 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Drivers' Risk Perception via Attention to Improve Driving Assistance
Sep 07, 2024Advanced Driver Assistance Systems (ADAS) alert drivers during safety-critical scenarios but often provide superfluous alerts due to a lack of consideration for drivers' knowledge or scene awareness. Modeling these aspects together in a data-driven way is challenging due to the scarcity of critical scenario data with in-cabin driver state and world state recorded together. We explore the benefits of driver modeling in the context of Forward Collision Warning (FCW) systems. Working with real-world video dataset of on-road FCW deployments, we collect observers' subjective validity rating of the deployed alerts. We also annotate participants' gaze-to-objects and extract 3D trajectories of the ego vehicle and other vehicles semi-automatically. We generate a risk estimate of the scene and the drivers' perception in a two step process: First, we model the movement of vehicles in a given scenario as a joint trajectory forecasting problem. Then, we reason about the drivers' risk perception of the scene by counterfactually modifying the input to the forecasting model to represent the drivers' actual observations of vehicles in the scene. The difference in these behaviours gives us an estimate of driver behaviour that accounts for their actual (inattentive) observations and their downstream effect on overall scene risk. We compare both a learned scene representation as well as a more traditional ``worse-case'' deceleration model to achieve the future trajectory forecast. Our experiments show that using this risk formulation to generate FCW alerts may lead to improved false positive rate of FCWs and improved FCW timing.
Specification-Guided Data Aggregation for Semantically Aware Imitation Learning
Mar 29, 2023



Advancements in simulation and formal methods-guided environment sampling have enabled the rigorous evaluation of machine learning models in a number of safety-critical scenarios, such as autonomous driving. Application of these environment sampling techniques towards improving the learned models themselves has yet to be fully exploited. In this work, we introduce a novel method for improving imitation-learned models in a semantically aware fashion by leveraging specification-guided sampling techniques as a means of aggregating expert data in new environments. Specifically, we create a set of formal specifications as a means of partitioning the space of possible environments into semantically similar regions, and identify elements of this partition where our learned imitation behaves most differently from the expert. We then aggregate expert data on environments in these identified regions, leading to more accurate imitation of the expert's behavior semantics. We instantiate our approach in a series of experiments in the CARLA driving simulator, and demonstrate that our approach leads to models that are more accurate than those learned with other environment sampling methods.
The Way to my Heart is through Contrastive Learning: Remote Photoplethysmography from Unlabelled Video
Nov 18, 2021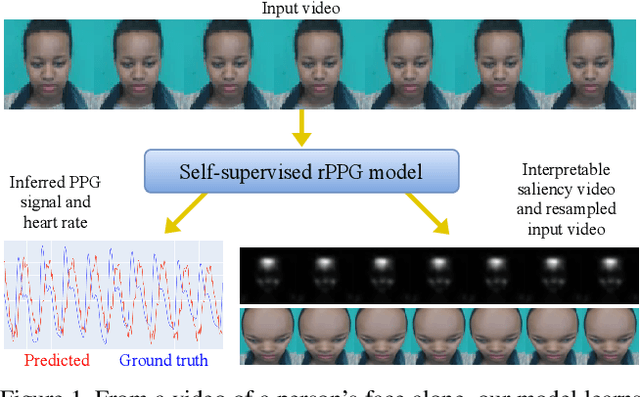

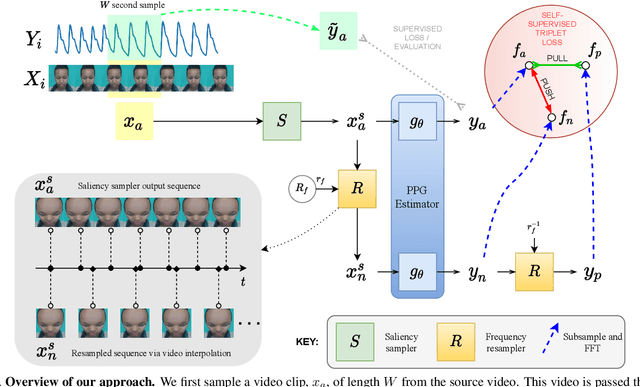
The ability to reliably estimate physiological signals from video is a powerful tool in low-cost, pre-clinical health monitoring. In this work we propose a new approach to remote photoplethysmography (rPPG) - the measurement of blood volume changes from observations of a person's face or skin. Similar to current state-of-the-art methods for rPPG, we apply neural networks to learn deep representations with invariance to nuisance image variation. In contrast to such methods, we employ a fully self-supervised training approach, which has no reliance on expensive ground truth physiological training data. Our proposed method uses contrastive learning with a weak prior over the frequency and temporal smoothness of the target signal of interest. We evaluate our approach on four rPPG datasets, showing that comparable or better results can be achieved compared to recent supervised deep learning methods but without using any annotation. In addition, we incorporate a learned saliency resampling module into both our unsupervised approach and supervised baseline. We show that by allowing the model to learn where to sample the input image, we can reduce the need for hand-engineered features while providing some interpretability into the model's behavior and possible failure modes. We release code for our complete training and evaluation pipeline to encourage reproducible progress in this exciting new direction.
* Code available at https://github.com/ToyotaResearchInstitute/RemotePPG
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
Aug 26, 2021
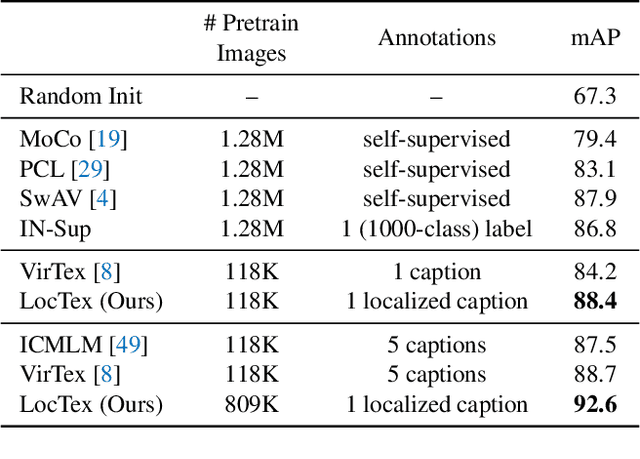
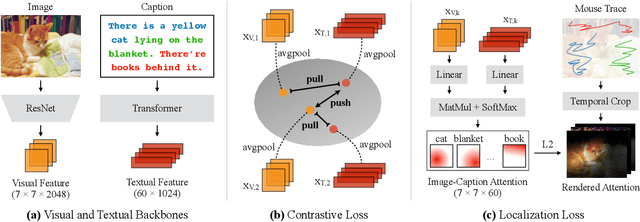
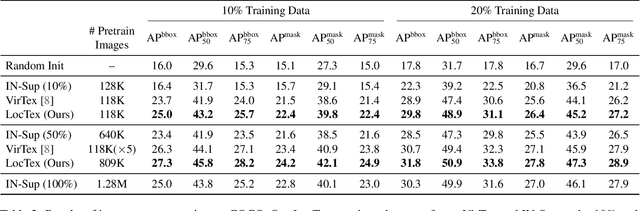
Computer vision tasks such as object detection and semantic/instance segmentation rely on the painstaking annotation of large training datasets. In this paper, we propose LocTex that takes advantage of the low-cost localized textual annotations (i.e., captions and synchronized mouse-over gestures) to reduce the annotation effort. We introduce a contrastive pre-training framework between images and captions and propose to supervise the cross-modal attention map with rendered mouse traces to provide coarse localization signals. Our learned visual features capture rich semantics (from free-form captions) and accurate localization (from mouse traces), which are very effective when transferred to various downstream vision tasks. Compared with ImageNet supervised pre-training, LocTex can reduce the size of the pre-training dataset by 10x or the target dataset by 2x while achieving comparable or even improved performance on COCO instance segmentation. When provided with the same amount of annotations, LocTex achieves around 4% higher accuracy than the previous state-of-the-art "vision+language" pre-training approach on the task of PASCAL VOC image classification.
When to Intervene: Detecting Abnormal Mood using Everyday Smartphone Conversations
Oct 03, 2019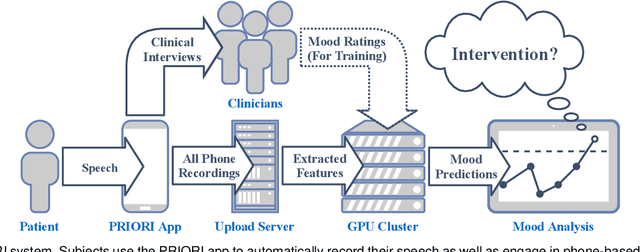
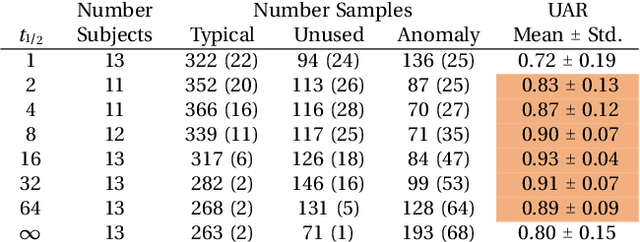
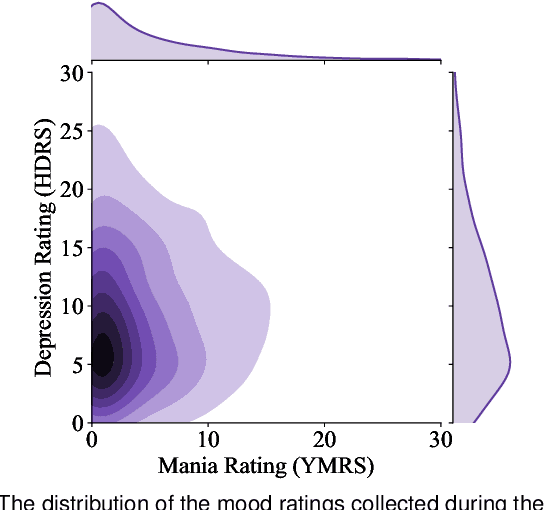

Bipolar disorder (BPD) is a chronic mental illness characterized by extreme mood and energy changes from mania to depression. These changes drive behaviors that often lead to devastating personal or social consequences. BPD is managed clinically with regular interactions with care providers, who assess mood, energy levels, and the form and content of speech. Recent work has proposed smartphones for monitoring mood using speech. However, these works do not predict when to intervene. Predicting when to intervene is challenging because there is not a single measure that is relevant for every person: different individuals may have different levels of symptom severity considered typical. Additionally, this typical mood, or baseline, may change over time, making a single symptom threshold insufficient. This work presents an innovative approach that expands clinical mood monitoring to predict when interventions are necessary using an anomaly detection framework, which we call Temporal Normalization. We first validate the model using a dataset annotated for clinical interventions and then incorporate this method in a deep learning framework to predict mood anomalies from natural, unstructured, telephone speech data. The combination of these approaches provides a framework to enable real-world speech-focused mood monitoring.
Barking up the Right Tree: Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization
Mar 28, 2019
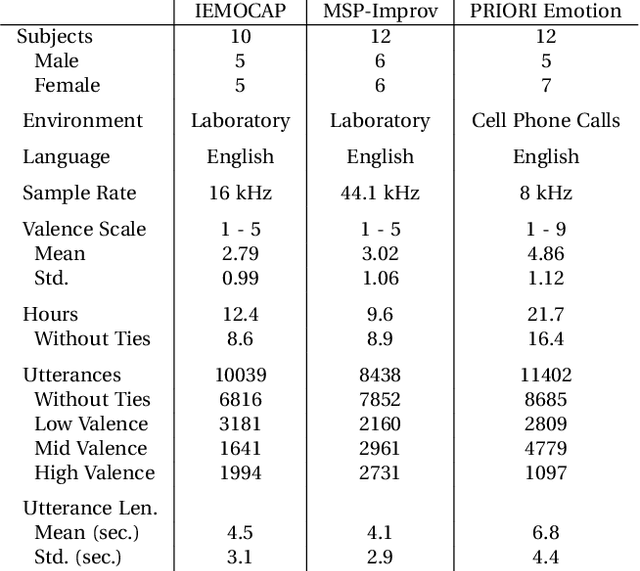
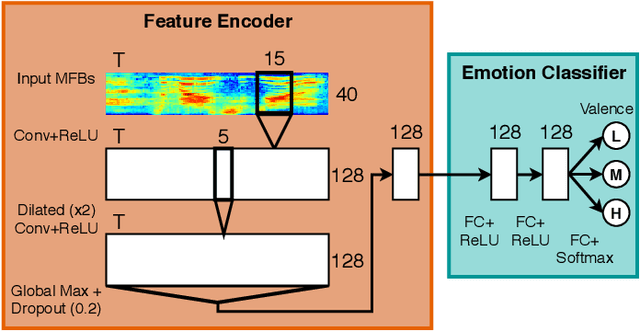
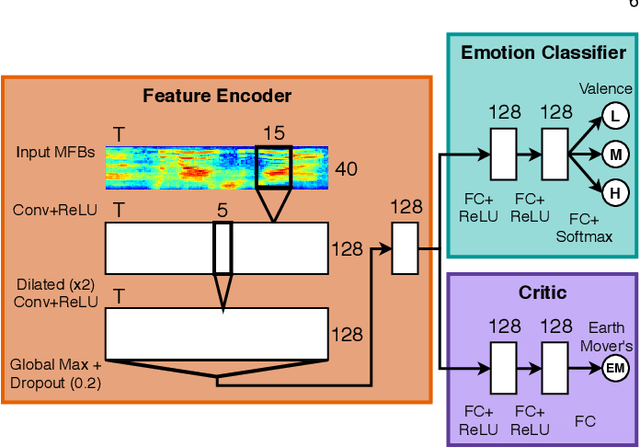
Automatic speech emotion recognition provides computers with critical context to enable user understanding. While methods trained and tested within the same dataset have been shown successful, they often fail when applied to unseen datasets. To address this, recent work has focused on adversarial methods to find more generalized representations of emotional speech. However, many of these methods have issues converging, and only involve datasets collected in laboratory conditions. In this paper, we introduce Adversarial Discriminative Domain Generalization (ADDoG), which follows an easier to train "meet in the middle" approach. The model iteratively moves representations learned for each dataset closer to one another, improving cross-dataset generalization. We also introduce Multiclass ADDoG, or MADDoG, which is able to extend the proposed method to more than two datasets, simultaneously. Our results show consistent convergence for the introduced methods, with significantly improved results when not using labels from the target dataset. We also show how, in most cases, ADDoG and MADDoG can be used to improve upon baseline state-of-the-art methods when target dataset labels are added and in-the-wild data are considered. Even though our experiments focus on cross-corpus speech emotion, these methods could be used to remove unwanted factors of variation in other settings.
Progressive Neural Networks for Transfer Learning in Emotion Recognition
Jun 10, 2017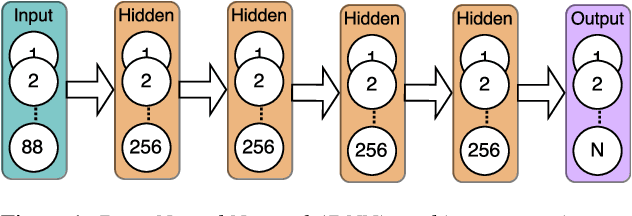

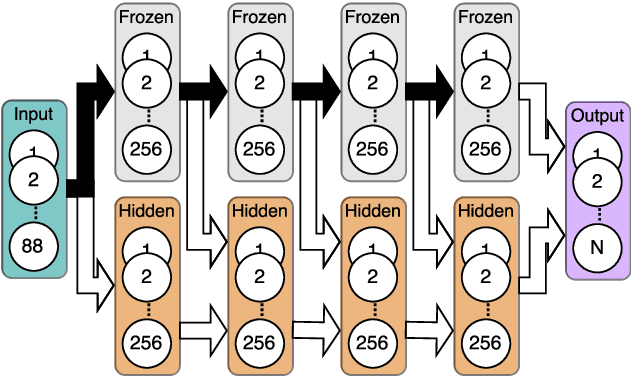
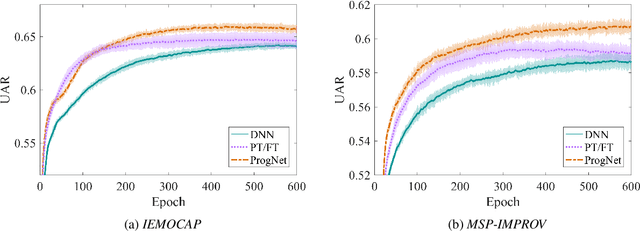
Many paralinguistic tasks are closely related and thus representations learned in one domain can be leveraged for another. In this paper, we investigate how knowledge can be transferred between three paralinguistic tasks: speaker, emotion, and gender recognition. Further, we extend this problem to cross-dataset tasks, asking how knowledge captured in one emotion dataset can be transferred to another. We focus on progressive neural networks and compare these networks to the conventional deep learning method of pre-training and fine-tuning. Progressive neural networks provide a way to transfer knowledge and avoid the forgetting effect present when pre-training neural networks on different tasks. Our experiments demonstrate that: (1) emotion recognition can benefit from using representations originally learned for different paralinguistic tasks and (2) transfer learning can effectively leverage additional datasets to improve the performance of emotion recognition systems.