 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-regularized Point-based Value Iteration
Feb 14, 2024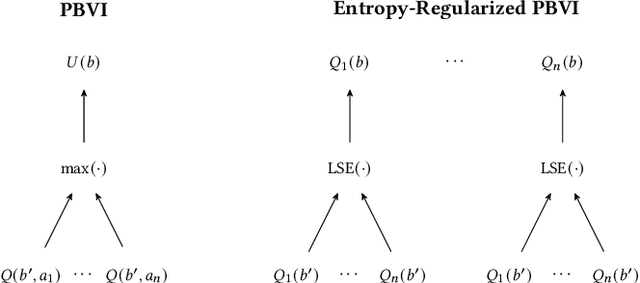



Model-based planners for partially observable problems must accommodate both model uncertainty during planning and goal uncertainty during objective inference. However, model-based planners may be brittle under these types of uncertainty because they rely on an exact model and tend to commit to a single optimal behavior. Inspired by results in the model-free setting, we propose an entropy-regularized model-based planner for partially observable problems. Entropy regularization promotes policy robustness for planning and objective inference by encouraging policies to be no more committed to a single action than necessary. We evaluate the robustness and objective inference performance of entropy-regularized policies in three problem domains. Our results show that entropy-regularized policies outperform non-entropy-regularized baselines in terms of higher expected returns under modeling errors and higher accuracy during objective inference.
Decision Making in Non-Stationary Environments with Policy-Augmented Search
Jan 06, 2024



Sequential decision-making under uncertainty is present in many important problems. Two popular approaches for tackling such problems are reinforcement learning and online search (e.g., Monte Carlo tree search). While the former learns a policy by interacting with the environment (typically done before execution), the latter uses a generative model of the environment to sample promising action trajectories at decision time. Decision-making is particularly challenging in non-stationary environments, where the environment in which an agent operates can change over time. Both approaches have shortcomings in such settings -- on the one hand, policies learned before execution become stale when the environment changes and relearning takes both time and computational effort. Online search, on the other hand, can return sub-optimal actions when there are limitations on allowed runtime. In this paper, we introduce \textit{Policy-Augmented Monte Carlo tree search} (PA-MCTS), which combines action-value estimates from an out-of-date policy with an online search using an up-to-date model of the environment. We prove theoretical results showing conditions under which PA-MCTS selects the one-step optimal action and also bound the error accrued while following PA-MCTS as a policy. We compare and contrast our approach with AlphaZero, another hybrid planning approach, and Deep Q Learning on several OpenAI Gym environments. Through extensive experiments, we show that under non-stationary settings with limited time constraints, PA-MCTS outperforms these baselines.
Active teacher selection for reinforcement learning from human feedback
Oct 23, 2023



Reinforcement learning from human feedback (RLHF) enables machine learning systems to learn objectives from human feedback. A core limitation of these systems is their assumption that all feedback comes from a single human teacher, despite querying a range of distinct teachers. We propose the Hidden Utility Bandit (HUB) framework to model differences in teacher rationality, expertise, and costliness, formalizing the problem of learning from multiple teachers. We develop a variety of solution algorithms and apply them to two real-world domains: paper recommendation systems and COVID-19 vaccine testing. We find that the Active Teacher Selection (ATS) algorithm outperforms baseline algorithms by actively selecting when and which teacher to query. The HUB framework and ATS algorithm demonstrate the importance of leveraging differences between teachers to learn accurate reward models, facilitating future research on active teacher selection for robust reward modeling.