 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method
Sep 24, 2022

Dynamic Movement Primitives (DMPs) offer great versatility for encoding, generating and adapting complex end-effector trajectories. DMPs are also very well suited to learning manipulation skills from human demonstration. However, the reactive nature of DMPs restricts their applicability for tool use and object manipulation tasks involving non-holonomic constraints, such as scalpel cutting or catheter steering. In this work, we extend the Cartesian space DMP formulation by adding a coupling term that enforces a pre-defined set of non-holonomic constraints. We obtain the closed-form expression for the constraint forcing term using the Udwadia-Kalaba method. This approach offers a clean and practical solution for guaranteed constraint satisfaction at run-time. Further, the proposed analytical form of the constraint forcing term enables efficient trajectory optimization subject to constraints. We demonstrate the usefulness of this approach by showing how we can learn robotic cutting skills from human demonstration.
Learning robotic ultrasound scanning using probabilistic temporal ranking
Feb 04, 2020This paper addresses a common class of problems where a robot learns to perform a discovery task based on example solutions, or human demonstrations. For example consider the problem of ultrasound scanning, where the demonstration requires that an expert adaptively searches for a satisfactory view of internal organs, vessels or tissue and potential anomalies while maintaining optimal contact between the probe and surface tissue. Such problems are currently solved by inferring notional rewards that, when optimised for, result in a plan that mimics demonstrations. A pivotal assumption, that plans with higher reward should be exponentially more likely, leads to the de facto approach for reward inference in robotics. While this approach of maximum entropy inverse reinforcement learning leads to a general and elegant formulation, it struggles to cope with frequently encountered sub-optimal demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where sub-optimal demonstrations occur frequently. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward. We formalise this temporal ranking approach and show that it improves upon maximum-entropy approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging.
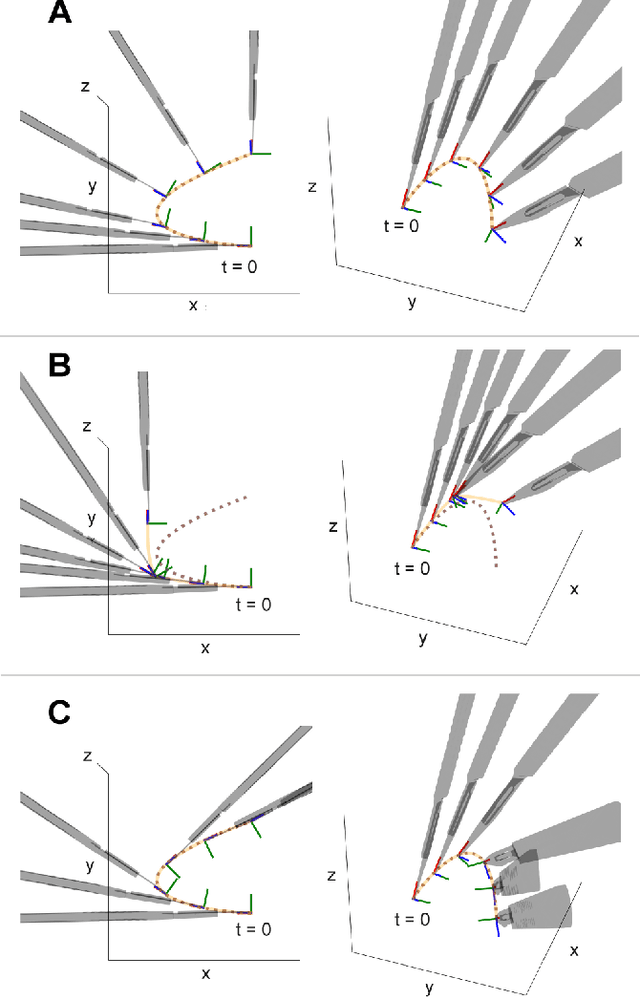
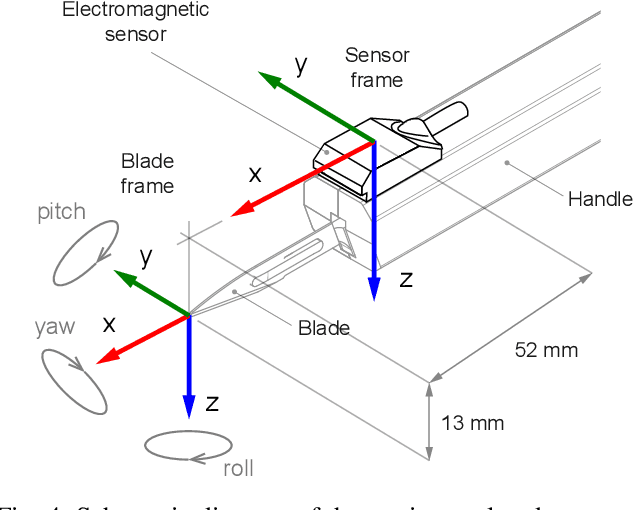
Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification
Sep 16, 2019

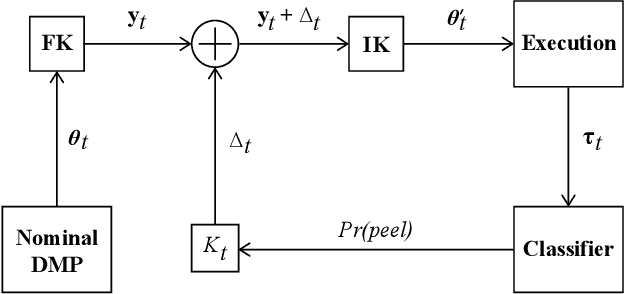

Precision cutting of soft-tissue remains a challenging problem in robotics, due to the complex and unpredictable mechanical behaviour of tissue under manipulation. Here, we consider the challenge of cutting along the boundary between two soft mediums, a problem that is made extremely difficult due to visibility constraints, which means that the precise location of the cutting trajectory is typically unknown. This paper introduces a novel strategy to address this task, using a binary medium classifier trained using joint torque measurements, and a closed loop control law that relies on an error signal compactly encoded in the decision boundary of the classifier. We illustrate this on a grapefruit cutting task, successfully modulating a nominal trajectory fit using dynamic movement primitives to follow the boundary between grapefruit pulp and peel using torque based medium classification. Results show that this control strategy is successful in 72 % of attempts in contrast to control using a nominal trajectory, which only succeeds in 50 % of attempts.