 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FABRIC Strategy for Verifying Neural Feedback Systems
Mar 09, 2026Forward reachability analysis is a dominant approach for verifying reach-avoid specifications in neural feedback systems, i.e., dynamical systems controlled by neural networks, and a number of directions have been proposed and studied. In contrast, far less attention has been given to backward reachability analysis for these systems, in part because of the limited scalability of known techniques. In this work, we begin to address this gap by introducing new algorithms for computing both over- and underapproximations of backward reachable sets for nonlinear neural feedback systems. We also describe and implement an integration of these backward reachability techniques with existing ones for forward analysis. We call the resulting algorithm Forward and Backward Reachability Integration for Certification (FaBRIC). We evaluate our algorithms on a representative set of benchmarks and show that they significantly outperform the prior state of the art.
A New Strategy for Verifying Reach-Avoid Specifications in Neural Feedback Systems
Jan 12, 2026Forward reachability analysis is the predominant approach for verifying reach-avoid properties in neural feedback systems (dynamical systems controlled by neural networks). This dominance stems from the limited scalability of existing backward reachability methods. In this work, we introduce new algorithms that compute both over- and under-approximations of backward reachable sets for such systems. We further integrate these backward algorithms with established forward analysis techniques to yield a unified verification framework for neural feedback systems.
DB-KSVD: Scalable Alternating Optimization for Disentangling High-Dimensional Embedding Spaces
May 24, 2025Dictionary learning has recently emerged as a promising approach for mechanistic interpretability of large transformer models. Disentangling high-dimensional transformer embeddings, however, requires algorithms that scale to high-dimensional data with large sample sizes. Recent work has explored sparse autoencoders (SAEs) for this problem. However, SAEs use a simple linear encoder to solve the sparse encoding subproblem, which is known to be NP-hard. It is therefore interesting to understand whether this structure is sufficient to find good solutions to the dictionary learning problem or if a more sophisticated algorithm could find better solutions. In this work, we propose Double-Batch KSVD (DB-KSVD), a scalable dictionary learning algorithm that adapts the classic KSVD algorithm. DB-KSVD is informed by the rich theoretical foundations of KSVD but scales to datasets with millions of samples and thousands of dimensions. We demonstrate the efficacy of DB-KSVD by disentangling embeddings of the Gemma-2-2B model and evaluating on six metrics from the SAEBench benchmark, where we achieve competitive results when compared to established approaches based on SAEs. By matching SAE performance with an entirely different optimization approach, our results suggest that (i) SAEs do find strong solutions to the dictionary learning problem and (ii) that traditional optimization approaches can be scaled to the required problem sizes, offering a promising avenue for further research. We provide an implementation of DB-KSVD at https://github.com/RomeoV/KSVD.jl.
Failure Probability Estimation for Black-Box Autonomous Systems using State-Dependent Importance Sampling Proposals
Dec 03, 2024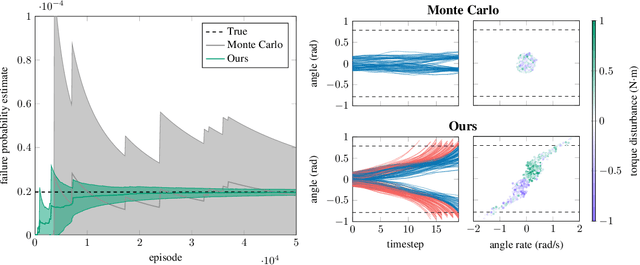

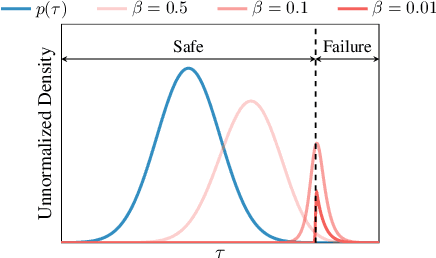
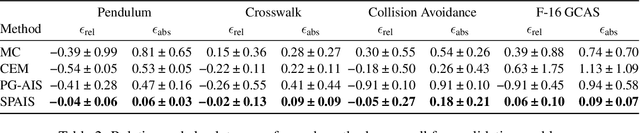
Estimating the probability of failure is a critical step in developing safety-critical autonomous systems. Direct estimation methods such as Monte Carlo sampling are often impractical due to the rarity of failures in these systems. Existing importance sampling approaches do not scale to sequential decision-making systems with large state spaces and long horizons. We propose an adaptive importance sampling algorithm to address these limitations. Our method minimizes the forward Kullback-Leibler divergence between a state-dependent proposal distribution and a relaxed form of the optimal importance sampling distribution. Our method uses Markov score ascent methods to estimate this objective. We evaluate our approach on four sequential systems and show that it provides more accurate failure probability estimates than baseline Monte Carlo and importance sampling techniques. This work is open sourced.
Probabilistic Parameter Estimators and Calibration Metrics for Pose Estimation from Image Features
Jul 23, 2024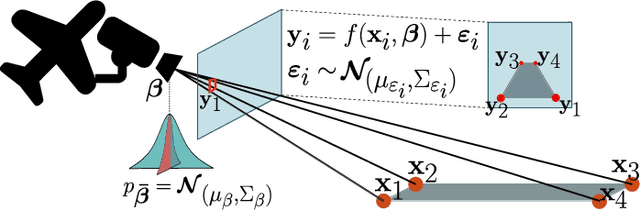
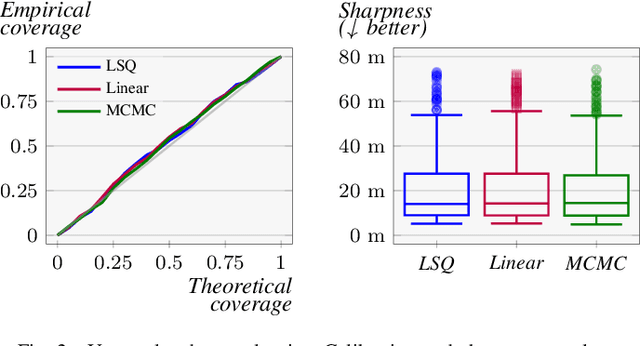
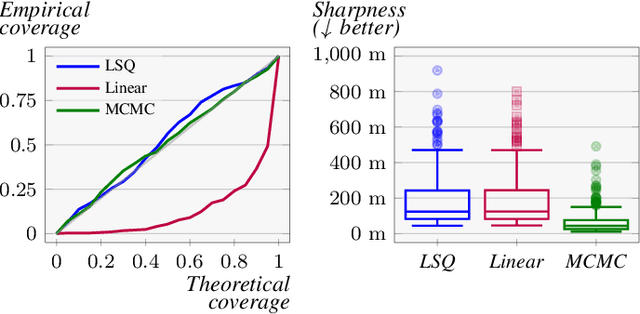
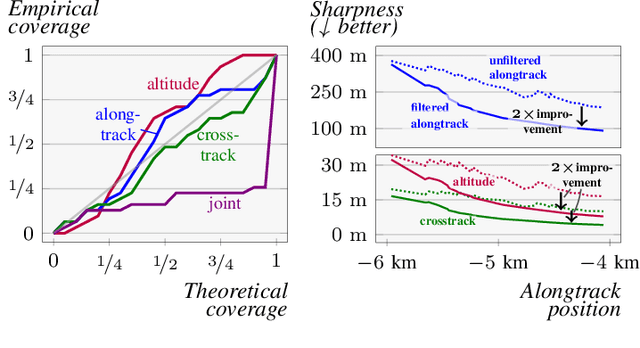
This paper addresses the challenge of probabilistic parameter estimation given measurement uncertainty in real-time. We provide a general formulation and apply this to pose estimation for an autonomous visual landing system. We present three probabilistic parameter estimators: a least-squares sampling approach, a linear approximation method, and a probabilistic programming estimator. To evaluate these estimators, we introduce novel closed-form expressions for measuring calibration and sharpness specifically for multivariate normal distributions. Our experimental study compares the three estimators under various noise conditions. We demonstrate that the linear approximation estimator can produce sharp and well-calibrated pose predictions significantly faster than the other methods but may yield overconfident predictions in certain scenarios. Additionally, we demonstrate that these estimators can be integrated with a Kalman filter for continuous pose estimation during a runway approach where we observe a 50\% improvement in sharpness while maintaining marginal calibration. This work contributes to the integration of data-driven computer vision models into complex safety-critical aircraft systems and provides a foundation for developing rigorous certification guidelines for such systems.
Efficient Determination of Safety Requirements for Perception Systems
Jul 03, 2023

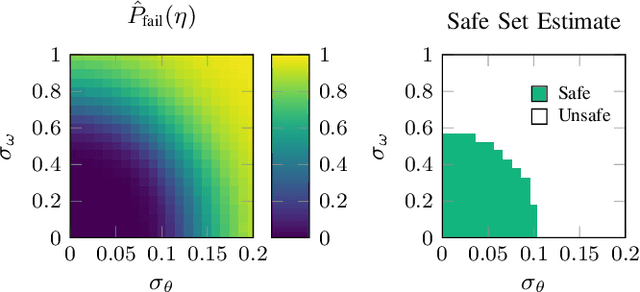

Perception systems operate as a subcomponent of the general autonomy stack, and perception system designers often need to optimize performance characteristics while maintaining safety with respect to the overall closed-loop system. For this reason, it is useful to distill high-level safety requirements into component-level requirements on the perception system. In this work, we focus on efficiently determining sets of safe perception system performance characteristics given a black-box simulator of the fully-integrated, closed-loop system. We combine the advantages of common black-box estimation techniques such as Gaussian processes and threshold bandits to develop a new estimation method, which we call smoothing bandits. We demonstrate our method on a vision-based aircraft collision avoidance problem and show improvements in terms of both accuracy and efficiency over the Gaussian process and threshold bandit baselines.
AVOIDDS: Aircraft Vision-based Intruder Detection Dataset and Simulator
Jun 19, 2023Designing robust machine learning systems remains an open problem, and there is a need for benchmark problems that cover both environmental changes and evaluation on a downstream task. In this work, we introduce AVOIDDS, a realistic object detection benchmark for the vision-based aircraft detect-and-avoid problem. We provide a labeled dataset consisting of 72,000 photorealistic images of intruder aircraft with various lighting conditions, weather conditions, relative geometries, and geographic locations. We also provide an interface that evaluates trained models on slices of this dataset to identify changes in performance with respect to changing environmental conditions. Finally, we implement a fully-integrated, closed-loop simulator of the vision-based detect-and-avoid problem to evaluate trained models with respect to the downstream collision avoidance task. This benchmark will enable further research in the design of robust machine learning systems for use in safety-critical applications. The AVOIDDS dataset and code are publicly available at $\href{https://purl.stanford.edu/hj293cv5980}{purl.stanford.edu/hj293cv5980}$ and $\href{https://github.com/sisl/VisionBasedAircraftDAA}{github.com/sisl/VisionBasedAircraftDAA}$, respectively.
Backward Reachability Analysis of Neural Feedback Loops: Techniques for Linear and Nonlinear Systems
Sep 28, 2022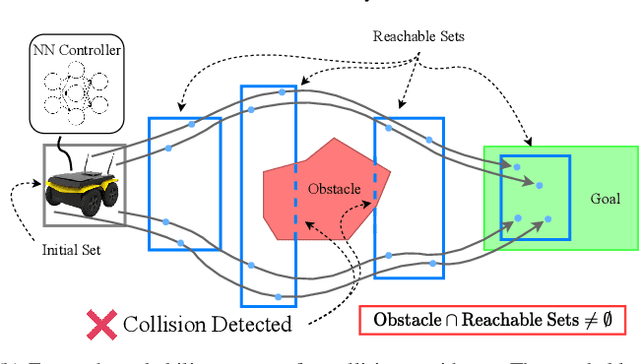

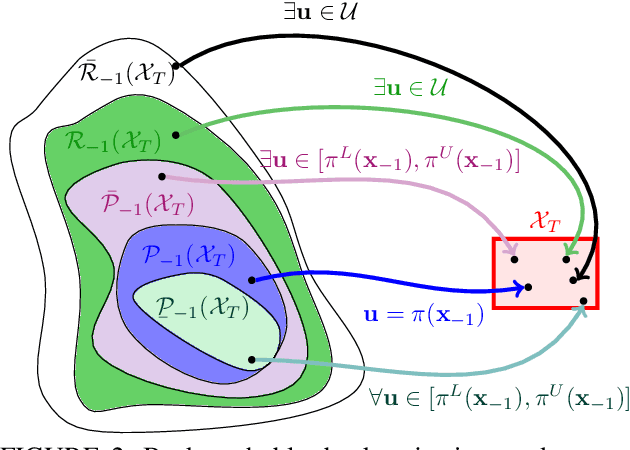

The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify safe behavior. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to efficiently find an over-approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present frameworks for calculating BP over-approximations for both linear and nonlinear systems with control policies represented by feedforward NNs and propose computationally efficient strategies. We use numerical results from a variety of models to showcase the proposed algorithms, including a demonstration of safety certification for a 6D system.
Risk-Driven Design of Perception Systems
May 21, 2022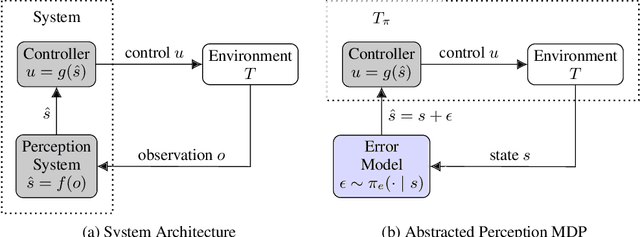

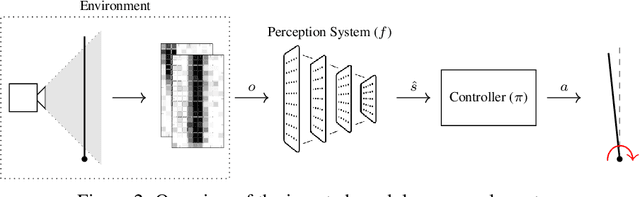

Modern autonomous systems rely on perception modules to process complex sensor measurements into state estimates. These estimates are then passed to a controller, which uses them to make safety-critical decisions. It is therefore important that we design perception systems to minimize errors that reduce the overall safety of the system. We develop a risk-driven approach to designing perception systems that accounts for the effect of perceptual errors on the performance of the fully-integrated, closed-loop system. We formulate a risk function to quantify the effect of a given perceptual error on overall safety, and show how we can use it to design safer perception systems by including a risk-dependent term in the loss function and generating training data in risk-sensitive regions. We evaluate our techniques on a realistic vision-based aircraft detect and avoid application and show that risk-driven design reduces collision risk by 37% over a baseline system.
Collision Risk and Operational Impact of Speed Change Advisories as Aircraft Collision Avoidance Maneuvers
Apr 29, 2022
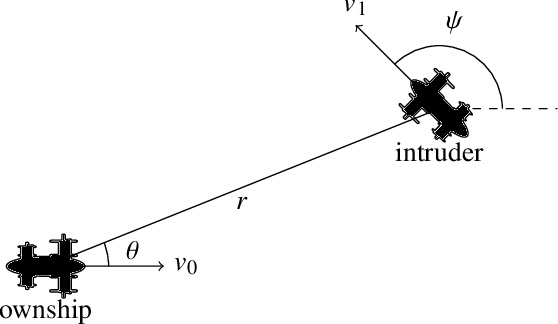

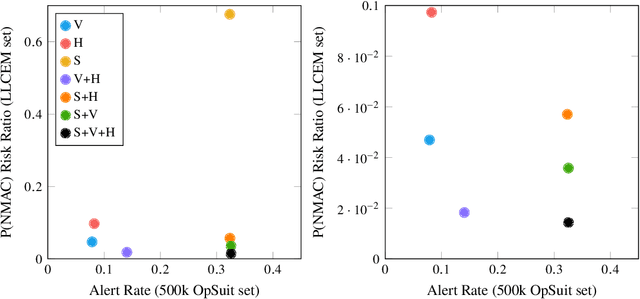
Aircraft collision avoidance systems have long been a key factor in keeping our airspace safe. Over the past decade, the FAA has supported the development of a new family of collision avoidance systems called the Airborne Collision Avoidance System X (ACAS X), which model the collision avoidance problem as a Markov decision process (MDP). Variants of ACAS X have been created for both manned (ACAS Xa) and unmanned aircraft (ACAS Xu and ACAS sXu). The variants primarily differ in the types of collision avoidance maneuvers they issue. For example, ACAS Xa issues vertical collision avoidance advisories, while ACAS Xu and ACAS sXu allow for horizontal advisories due to reduced aircraft performance capabilities. Currently, a new variant of ACAS X, called ACAS Xr, is being developed to provide collision avoidance capability to rotorcraft and Advanced Air Mobility (AAM) vehicles. Due to the desire to minimize deviation from the prescribed flight path of these aircraft, speed adjustments have been proposed as a potential collision avoidance maneuver for aircraft using ACAS Xr. In this work, we investigate the effect of speed change advisories on the safety and operational efficiency of collision avoidance systems. We develop an MDP-based collision avoidance logic that issues speed advisories and compare its performance to that of horizontal and vertical logics through Monte Carlo simulation on existing airspace encounter models. Our results show that while speed advisories are able to reduce collision risk, they are neither as safe nor as efficient as their horizontal and vertical counterparts.