 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Drivers' Risk Perception via Attention to Improve Driving Assistance
Sep 07, 2024Advanced Driver Assistance Systems (ADAS) alert drivers during safety-critical scenarios but often provide superfluous alerts due to a lack of consideration for drivers' knowledge or scene awareness. Modeling these aspects together in a data-driven way is challenging due to the scarcity of critical scenario data with in-cabin driver state and world state recorded together. We explore the benefits of driver modeling in the context of Forward Collision Warning (FCW) systems. Working with real-world video dataset of on-road FCW deployments, we collect observers' subjective validity rating of the deployed alerts. We also annotate participants' gaze-to-objects and extract 3D trajectories of the ego vehicle and other vehicles semi-automatically. We generate a risk estimate of the scene and the drivers' perception in a two step process: First, we model the movement of vehicles in a given scenario as a joint trajectory forecasting problem. Then, we reason about the drivers' risk perception of the scene by counterfactually modifying the input to the forecasting model to represent the drivers' actual observations of vehicles in the scene. The difference in these behaviours gives us an estimate of driver behaviour that accounts for their actual (inattentive) observations and their downstream effect on overall scene risk. We compare both a learned scene representation as well as a more traditional ``worse-case'' deceleration model to achieve the future trajectory forecast. Our experiments show that using this risk formulation to generate FCW alerts may lead to improved false positive rate of FCWs and improved FCW timing.
Object Importance Estimation using Counterfactual Reasoning for Intelligent Driving
Dec 05, 2023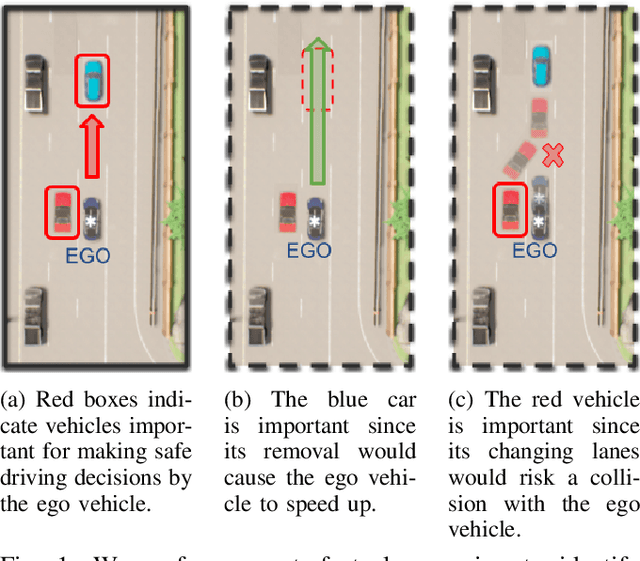
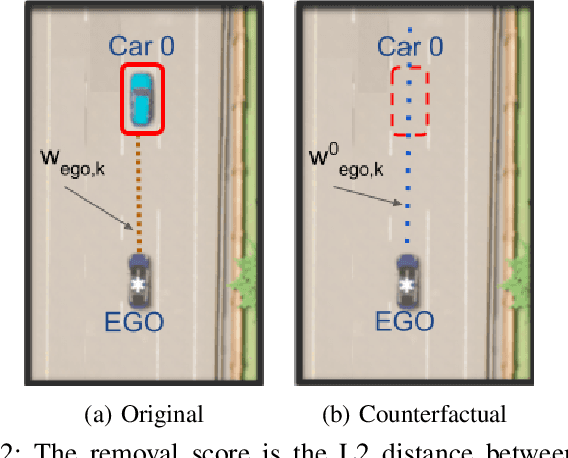
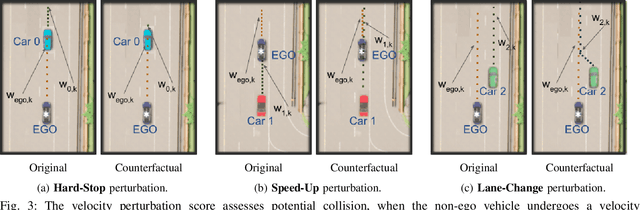
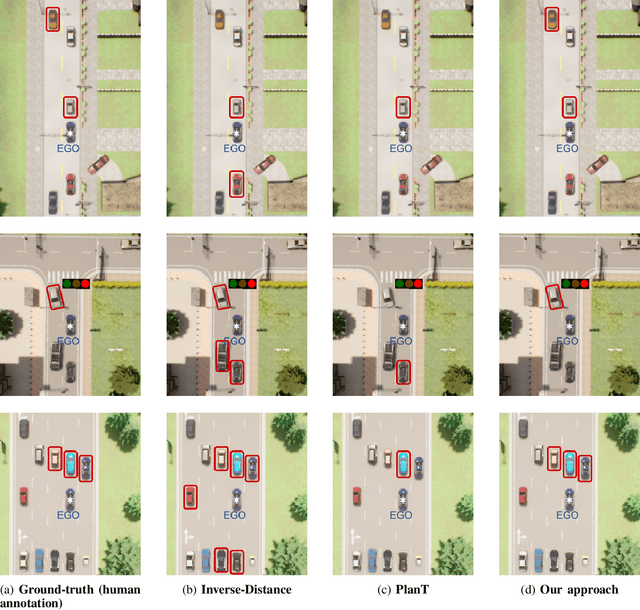
The ability to identify important objects in a complex and dynamic driving environment is essential for autonomous driving agents to make safe and efficient driving decisions. It also helps assistive driving systems decide when to alert drivers. We tackle object importance estimation in a data-driven fashion and introduce HOIST - Human-annotated Object Importance in Simulated Traffic. HOIST contains driving scenarios with human-annotated importance labels for vehicles and pedestrians. We additionally propose a novel approach that relies on counterfactual reasoning to estimate an object's importance. We generate counterfactual scenarios by modifying the motion of objects and ascribe importance based on how the modifications affect the ego vehicle's driving. Our approach outperforms strong baselines for the task of object importance estimation on HOIST. We also perform ablation studies to justify our design choices and show the significance of the different components of our proposed approach.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022



Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
DReyeVR: Democratizing Virtual Reality Driving Simulation for Behavioural & Interaction Research
Jan 07, 2022
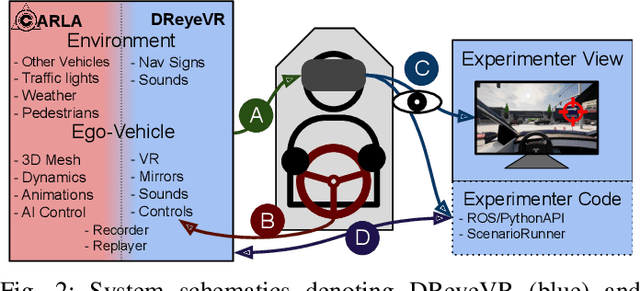
Simulators are an essential tool for behavioural and interaction research on driving, due to the safety, cost, and experimental control issues of on-road driving experiments. The most advanced simulators use expensive 360 degree projections systems to ensure visual fidelity, full field of view, and immersion. However, similar visual fidelity can be achieved affordably using a virtual reality (VR) based visual interface. We present DReyeVR, an open-source VR based driving simulator platform designed with behavioural and interaction research priorities in mind. DReyeVR (read "driver") is based on Unreal Engine and the CARLA autonomous vehicle simulator and has features such as eye tracking, a functional driving heads-up display (HUD) and vehicle audio, custom definable routes and traffic scenarios, experimental logging, replay capabilities, and compatibility with ROS. We describe the hardware required to deploy this simulator for under $5000$ USD, much cheaper than commercially available simulators. Finally, we describe how DReyeVR may be leveraged to answer an interaction research question in an example scenario.
SocNavBench: A Grounded Simulation Testing Framework for Evaluating Social Navigation
Feb 26, 2021
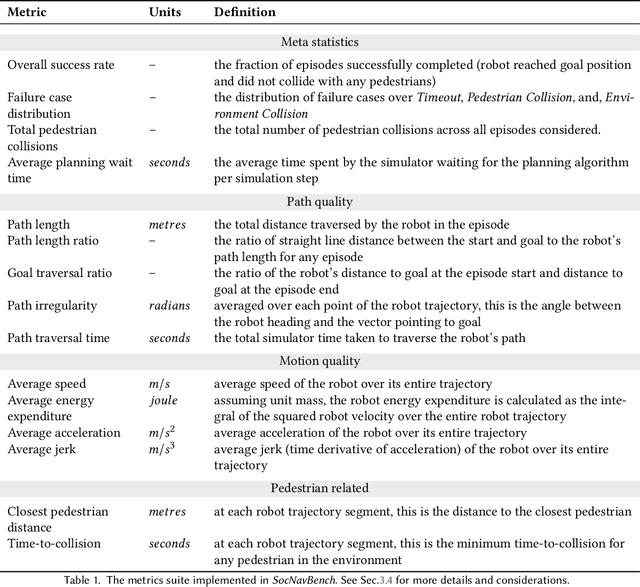


The human-robot interaction (HRI) community has developed many methods for robots to navigate safely and socially alongside humans. However, experimental procedures to evaluate these works are usually constructed on a per-method basis. Such disparate evaluations make it difficult to compare the performance of such methods across the literature. To bridge this gap, we introduce SocNavBench, a simulation framework for evaluating social navigation algorithms. SocNavBench comprises a simulator with photo-realistic capabilities and curated social navigation scenarios grounded in real-world pedestrian data. We also provide an implementation of a suite of metrics to quantify the performance of navigation algorithms on these scenarios. Altogether, SocNavBench provides a test framework for evaluating disparate social navigation methods in a consistent and interpretable manner. To illustrate its use, we demonstrate testing three existing social navigation methods and a baseline method on SocNavBench, showing how the suite of metrics helps infer their performance trade-offs. Our code is open-source, allowing the addition of new scenarios and metrics by the community to help evolve SocNavBench to reflect advancements in our understanding of social navigation.
SketchParse : Towards Rich Descriptions for Poorly Drawn Sketches using Multi-Task Hierarchical Deep Networks
Sep 05, 2017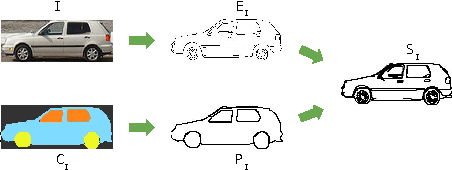

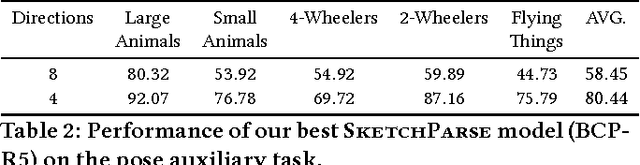

The ability to semantically interpret hand-drawn line sketches, although very challenging, can pave way for novel applications in multimedia. We propose SketchParse, the first deep-network architecture for fully automatic parsing of freehand object sketches. SketchParse is configured as a two-level fully convolutional network. The first level contains shared layers common to all object categories. The second level contains a number of expert sub-networks. Each expert specializes in parsing sketches from object categories which contain structurally similar parts. Effectively, the two-level configuration enables our architecture to scale up efficiently as additional categories are added. We introduce a router layer which (i) relays sketch features from shared layers to the correct expert (ii) eliminates the need to manually specify object category during inference. To bypass laborious part-level annotation, we sketchify photos from semantic object-part image datasets and use them for training. Our architecture also incorporates object pose prediction as a novel auxiliary task which boosts overall performance while providing supplementary information regarding the sketch. We demonstrate SketchParse's abilities (i) on two challenging large-scale sketch datasets (ii) in parsing unseen, semantically related object categories (iii) in improving fine-grained sketch-based image retrieval. As a novel application, we also outline how SketchParse's output can be used to generate caption-style descriptions for hand-drawn sketches.