 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Correct Automata Embeddings for Optimal Automata-Conditioned Reinforcement Learning
Mar 06, 2025Automata-conditioned reinforcement learning (RL) has given promising results for learning multi-task policies capable of performing temporally extended objectives given at runtime, done by pretraining and freezing automata embeddings prior to training the downstream policy. However, no theoretical guarantees were given. This work provides a theoretical framework for the automata-conditioned RL problem and shows that it is probably approximately correct learnable. We then present a technique for learning provably correct automata embeddings, guaranteeing optimal multi-task policy learning. Our experimental evaluation confirms these theoretical results.
Compositional Automata Embeddings for Goal-Conditioned Reinforcement Learning
Oct 31, 2024
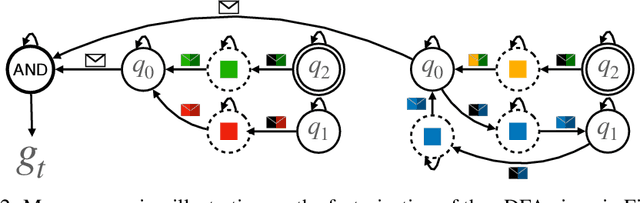
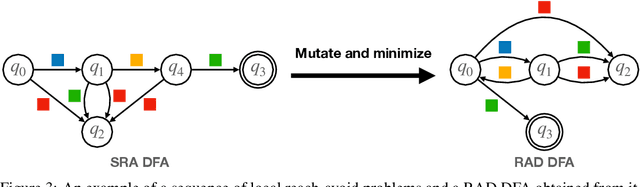
Goal-conditioned reinforcement learning is a powerful way to control an AI agent's behavior at runtime. That said, popular goal representations, e.g., target states or natural language, are either limited to Markovian tasks or rely on ambiguous task semantics. We propose representing temporal goals using compositions of deterministic finite automata (cDFAs) and use cDFAs to guide RL agents. cDFAs balance the need for formal temporal semantics with ease of interpretation: if one can understand a flow chart, one can understand a cDFA. On the other hand, cDFAs form a countably infinite concept class with Boolean semantics, and subtle changes to the automaton can result in very different tasks, making them difficult to condition agent behavior on. To address this, we observe that all paths through a DFA correspond to a series of reach-avoid tasks and propose pre-training graph neural network embeddings on "reach-avoid derived" DFAs. Through empirical evaluation, we demonstrate that the proposed pre-training method enables zero-shot generalization to various cDFA task classes and accelerated policy specialization without the myopic suboptimality of hierarchical methods.
Specification-Guided Data Aggregation for Semantically Aware Imitation Learning
Mar 29, 2023



Advancements in simulation and formal methods-guided environment sampling have enabled the rigorous evaluation of machine learning models in a number of safety-critical scenarios, such as autonomous driving. Application of these environment sampling techniques towards improving the learned models themselves has yet to be fully exploited. In this work, we introduce a novel method for improving imitation-learned models in a semantically aware fashion by leveraging specification-guided sampling techniques as a means of aggregating expert data in new environments. Specifically, we create a set of formal specifications as a means of partitioning the space of possible environments into semantically similar regions, and identify elements of this partition where our learned imitation behaves most differently from the expert. We then aggregate expert data on environments in these identified regions, leading to more accurate imitation of the expert's behavior semantics. We instantiate our approach in a series of experiments in the CARLA driving simulator, and demonstrate that our approach leads to models that are more accurate than those learned with other environment sampling methods.