 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot-Assisted Group Tours for Blind People
Feb 04, 2026Group interactions are essential to social functioning, yet effective engagement relies on the ability to recognize and interpret visual cues, making such engagement a significant challenge for blind people. In this paper, we investigate how a mobile robot can support group interactions for blind people. We used the scenario of a guided tour with mixed-visual groups involving blind and sighted visitors. Based on insights from an interview study with blind people (n=5) and museum experts (n=5), we designed and prototyped a robotic system that supported blind visitors to join group tours. We conducted a field study in a science museum where each blind participant (n=8) joined a group tour with one guide and two sighted participants (n=8). Findings indicated users' sense of safety from the robot's navigational support, concerns in the group participation, and preferences for obtaining environmental information. We present design implications for future robotic systems to support blind people's mixed-visual group participation.
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
May 11, 2024

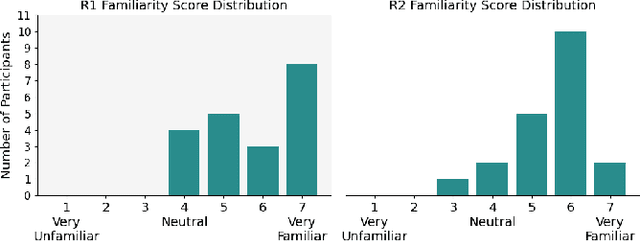
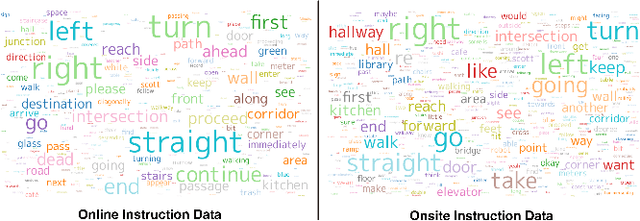
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.
TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data
Sep 29, 2023



Social navigation and pedestrian behavior research has shifted towards machine learning-based methods and converged on the topic of modeling inter-pedestrian interactions and pedestrian-robot interactions. For this, large-scale datasets that contain rich information are needed. We describe a portable data collection system, coupled with a semi-autonomous labeling pipeline. As part of the pipeline, we designed a label correction web app that facilitates human verification of automated pedestrian tracking outcomes. Our system enables large-scale data collection in diverse environments and fast trajectory label production. Compared with existing pedestrian data collection methods, our system contains three components: a combination of top-down and ego-centric views, natural human behavior in the presence of a socially appropriate "robot", and human-verified labels grounded in the metric space. To the best of our knowledge, no prior data collection system has a combination of all three components. We further introduce our ever-expanding dataset from the ongoing data collection effort -- the TBD Pedestrian Dataset and show that our collected data is larger in scale, contains richer information when compared to prior datasets with human-verified labels, and supports new research opportunities.
Pedestrian Detection with Wearable Cameras for the Blind: A Two-way Perspective
Mar 26, 2020

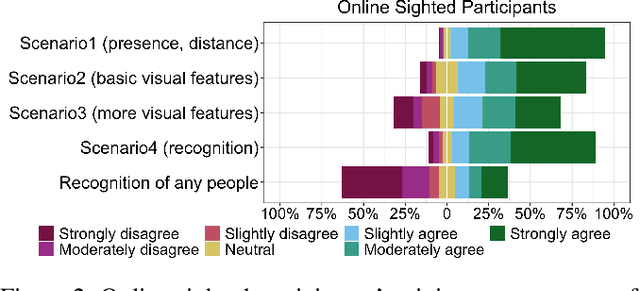

Blind people have limited access to information about their surroundings, which is important for ensuring one's safety, managing social interactions, and identifying approaching pedestrians. With advances in computer vision, wearable cameras can provide equitable access to such information. However, the always-on nature of these assistive technologies poses privacy concerns for parties that may get recorded. We explore this tension from both perspectives, those of sighted passersby and blind users, taking into account camera visibility, in-person versus remote experience, and extracted visual information. We conduct two studies: an online survey with MTurkers (N=206) and an in-person experience study between pairs of blind (N=10) and sighted (N=40) participants, where blind participants wear a working prototype for pedestrian detection and pass by sighted participants. Our results suggest that both of the perspectives of users and bystanders and the several factors mentioned above need to be carefully considered to mitigate potential social tensions.