 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCrowd: Hierarchical Crowd Flow Alignment for Dense Human Environments
Feb 05, 2026Navigating through dense human crowds remains a significant challenge for mobile robots. A key issue is the freezing robot problem, where the robot struggles to find safe motions and becomes stuck within the crowd. To address this, we propose HiCrowd, a hierarchical framework that integrates reinforcement learning (RL) with model predictive control (MPC). HiCrowd leverages surrounding pedestrian motion as guidance, enabling the robot to align with compatible crowd flows. A high-level RL policy generates a follow point to align the robot with a suitable pedestrian group, while a low-level MPC safely tracks this guidance with short horizon planning. The method combines long-term crowd aware decision making with safe short-term execution. We evaluate HiCrowd against reactive and learning-based baselines in offline setting (replaying recorded human trajectories) and online setting (human trajectories are updated to react to the robot in simulation). Experiments on a real-world dataset and a synthetic crowd dataset show that our method outperforms in navigation efficiency and safety, while reducing freezing behaviors. Our results suggest that leveraging human motion as guidance, rather than treating humans solely as dynamic obstacles, provides a powerful principle for safe and efficient robot navigation in crowds.
Robot-Assisted Group Tours for Blind People
Feb 04, 2026Group interactions are essential to social functioning, yet effective engagement relies on the ability to recognize and interpret visual cues, making such engagement a significant challenge for blind people. In this paper, we investigate how a mobile robot can support group interactions for blind people. We used the scenario of a guided tour with mixed-visual groups involving blind and sighted visitors. Based on insights from an interview study with blind people (n=5) and museum experts (n=5), we designed and prototyped a robotic system that supported blind visitors to join group tours. We conducted a field study in a science museum where each blind participant (n=8) joined a group tour with one guide and two sighted participants (n=8). Findings indicated users' sense of safety from the robot's navigational support, concerns in the group participation, and preferences for obtaining environmental information. We present design implications for future robotic systems to support blind people's mixed-visual group participation.
How Does Delegation in Social Interaction Evolve Over Time? Navigation with a Robot for Blind People
Jan 27, 2026Autonomy and independent navigation are vital to daily life but remain challenging for individuals with blindness. Robotic systems can enhance mobility and confidence by providing intelligent navigation assistance. However, fully autonomous systems may reduce users' sense of control, even when they wish to remain actively involved. Although collaboration between user and robot has been recognized as important, little is known about how perceptions of this relationship change with repeated use. We present a repeated exposure study with six blind participants who interacted with a navigation-assistive robot in a real-world museum. Participants completed tasks such as navigating crowds, approaching lines, and encountering obstacles. Findings show that participants refined their strategies over time, developing clearer preferences about when to rely on the robot versus act independently. This work provides insights into how strategies and preferences evolve with repeated interaction and offers design implications for robots that adapt to user needs over time.
Beyond Omakase: Designing Shared Control for Navigation Robots with Blind People
Mar 31, 2025



Autonomous navigation robots can increase the independence of blind people but often limit user control, following what is called in Japanese an "omakase" approach where decisions are left to the robot. This research investigates ways to enhance user control in social robot navigation, based on two studies conducted with blind participants. The first study, involving structured interviews (N=14), identified crowded spaces as key areas with significant social challenges. The second study (N=13) explored navigation tasks with an autonomous robot in these environments and identified design strategies across different modes of autonomy. Participants preferred an active role, termed the "boss" mode, where they managed crowd interactions, while the "monitor" mode helped them assess the environment, negotiate movements, and interact with the robot. These findings highlight the importance of shared control and user involvement for blind users, offering valuable insights for designing future social navigation robots.
Memory-Maze: Scenario Driven Benchmark and Visual Language Navigation Model for Guiding Blind People
May 11, 2024

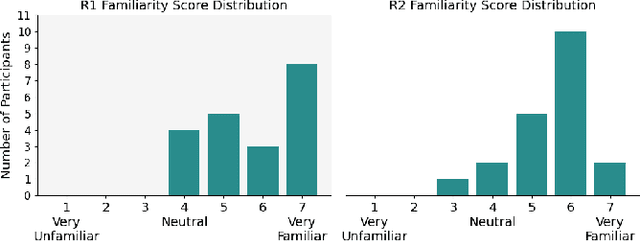
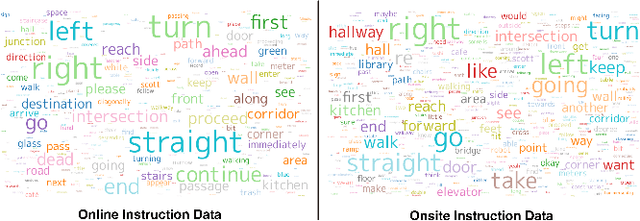
Visual Language Navigation (VLN) powered navigation robots have the potential to guide blind people by understanding and executing route instructions provided by sighted passersby. This capability allows robots to operate in environments that are often unknown a priori. Existing VLN models are insufficient for the scenario of navigation guidance for blind people, as they need to understand routes described from human memory, which frequently contain stutters, errors, and omission of details as opposed to those obtained by thinking out loud, such as in the Room-to-Room dataset. However, currently, there is no benchmark that simulates instructions that were obtained from human memory in environments where blind people navigate. To this end, we present our benchmark, Memory-Maze, which simulates the scenario of seeking route instructions for guiding blind people. Our benchmark contains a maze-like structured virtual environment and novel route instruction data from human memory. To collect natural language instructions, we conducted two studies from sighted passersby onsite and annotators online. Our analysis demonstrates that instructions data collected onsite were more lengthy and contained more varied wording. Alongside our benchmark, we propose a VLN model better equipped to handle the scenario. Our proposed VLN model uses Large Language Models (LLM) to parse instructions and generate Python codes for robot control. We further show that the existing state-of-the-art model performed suboptimally on our benchmark. In contrast, our proposed method outperformed the state-of-the-art model by a fair margin. We found that future research should exercise caution when considering VLN technology for practical applications, as real-world scenarios have different characteristics than ones collected in traditional settings.
TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data
Sep 29, 2023



Social navigation and pedestrian behavior research has shifted towards machine learning-based methods and converged on the topic of modeling inter-pedestrian interactions and pedestrian-robot interactions. For this, large-scale datasets that contain rich information are needed. We describe a portable data collection system, coupled with a semi-autonomous labeling pipeline. As part of the pipeline, we designed a label correction web app that facilitates human verification of automated pedestrian tracking outcomes. Our system enables large-scale data collection in diverse environments and fast trajectory label production. Compared with existing pedestrian data collection methods, our system contains three components: a combination of top-down and ego-centric views, natural human behavior in the presence of a socially appropriate "robot", and human-verified labels grounded in the metric space. To the best of our knowledge, no prior data collection system has a combination of all three components. We further introduce our ever-expanding dataset from the ongoing data collection effort -- the TBD Pedestrian Dataset and show that our collected data is larger in scale, contains richer information when compared to prior datasets with human-verified labels, and supports new research opportunities.
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022



Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
Group-based Motion Prediction for Navigation in Crowded Environments
Aug 19, 2021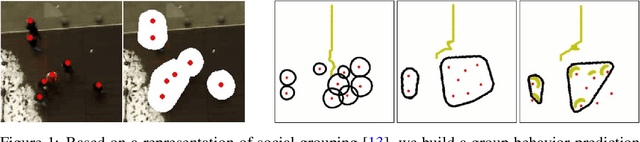
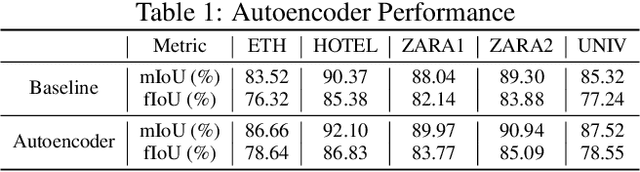
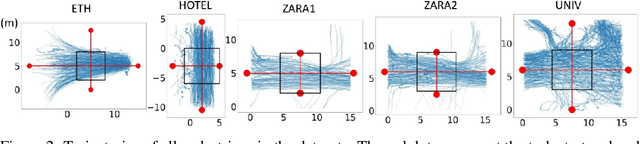
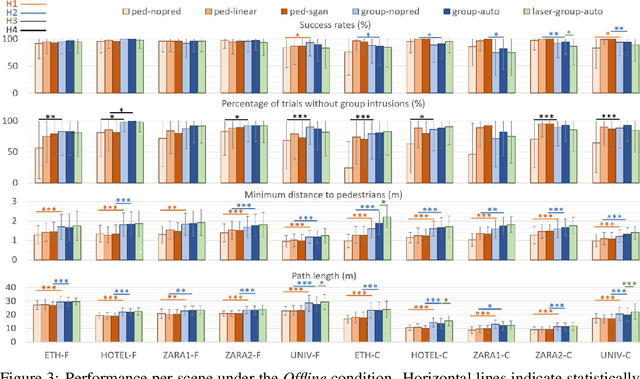
We focus on the problem of planning the motion of a robot in a dynamic multiagent environment such as a pedestrian scene. Enabling the robot to navigate safely and in a socially compliant fashion in such scenes requires a representation that accounts for the unfolding multiagent dynamics. Existing approaches to this problem tend to employ microscopic models of motion prediction that reason about the individual behavior of other agents. While such models may achieve high tracking accuracy in trajectory prediction benchmarks, they often lack an understanding of the group structures unfolding in crowded scenes. Inspired by the Gestalt theory from psychology, we build a Model Predictive Control framework (G-MPC) that leverages group-based prediction for robot motion planning. We conduct an extensive simulation study involving a series of challenging navigation tasks in scenes extracted from two real-world pedestrian datasets. We illustrate that G-MPC enables a robot to achieve statistically significantly higher safety and lower number of group intrusions than a series of baselines featuring individual pedestrian motion prediction models. Finally, we show that G-MPC can handle noisy lidar-scan estimates without significant performance losses.
Core Challenges of Social Robot Navigation: A Survey
Mar 17, 2021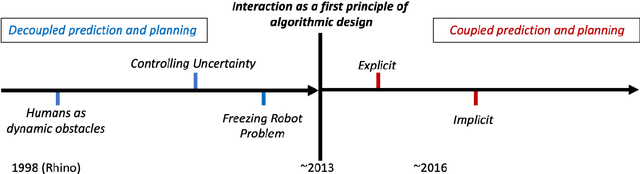



Robot navigation in crowded public spaces is a complex task that requires addressing a variety of engineering and human factors challenges. These challenges have motivated a great amount of research resulting in important developments for the fields of robotics and human-robot interaction over the past three decades. Despite the significant progress and the massive recent interest, we observe a number of significant remaining challenges that prohibit the seamless deployment of autonomous robots in public pedestrian environments. In this survey article, we organize existing challenges into a set of categories related to broader open problems in motion planning, behavior design, and evaluation methodologies. Within these categories, we review past work, and offer directions for future research. Our work builds upon and extends earlier survey efforts by a) taking a critical perspective and diagnosing fundamental limitations of adopted practices in the field and b) offering constructive feedback and ideas that we aspire will drive research in the field over the coming decade.
SocNavBench: A Grounded Simulation Testing Framework for Evaluating Social Navigation
Feb 26, 2021
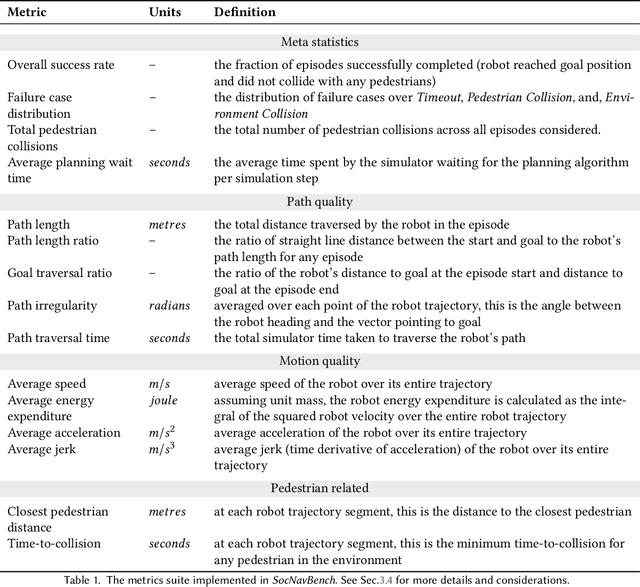


The human-robot interaction (HRI) community has developed many methods for robots to navigate safely and socially alongside humans. However, experimental procedures to evaluate these works are usually constructed on a per-method basis. Such disparate evaluations make it difficult to compare the performance of such methods across the literature. To bridge this gap, we introduce SocNavBench, a simulation framework for evaluating social navigation algorithms. SocNavBench comprises a simulator with photo-realistic capabilities and curated social navigation scenarios grounded in real-world pedestrian data. We also provide an implementation of a suite of metrics to quantify the performance of navigation algorithms on these scenarios. Altogether, SocNavBench provides a test framework for evaluating disparate social navigation methods in a consistent and interpretable manner. To illustrate its use, we demonstrate testing three existing social navigation methods and a baseline method on SocNavBench, showing how the suite of metrics helps infer their performance trade-offs. Our code is open-source, allowing the addition of new scenarios and metrics by the community to help evolve SocNavBench to reflect advancements in our understanding of social navigation.