Machine Teaching
Paper and Code
Feb 05, 2020
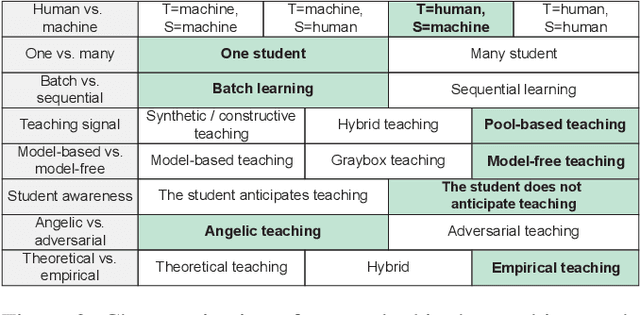
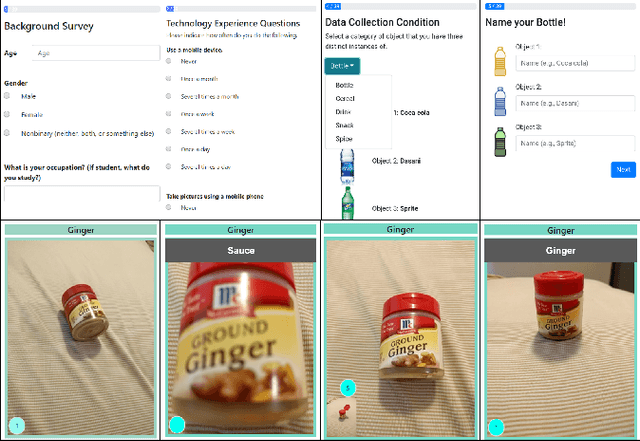
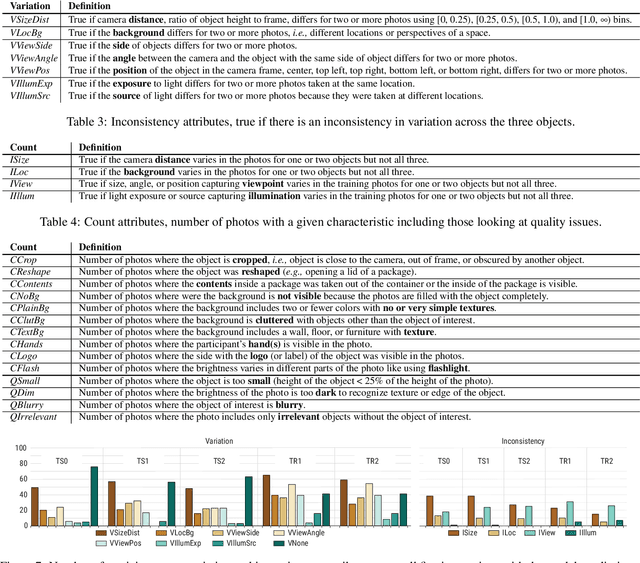
Teachable interfaces can empower end-users to attune machine learning systems to their idiosyncratic characteristics and environment by explicitly providing pertinent training examples. While facilitating control, their effectiveness can be hindered by the lack of expertise or misconceptions. We investigate how users may conceptualize, experience, and reflect on their engagement in machine teaching by deploying a mobile teachable testbed in Amazon Mechanical Turk. Using a performance-based payment scheme, Mechanical Turkers (N = 100) are called to train, test, and re-train a robust recognition model in real-time with a few snapshots taken in their environment. We find that participants incorporate diversity in their examples drawing from parallels to how humans recognize objects independent of size, viewpoint, location, and illumination. Many of their misconceptions relate to consistency and model capabilities for reasoning. With limited variation and edge cases in testing, the majority of them do not change strategies on a second training attempt.