 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Safety Validation of Autonomous Driving Systems
Jun 10, 2025Safety validation of autonomous driving systems is extremely challenging due to the high risks and costs of real-world testing as well as the rarity and diversity of potential failures. To address these challenges, we train a denoising diffusion model to generate potential failure cases of an autonomous vehicle given any initial traffic state. Experiments on a four-way intersection problem show that in a variety of scenarios, the diffusion model can generate realistic failure samples while capturing a wide variety of potential failures. Our model does not require any external training dataset, can perform training and inference with modest computing resources, and does not assume any prior knowledge of the system under test, with applicability to safety validation for traffic intersections.
An Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
Enhanced Importance Sampling through Latent Space Exploration in Normalizing Flows
Jan 06, 2025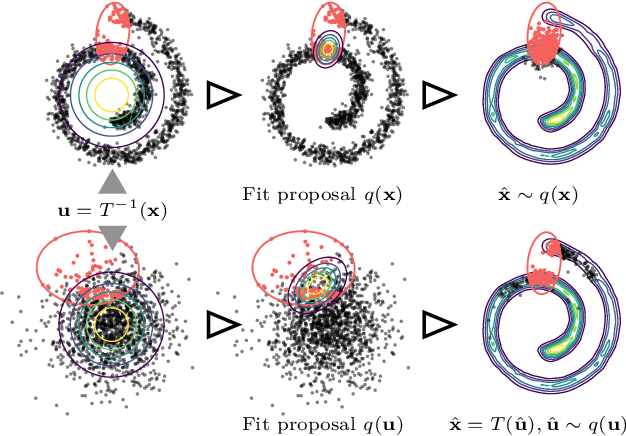
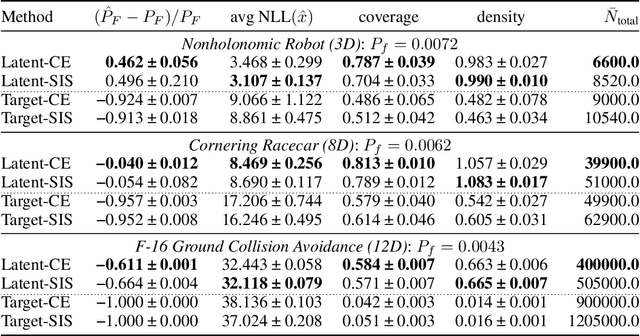
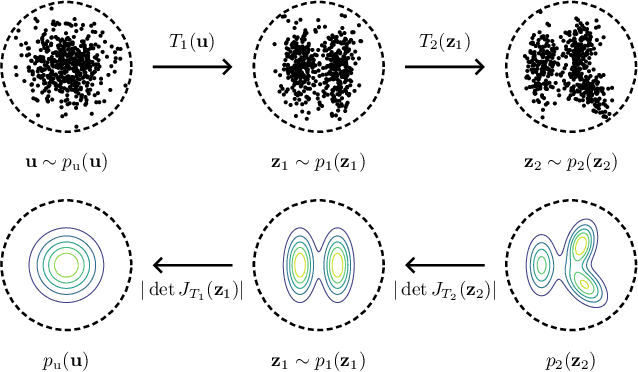
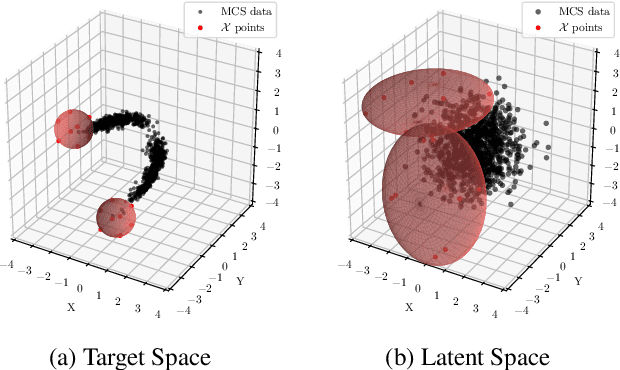
Importance sampling is a rare event simulation technique used in Monte Carlo simulations to bias the sampling distribution towards the rare event of interest. By assigning appropriate weights to sampled points, importance sampling allows for more efficient estimation of rare events or tails of distributions. However, importance sampling can fail when the proposal distribution does not effectively cover the target distribution. In this work, we propose a method for more efficient sampling by updating the proposal distribution in the latent space of a normalizing flow. Normalizing flows learn an invertible mapping from a target distribution to a simpler latent distribution. The latent space can be more easily explored during the search for a proposal distribution, and samples from the proposal distribution are recovered in the space of the target distribution via the invertible mapping. We empirically validate our methodology on simulated robotics applications such as autonomous racing and aircraft ground collision avoidance.
Failure Probability Estimation for Black-Box Autonomous Systems using State-Dependent Importance Sampling Proposals
Dec 03, 2024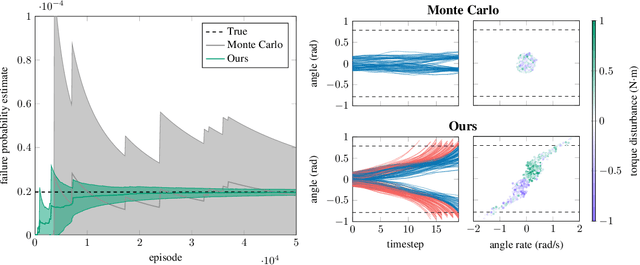

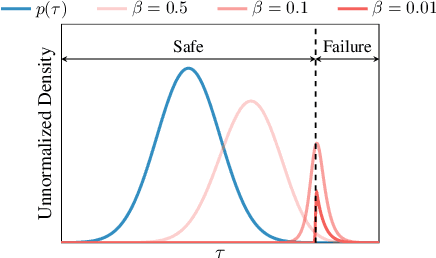
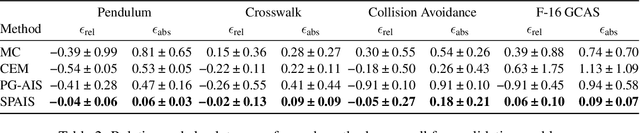
Estimating the probability of failure is a critical step in developing safety-critical autonomous systems. Direct estimation methods such as Monte Carlo sampling are often impractical due to the rarity of failures in these systems. Existing importance sampling approaches do not scale to sequential decision-making systems with large state spaces and long horizons. We propose an adaptive importance sampling algorithm to address these limitations. Our method minimizes the forward Kullback-Leibler divergence between a state-dependent proposal distribution and a relaxed form of the optimal importance sampling distribution. Our method uses Markov score ascent methods to estimate this objective. We evaluate our approach on four sequential systems and show that it provides more accurate failure probability estimates than baseline Monte Carlo and importance sampling techniques. This work is open sourced.
Diffusion-Based Failure Sampling for Cyber-Physical Systems
Jun 20, 2024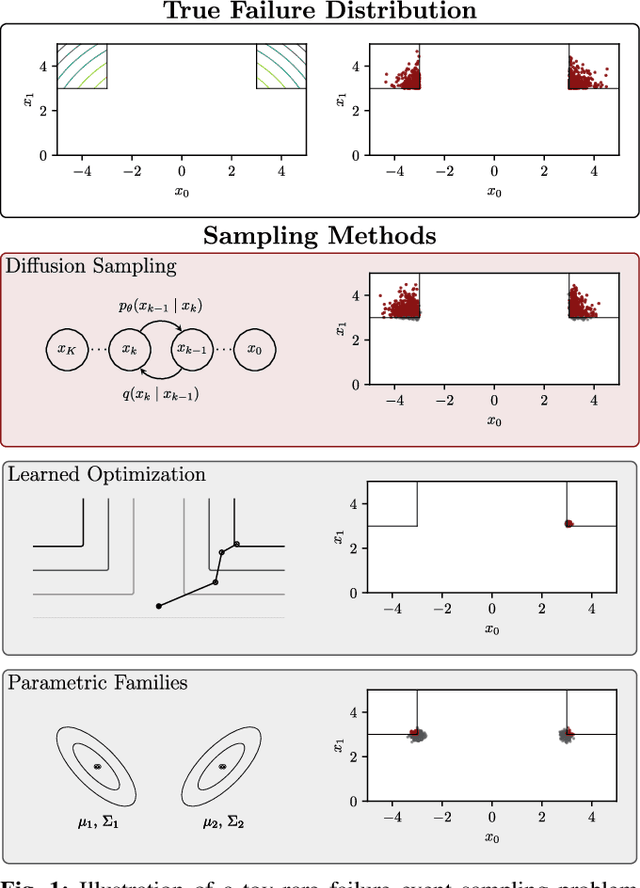
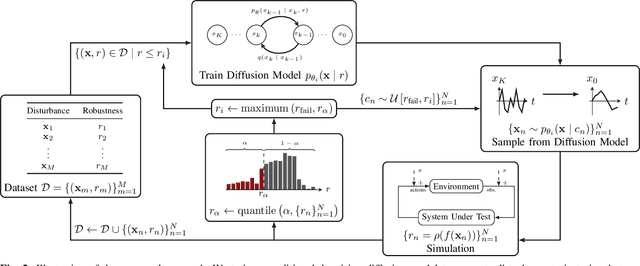
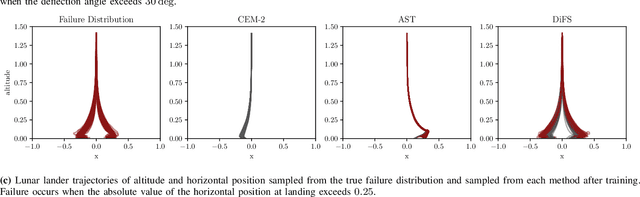
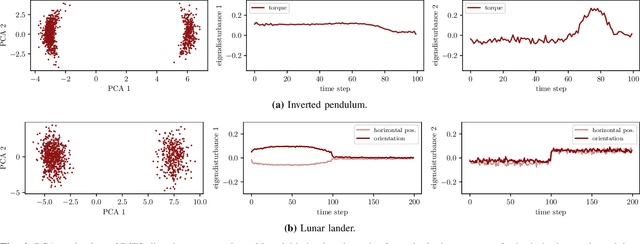
Validating safety-critical autonomous systems in high-dimensional domains such as robotics presents a significant challenge. Existing black-box approaches based on Markov chain Monte Carlo may require an enormous number of samples, while methods based on importance sampling often rely on simple parametric families that may struggle to represent the distribution over failures. We propose to sample the distribution over failures using a conditional denoising diffusion model, which has shown success in complex high-dimensional problems such as robotic task planning. We iteratively train a diffusion model to produce state trajectories closer to failure. We demonstrate the effectiveness of our approach on high-dimensional robotic validation tasks, improving sample efficiency and mode coverage compared to existing black-box techniques.
Entropy-regularized Point-based Value Iteration
Feb 14, 2024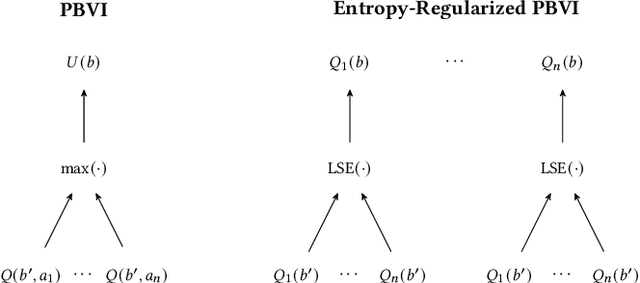



Model-based planners for partially observable problems must accommodate both model uncertainty during planning and goal uncertainty during objective inference. However, model-based planners may be brittle under these types of uncertainty because they rely on an exact model and tend to commit to a single optimal behavior. Inspired by results in the model-free setting, we propose an entropy-regularized model-based planner for partially observable problems. Entropy regularization promotes policy robustness for planning and objective inference by encouraging policies to be no more committed to a single action than necessary. We evaluate the robustness and objective inference performance of entropy-regularized policies in three problem domains. Our results show that entropy-regularized policies outperform non-entropy-regularized baselines in terms of higher expected returns under modeling errors and higher accuracy during objective inference.
Deep Normalizing Flows for State Estimation
Jun 27, 2023



Safe and reliable state estimation techniques are a critical component of next-generation robotic systems. Agents in such systems must be able to reason about the intentions and trajectories of other agents for safe and efficient motion planning. However, classical state estimation techniques such as Gaussian filters often lack the expressive power to represent complex underlying distributions, especially if the system dynamics are highly nonlinear or if the interaction outcomes are multi-modal. In this work, we use normalizing flows to learn an expressive representation of the belief over an agent's true state. Furthermore, we improve upon existing architectures for normalizing flows by using more expressive deep neural network architectures to parameterize the flow. We evaluate our method on two robotic state estimation tasks and show that our approach outperforms both classical and modern deep learning-based state estimation baselines.
Model-based Validation as Probabilistic Inference
May 17, 2023Estimating the distribution over failures is a key step in validating autonomous systems. Existing approaches focus on finding failures for a small range of initial conditions or make restrictive assumptions about the properties of the system under test. We frame estimating the distribution over failure trajectories for sequential systems as Bayesian inference. Our model-based approach represents the distribution over failure trajectories using rollouts of system dynamics and computes trajectory gradients using automatic differentiation. Our approach is demonstrated in an inverted pendulum control system, an autonomous vehicle driving scenario, and a partially observable lunar lander. Sampling is performed using an off-the-shelf implementation of Hamiltonian Monte Carlo with multiple chains to capture multimodality and gradient smoothing for safe trajectories. In all experiments, we observed improvements in sample efficiency and parameter space coverage compared to black-box baseline approaches. This work is open sourced.
Risk-aware Meta-level Decision Making for Exploration Under Uncertainty
Sep 12, 2022
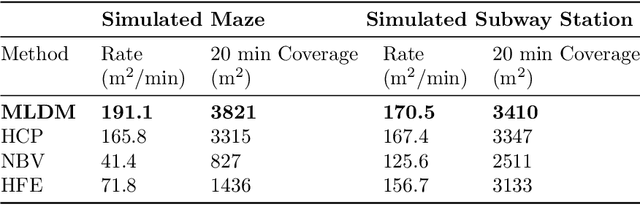
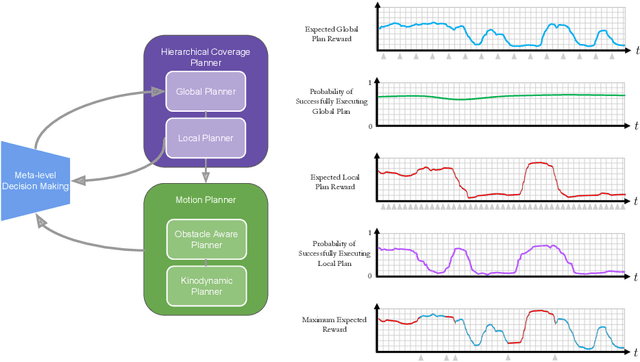
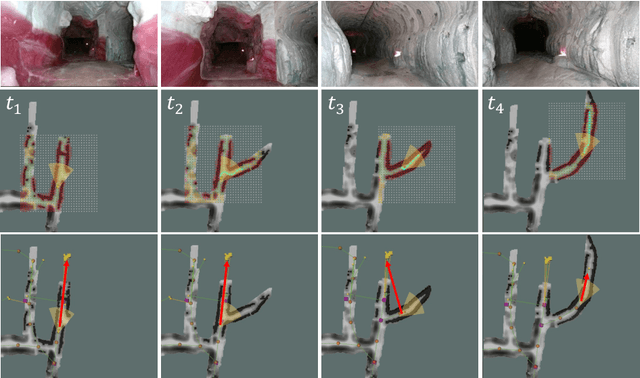
Robotic exploration of unknown environments is fundamentally a problem of decision making under uncertainty where the robot must account for uncertainty in sensor measurements, localization, action execution, as well as many other factors. For large-scale exploration applications, autonomous systems must overcome the challenges of sequentially deciding which areas of the environment are valuable to explore while safely evaluating the risks associated with obstacles and hazardous terrain. In this work, we propose a risk-aware meta-level decision making framework to balance the tradeoffs associated with local and global exploration. Meta-level decision making builds upon classical hierarchical coverage planners by switching between local and global policies with the overall objective of selecting the policy that is most likely to maximize reward in a stochastic environment. We use information about the environment history, traversability risk, and kinodynamic constraints to reason about the probability of successful policy execution to switch between local and global policies. We have validated our solution in both simulation and on a variety of large-scale real world hardware tests. Our results show that by balancing local and global exploration we are able to significantly explore large-scale environments more efficiently.
How Do We Fail? Stress Testing Perception in Autonomous Vehicles
Mar 26, 2022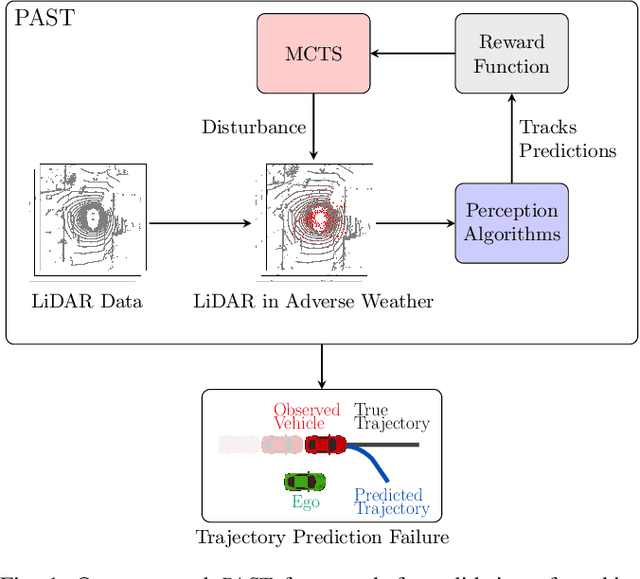
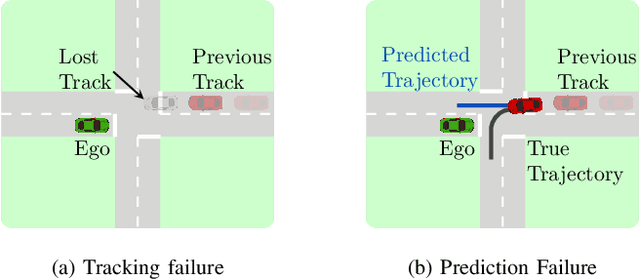
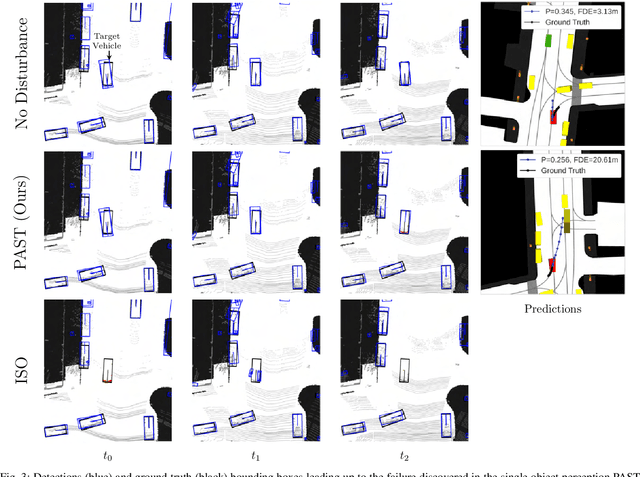
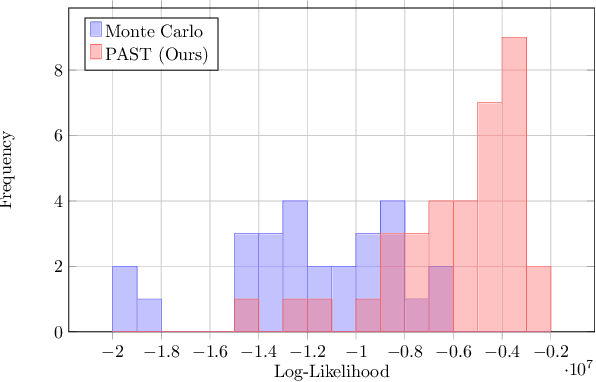
Autonomous vehicles (AVs) rely on environment perception and behavior prediction to reason about agents in their surroundings. These perception systems must be robust to adverse weather such as rain, fog, and snow. However, validation of these systems is challenging due to their complexity and dependence on observation histories. This paper presents a method for characterizing failures of LiDAR-based perception systems for AVs in adverse weather conditions. We develop a methodology based in reinforcement learning to find likely failures in object tracking and trajectory prediction due to sequences of disturbances. We apply disturbances using a physics-based data augmentation technique for simulating LiDAR point clouds in adverse weather conditions. Experiments performed across a wide range of driving scenarios from a real-world driving dataset show that our proposed approach finds high likelihood failures with smaller input disturbances compared to baselines while remaining computationally tractable. Identified failures can inform future development of robust perception systems for AVs.