 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristic Adaptation of Potentially Misspecified Domain Support for Likelihood-Free Inference in Stochastic Dynamical Systems
Oct 30, 2025In robotics, likelihood-free inference (LFI) can provide the domain distribution that adapts a learnt agent in a parametric set of deployment conditions. LFI assumes an arbitrary support for sampling, which remains constant as the initial generic prior is iteratively refined to more descriptive posteriors. However, a potentially misspecified support can lead to suboptimal, yet falsely certain, posteriors. To address this issue, we propose three heuristic LFI variants: EDGE, MODE, and CENTRE. Each interprets the posterior mode shift over inference steps in its own way and, when integrated into an LFI step, adapts the support alongside posterior inference. We first expose the support misspecification issue and evaluate our heuristics using stochastic dynamical benchmarks. We then evaluate the impact of heuristic support adaptation on parameter inference and policy learning for a dynamic deformable linear object (DLO) manipulation task. Inference results in a finer length and stiffness classification for a parametric set of DLOs. When the resulting posteriors are used as domain distributions for sim-based policy learning, they lead to more robust object-centric agent performance.
Conformance Checking of Fuzzy Logs against Declarative Temporal Specifications
Jun 17, 2024Traditional conformance checking tasks assume that event data provide a faithful and complete representation of the actual process executions. This assumption has been recently questioned: more and more often events are not traced explicitly, but are instead indirectly obtained as the result of event recognition pipelines, and thus inherently come with uncertainty. In this work, differently from the typical probabilistic interpretation of uncertainty, we consider the relevant case where uncertainty refers to which activity is actually conducted, under a fuzzy semantics. In this novel setting, we consider the problem of checking whether fuzzy event data conform with declarative temporal rules specified as Declare patterns or, more generally, as formulae of linear temporal logic over finite traces (LTLf). This requires to relax the assumption that at each instant only one activity is executed, and to correspondingly redefine boolean operators of the logic with a fuzzy semantics. Specifically, we provide a threefold contribution. First, we define a fuzzy counterpart of LTLf tailored to our purpose. Second, we cast conformance checking over fuzzy logs as a verification problem in this logic. Third, we provide a proof-of-concept, efficient implementation based on the PyTorch Python library, suited to check conformance of multiple fuzzy traces at once.
Unobtrusive Monitoring of Physical Weakness: A Simulated Approach
Jun 14, 2024Aging and chronic conditions affect older adults' daily lives, making early detection of developing health issues crucial. Weakness, common in many conditions, alters physical movements and daily activities subtly. However, detecting such changes can be challenging due to their subtle and gradual nature. To address this, we employ a non-intrusive camera sensor to monitor individuals' daily sitting and relaxing activities for signs of weakness. We simulate weakness in healthy subjects by having them perform physical exercise and observing the behavioral changes in their daily activities before and after workouts. The proposed system captures fine-grained features related to body motion, inactivity, and environmental context in real-time while prioritizing privacy. A Bayesian Network is used to model the relationships between features, activities, and health conditions. We aim to identify specific features and activities that indicate such changes and determine the most suitable time scale for observing the change. Results show 0.97 accuracy in distinguishing simulated weakness at the daily level. Fine-grained behavioral features, including non-dominant upper body motion speed and scale, and inactivity distribution, along with a 300-second window, are found most effective. However, individual-specific models are recommended as no universal set of optimal features and activities was identified across all participants.
Dialogue-based generation of self-driving simulation scenarios using Large Language Models
Oct 26, 2023



Simulation is an invaluable tool for developing and evaluating controllers for self-driving cars. Current simulation frameworks are driven by highly-specialist domain specific languages, and so a natural language interface would greatly enhance usability. But there is often a gap, consisting of tacit assumptions the user is making, between a concise English utterance and the executable code that captures the user's intent. In this paper we describe a system that addresses this issue by supporting an extended multimodal interaction: the user can follow up prior instructions with refinements or revisions, in reaction to the simulations that have been generated from their utterances so far. We use Large Language Models (LLMs) to map the user's English utterances in this interaction into domain-specific code, and so we explore the extent to which LLMs capture the context sensitivity that's necessary for computing the speaker's intended message in discourse.
Testing Rare Downstream Safety Violations via Upstream Adaptive Sampling of Perception Error Models
Sep 27, 2022



Testing black-box perceptual-control systems in simulation faces two difficulties. Firstly, perceptual inputs in simulation lack the fidelity of real-world sensor inputs. Secondly, for a reasonably accurate perception system, encountering a rare failure trajectory may require running infeasibly many simulations. This paper combines perception error models -- surrogates for a sensor-based detection system -- with state-dependent adaptive importance sampling. This allows us to efficiently assess the rare failure probabilities for real-world perceptual control systems within simulation. Our experiments with an autonomous braking system equipped with an RGB obstacle-detector show that our method can calculate accurate failure probabilities with an inexpensive number of simulations. Further, we show how choice of safety metric can influence the process of learning proposal distributions capable of reliably sampling high-probability failures.
Risk-Driven Design of Perception Systems
May 21, 2022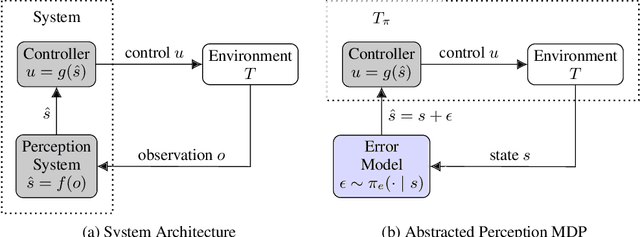

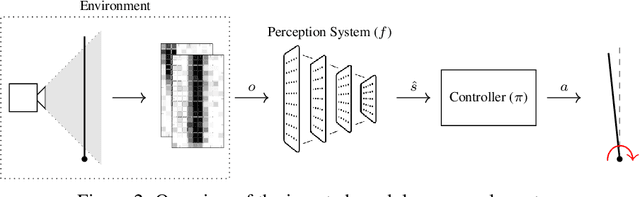

Modern autonomous systems rely on perception modules to process complex sensor measurements into state estimates. These estimates are then passed to a controller, which uses them to make safety-critical decisions. It is therefore important that we design perception systems to minimize errors that reduce the overall safety of the system. We develop a risk-driven approach to designing perception systems that accounts for the effect of perceptual errors on the performance of the fully-integrated, closed-loop system. We formulate a risk function to quantify the effect of a given perceptual error on overall safety, and show how we can use it to design safer perception systems by including a risk-dependent term in the loss function and generating training data in risk-sensitive regions. We evaluate our techniques on a realistic vision-based aircraft detect and avoid application and show that risk-driven design reduces collision risk by 37% over a baseline system.
Learning physics-informed simulation models for soft robotic manipulation: A case study with dielectric elastomer actuators
Feb 25, 2022
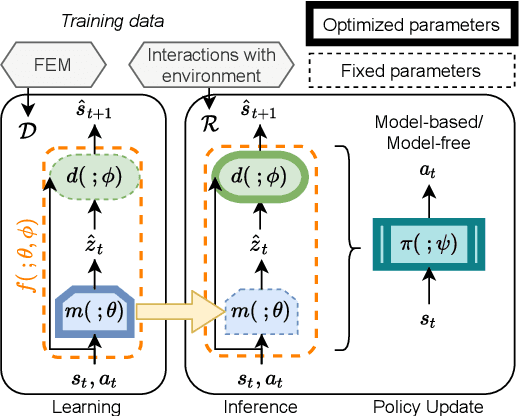
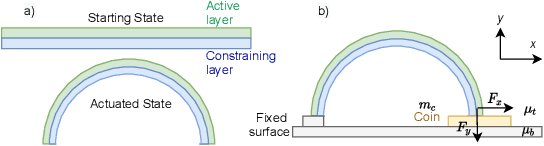

Soft actuators offer a safe and adaptable approach to robotic tasks like gentle grasping and dexterous movement. Creating accurate models to control such systems, however, is challenging due to the complex physics of deformable materials. Accurate Finite Element Method (FEM) models incur prohibitive computational complexity for closed-loop use. Using a differentiable simulator is an attractive alternative, but their applicability to soft actuators and deformable materials remains under-explored. This paper presents a framework that combines the advantages of both. We learn a differentiable model consisting of a material properties neural network and an analytical dynamics model of the remainder of the manipulation task. This physics-informed model is trained using data generated from FEM and can be used for closed-loop control and inference. We evaluate our framework on a dielectric elastomer actuator (DEA) coin-pulling task. We simulate DEA coin pulling in FEM, and design experiments to evaluate the physics-informed model for simulation, control, and inference. Our model attains < 5% simulation error compared to FEM, and we use it as the basis for an MPC controller that outperforms (i.e., requires fewer iterations to converge) a model-free actor-critic policy, a heuristic policy, and a PD controller.
Robust Learning from Observation with Model Misspecification
Feb 15, 2022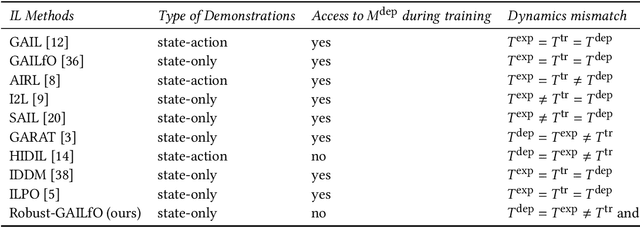
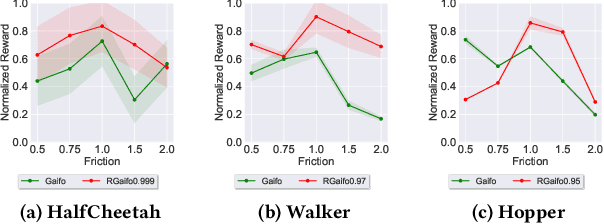
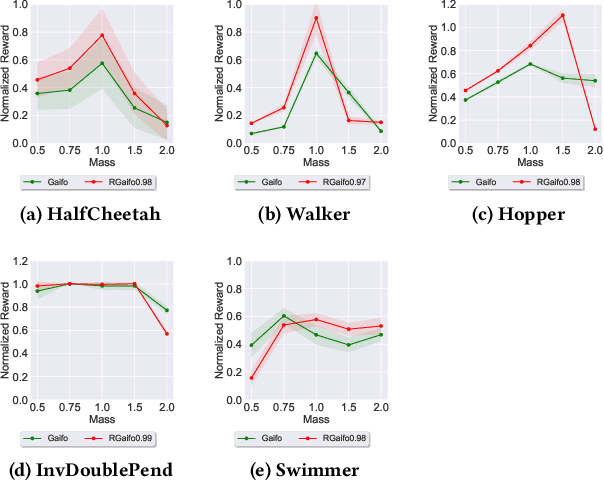
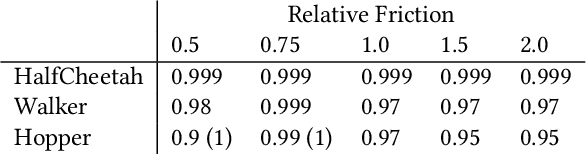
Imitation learning (IL) is a popular paradigm for training policies in robotic systems when specifying the reward function is difficult. However, despite the success of IL algorithms, they impose the somewhat unrealistic requirement that the expert demonstrations must come from the same domain in which a new imitator policy is to be learned. We consider a practical setting, where (i) state-only expert demonstrations from the real (deployment) environment are given to the learner, (ii) the imitation learner policy is trained in a simulation (training) environment whose transition dynamics is slightly different from the real environment, and (iii) the learner does not have any access to the real environment during the training phase beyond the batch of demonstrations given. Most of the current IL methods, such as generative adversarial imitation learning and its state-only variants, fail to imitate the optimal expert behavior under the above setting. By leveraging insights from the Robust reinforcement learning (RL) literature and building on recent adversarial imitation approaches, we propose a robust IL algorithm to learn policies that can effectively transfer to the real environment without fine-tuning. Furthermore, we empirically demonstrate on continuous-control benchmarks that our method outperforms the state-of-the-art state-only IL method in terms of the zero-shot transfer performance in the real environment and robust performance under different testing conditions.
Automated Testing with Temporal Logic Specifications for Robotic Controllers using Adaptive Experiment Design
Sep 16, 2021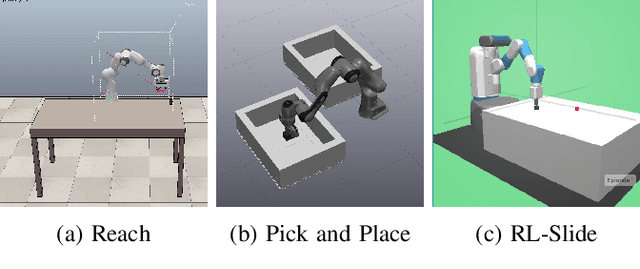
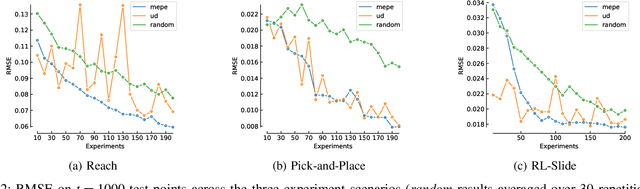
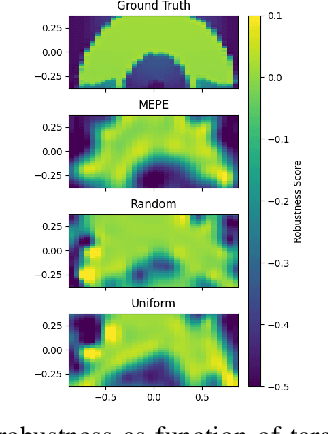
Many robot control scenarios involve assessing system robustness against a task specification. If either the controller or environment are composed of "black-box" components with unknown dynamics, we cannot rely on formal verification to assess our system. Assessing robustness via exhaustive testing is also often infeasible if the space of environments is large compared to experiment cost. Given limited budget, we provide a method to choose experiment inputs which give greatest insight into system performance against a given specification across the domain. By combining smooth robustness metrics for signal temporal logic with techniques from adaptive experiment design, our method chooses the most informative experimental inputs by incrementally constructing a surrogate model of the specification robustness. This model then chooses the next experiment to be in an area where there is either high prediction error or uncertainty. Our experiments show how this adaptive experimental design technique results in sample-efficient descriptions of system robustness. Further, we show how to use the model built via the experiment design process to assess the behaviour of a data-driven control system under domain shift.
ProbRobScene: A Probabilistic Specification Language for 3D Robotic Manipulation Environments
Nov 06, 2020

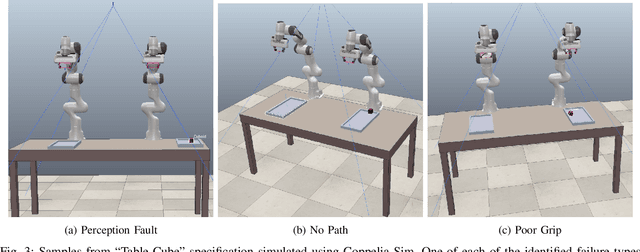

Robotic control tasks are often first run in simulation for the purposes of verification, debugging and data augmentation. Many methods exist to specify what task a robot must complete, but few exist to specify what range of environments a user expects such tasks to be achieved in. ProbRobScene is a probabilistic specification language for describing robotic manipulation environments. Using the language, a user need only specify the relational constraints that must hold between objects in a scene. ProbRobScene will then automatically generate scenes which conform to this specification. By combining aspects of probabilistic programming languages and convex geometry, we provide a method for sampling this space of possible environments efficiently. We demonstrate the usefulness of our language by using it to debug a robotic controller in a tabletop robot manipulation environment.