 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Language and Road Manuals to Inform Map Reconstruction for Autonomous Driving
Jun 12, 2025Lane-topology prediction is a critical component of safe and reliable autonomous navigation. An accurate understanding of the road environment aids this task. We observe that this information often follows conventions encoded in natural language, through design codes that reflect the road structure and road names that capture the road functionality. We augment this information in a lightweight manner to SMERF, a map-prior-based online lane-topology prediction model, by combining structured road metadata from OSM maps and lane-width priors from Road design manuals with the road centerline encodings. We evaluate our method on two geo-diverse complex intersection scenarios. Our method shows improvement in both lane and traffic element detection and their association. We report results using four topology-aware metrics to comprehensively assess the model performance. These results demonstrate the ability of our approach to generalize and scale to diverse topologies and conditions.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
May 10, 2025Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
Provably Correct Automata Embeddings for Optimal Automata-Conditioned Reinforcement Learning
Mar 06, 2025Automata-conditioned reinforcement learning (RL) has given promising results for learning multi-task policies capable of performing temporally extended objectives given at runtime, done by pretraining and freezing automata embeddings prior to training the downstream policy. However, no theoretical guarantees were given. This work provides a theoretical framework for the automata-conditioned RL problem and shows that it is probably approximately correct learnable. We then present a technique for learning provably correct automata embeddings, guaranteeing optimal multi-task policy learning. Our experimental evaluation confirms these theoretical results.
SD++: Enhancing Standard Definition Maps by Incorporating Road Knowledge using LLMs
Feb 04, 2025



High-definition maps (HD maps) are detailed and informative maps capturing lane centerlines and road elements. Although very useful for autonomous driving, HD maps are costly to build and maintain. Furthermore, access to these high-quality maps is usually limited to the firms that build them. On the other hand, standard definition (SD) maps provide road centerlines with an accuracy of a few meters. In this paper, we explore the possibility of enhancing SD maps by incorporating information from road manuals using LLMs. We develop SD++, an end-to-end pipeline to enhance SD maps with location-dependent road information obtained from a road manual. We suggest and compare several ways of using LLMs for such a task. Furthermore, we show the generalization ability of SD++ by showing results from both California and Japan.
Compositional Automata Embeddings for Goal-Conditioned Reinforcement Learning
Oct 31, 2024
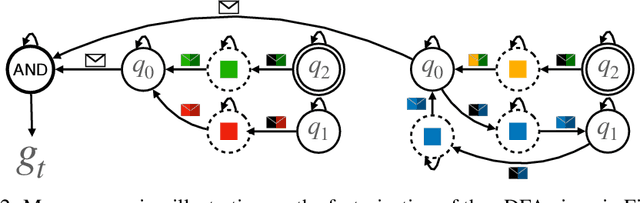
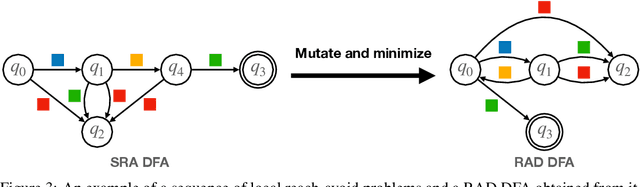
Goal-conditioned reinforcement learning is a powerful way to control an AI agent's behavior at runtime. That said, popular goal representations, e.g., target states or natural language, are either limited to Markovian tasks or rely on ambiguous task semantics. We propose representing temporal goals using compositions of deterministic finite automata (cDFAs) and use cDFAs to guide RL agents. cDFAs balance the need for formal temporal semantics with ease of interpretation: if one can understand a flow chart, one can understand a cDFA. On the other hand, cDFAs form a countably infinite concept class with Boolean semantics, and subtle changes to the automaton can result in very different tasks, making them difficult to condition agent behavior on. To address this, we observe that all paths through a DFA correspond to a series of reach-avoid tasks and propose pre-training graph neural network embeddings on "reach-avoid derived" DFAs. Through empirical evaluation, we demonstrate that the proposed pre-training method enables zero-shot generalization to various cDFA task classes and accelerated policy specialization without the myopic suboptimality of hierarchical methods.
Diffusion-Based Failure Sampling for Cyber-Physical Systems
Jun 20, 2024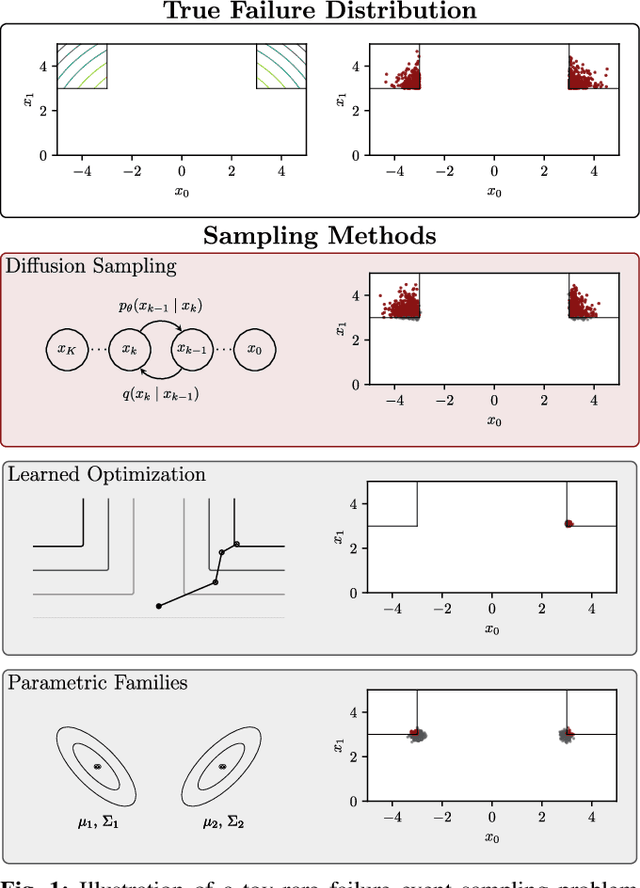
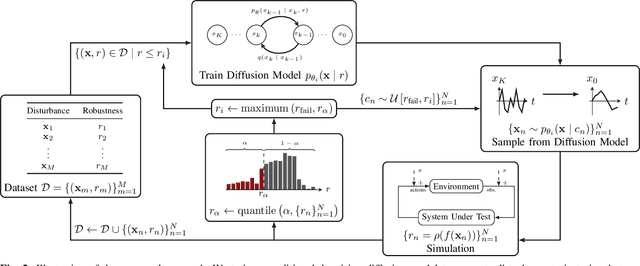
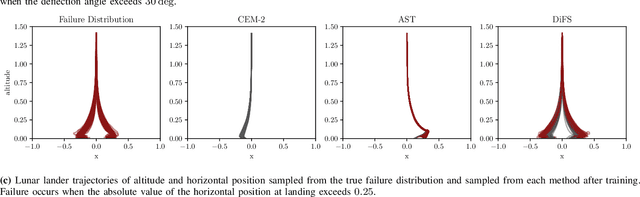
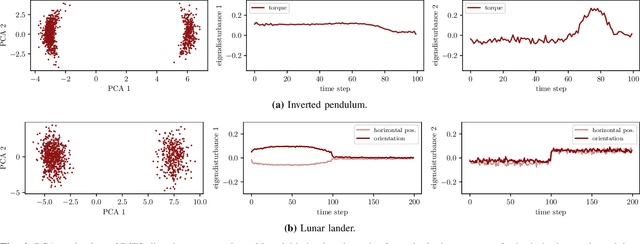
Validating safety-critical autonomous systems in high-dimensional domains such as robotics presents a significant challenge. Existing black-box approaches based on Markov chain Monte Carlo may require an enormous number of samples, while methods based on importance sampling often rely on simple parametric families that may struggle to represent the distribution over failures. We propose to sample the distribution over failures using a conditional denoising diffusion model, which has shown success in complex high-dimensional problems such as robotic task planning. We iteratively train a diffusion model to produce state trajectories closer to failure. We demonstrate the effectiveness of our approach on high-dimensional robotic validation tasks, improving sample efficiency and mode coverage compared to existing black-box techniques.
Generating Probabilistic Scenario Programs from Natural Language
May 03, 2024
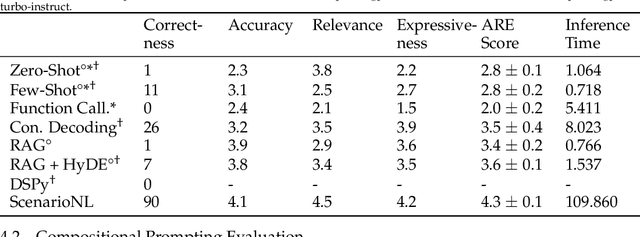

For cyber-physical systems (CPS), including robotics and autonomous vehicles, mass deployment has been hindered by fatal errors that occur when operating in rare events. To replicate rare events such as vehicle crashes, many companies have created logging systems and employed crash reconstruction experts to meticulously recreate these valuable events in simulation. However, in these methods, "what if" questions are not easily formulated and answered. We present ScenarioNL, an AI System for creating scenario programs from natural language. Specifically, we generate these programs from police crash reports. Reports normally contain uncertainty about the exact details of the incidents which we represent through a Probabilistic Programming Language (PPL), Scenic. By using Scenic, we can clearly and concisely represent uncertainty and variation over CPS behaviors, properties, and interactions. We demonstrate how commonplace prompting techniques with the best Large Language Models (LLM) are incapable of reasoning about probabilistic scenario programs and generating code for low-resource languages such as Scenic. Our system is comprised of several LLMs chained together with several kinds of prompting strategies, a compiler, and a simulator. We evaluate our system on publicly available autonomous vehicle crash reports in California from the last five years and share insights into how we generate code that is both semantically meaningful and syntactically correct.
Entropy-regularized Point-based Value Iteration
Feb 14, 2024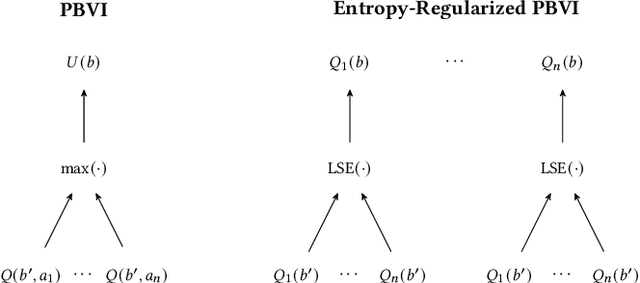



Model-based planners for partially observable problems must accommodate both model uncertainty during planning and goal uncertainty during objective inference. However, model-based planners may be brittle under these types of uncertainty because they rely on an exact model and tend to commit to a single optimal behavior. Inspired by results in the model-free setting, we propose an entropy-regularized model-based planner for partially observable problems. Entropy regularization promotes policy robustness for planning and objective inference by encouraging policies to be no more committed to a single action than necessary. We evaluate the robustness and objective inference performance of entropy-regularized policies in three problem domains. Our results show that entropy-regularized policies outperform non-entropy-regularized baselines in terms of higher expected returns under modeling errors and higher accuracy during objective inference.
$L^*LM$: Learning Automata from Examples using Natural Language Oracles
Feb 10, 2024Expert demonstrations have proven an easy way to indirectly specify complex tasks. Recent algorithms even support extracting unambiguous formal specifications, e.g. deterministic finite automata (DFA), from demonstrations. Unfortunately, these techniques are generally not sample efficient. In this work, we introduce $L^*LM$, an algorithm for learning DFAs from both demonstrations and natural language. Due to the expressivity of natural language, we observe a significant improvement in the data efficiency of learning DFAs from expert demonstrations. Technically, $L^*LM$ leverages large language models to answer membership queries about the underlying task. This is then combined with recent techniques for transforming learning from demonstrations into a sequence of labeled example learning problems. In our experiments, we observe the two modalities complement each other, yielding a powerful few-shot learner.
Learning Formal Specifications from Membership and Preference Queries
Jul 19, 2023

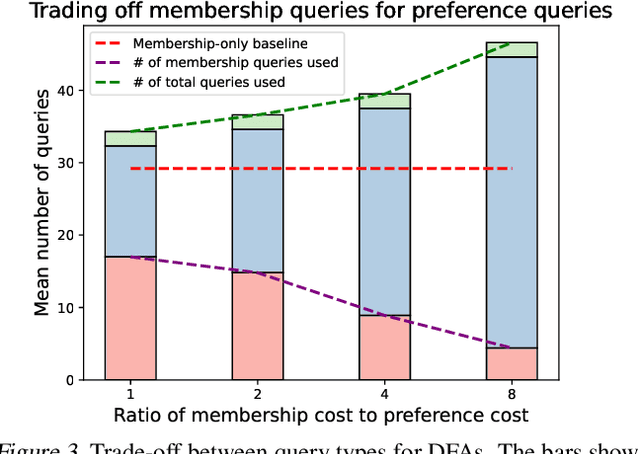

Active learning is a well-studied approach to learning formal specifications, such as automata. In this work, we extend active specification learning by proposing a novel framework that strategically requests a combination of membership labels and pair-wise preferences, a popular alternative to membership labels. The combination of pair-wise preferences and membership labels allows for a more flexible approach to active specification learning, which previously relied on membership labels only. We instantiate our framework in two different domains, demonstrating the generality of our approach. Our results suggest that learning from both modalities allows us to robustly and conveniently identify specifications via membership and preferences.