 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Demonstrations to Task-Space Specifications: Using Causal Analysis to Extract Rule Parameterization from Demonstrations
Jun 08, 2020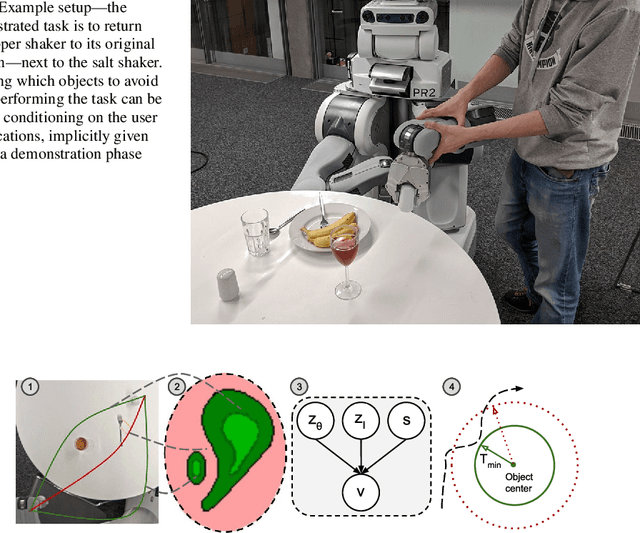


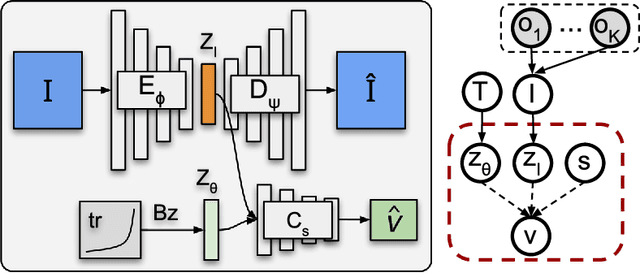
Learning models of user behaviour is an important problem that is broadly applicable across many application domains requiring human-robot interaction. In this work, we show that it is possible to learn generative models for distinct user behavioural types, extracted from human demonstrations, by enforcing clustering of preferred task solutions within the latent space. We use these models to differentiate between user types and to find cases with overlapping solutions. Moreover, we can alter an initially guessed solution to satisfy the preferences that constitute a particular user type by backpropagating through the learned differentiable models. An advantage of structuring generative models in this way is that we can extract causal relationships between symbols that might form part of the user's specification of the task, as manifested in the demonstrations. We further parameterize these specifications through constraint optimization in order to find a safety envelope under which motion planning can be performed. We show that the proposed method is capable of correctly distinguishing between three user types, who differ in degrees of cautiousness in their motion, while performing the task of moving objects with a kinesthetically driven robot in a tabletop environment. Our method successfully identifies the correct type, within the specified time, in 99% [97.8 - 99.8] of the cases, which outperforms an IRL baseline. We also show that our proposed method correctly changes a default trajectory to one satisfying a particular user specification even with unseen objects. The resulting trajectory is shown to be directly implementable on a PR2 humanoid robot completing the same task.
Learning robotic ultrasound scanning using probabilistic temporal ranking
Feb 04, 2020This paper addresses a common class of problems where a robot learns to perform a discovery task based on example solutions, or human demonstrations. For example consider the problem of ultrasound scanning, where the demonstration requires that an expert adaptively searches for a satisfactory view of internal organs, vessels or tissue and potential anomalies while maintaining optimal contact between the probe and surface tissue. Such problems are currently solved by inferring notional rewards that, when optimised for, result in a plan that mimics demonstrations. A pivotal assumption, that plans with higher reward should be exponentially more likely, leads to the de facto approach for reward inference in robotics. While this approach of maximum entropy inverse reinforcement learning leads to a general and elegant formulation, it struggles to cope with frequently encountered sub-optimal demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where sub-optimal demonstrations occur frequently. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward. We formalise this temporal ranking approach and show that it improves upon maximum-entropy approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging.
Disentangled Relational Representations for Explaining and Learning from Demonstration
Jul 31, 2019
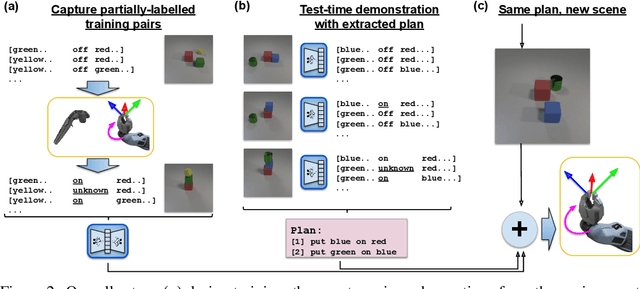


Learning from demonstration is an effective method for human users to instruct desired robot behaviour. However, for most non-trivial tasks of practical interest, efficient learning from demonstration depends crucially on inductive bias in the chosen structure for rewards/costs and policies. We address the case where this inductive bias comes from an exchange with a human user. We propose a method in which a learning agent utilizes the information bottleneck layer of a high-parameter variational neural model, with auxiliary loss terms, in order to ground abstract concepts such as spatial relations. The concepts are referred to in natural language instructions and are manifested in the high-dimensional sensory input stream the agent receives from the world. We evaluate the properties of the latent space of the learned model in a photorealistic synthetic environment and particularly focus on examining its usability for downstream tasks. Additionally, through a series of controlled table-top manipulation experiments, we demonstrate that the learned manifold can be used to ground demonstrations as symbolic plans, which can then be executed on a PR2 robot.
Composing Diverse Policies for Temporally Extended Tasks
Jul 18, 2019
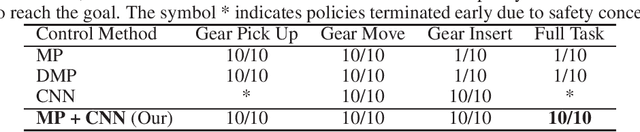

Temporally extended and sequenced robot motion tasks are often characterized by discontinuous switches between different types of local dynamics. These change-points can be exploited to build approximate models of the interleaving regions, which in turn allow the design of region-specific controllers. These can then be combined to create the initiation state-space of a final policy. However, such a pipeline can become challenging to implement for combinatorially complex, temporarily extended tasks - especially so when sub-controllers work on different information streams, time scales and action spaces. In this paper, we introduce a method that can compose diverse policies based on scripted motion planning, dynamic motion primitives and neural networks. In order to do this, we extend the options framework to introduce a per-option dynamics module and a global function that evaluates a goal metric. Additionally, we can leverage expert demonstrations to sequence these local policies, converting the learning problem in hierarchical reinforcement learning to a planning problem at inference time. We first illustrate the core concepts with an MDP benchmark, and then with a physical gear assembly task solved on a PR2 robot. We show that the proposed approach successfully discovers the optimal sequence of policies and solves both tasks efficiently.
Vid2Param: Online system identification from video for robotics applications
Jul 15, 2019

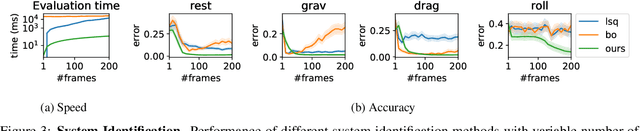
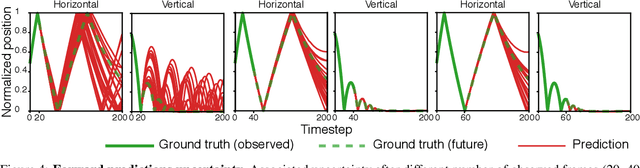
Robots performing tasks in dynamic environments would benefit greatly from understanding the underlying environment motion, in order to make future predictions and to synthesize effective control policies that use this inductive bias. Online system identification is therefore a fundamental requirement for robust autonomous agents. When the dynamics involves multiple modes (due to contacts or interactions between objects), and when system identification must proceed directly from a rich sensory stream such as video, then traditional methods for system identification may not be well suited. We propose an approach wherein fast parameter estimation with a model can be seamlessly combined with a recurrent variational autoencoder. Our Physics-based recurrent variational autoencoder model includes an additional loss that enforces conformity with the structure of a physically based dynamics model. This enables the resulting model to encode parameters such as position, velocity, restitution, air drag and other physical properties of the system. The model can be trained entirely in simulation, in an end-to-end manner with domain randomization, to perform online system identification, and probabilistic forward predictions of parameters of interest. We benchmark against existing system identification methods and demonstrate that Vid2Param outperforms the baselines in terms of speed and accuracy of identification, and also provides uncertainty quantification in the form of a distribution over future trajectories. Furthermore, we illustrate the utility of this in physical experiments wherein a PR2 robot with velocity constrained arm must intercept a bouncing ball, by estimating the physical parameters of this ball directly from the video trace after the ball is released.
DynoPlan: Combining Motion Planning and Deep Neural Network based Controllers for Safe HRL
Jun 24, 2019
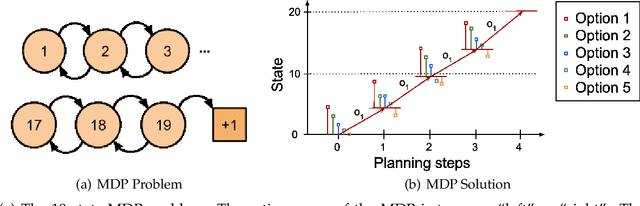
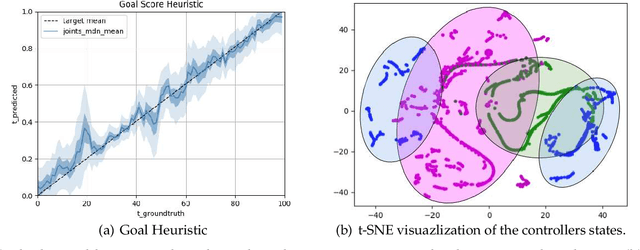
Many realistic robotics tasks are best solved compositionally, through control architectures that sequentially invoke primitives and achieve error correction through the use of loops and conditionals taking the system back to alternative earlier states. Recent end-to-end approaches to task learning attempt to directly learn a single controller that solves an entire task, but this has been difficult for complex control tasks that would have otherwise required a diversity of local primitive moves, and the resulting solutions are also not easy to inspect for plan monitoring purposes. In this work, we aim to bridge the gap between hand designed and learned controllers, by representing each as an option in a hybrid hierarchical Reinforcement Learning framework - DynoPlan. We extend the options framework by adding a dynamics model and the use of a nearness-to-goal heuristic, derived from demonstrations. This translates the optimization of a hierarchical policy controller to a problem of planning with a model predictive controller. By unrolling the dynamics of each option and assessing the expected value of each future state, we can create a simple switching controller for choosing the optimal policy within a constrained time horizon similarly to hill climbing heuristic search. The individual dynamics model allows each option to iterate and be activated independently of the specific underlying instantiation, thus allowing for a mix of motion planning and deep neural network based primitives. We can assess the safety regions of the resulting hybrid controller by investigating the initiation sets of the different options, and also by reasoning about the completeness and performance guarantees of the underpinning motion planners.
Using Causal Analysis to Learn Specifications from Task Demonstrations
Mar 04, 2019


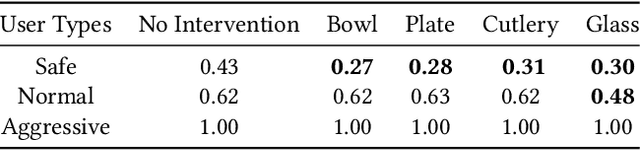
Learning models of user behaviour is an important problem that is broadly applicable across many application domains requiring human-robot interaction. In this work we show that it is possible to learn a generative model for distinct user behavioral types, extracted from human demonstrations, by enforcing clustering of preferred task solutions within the latent space. We use this model to differentiate between user types and to find cases with overlapping solutions. Moreover, we can alter an initially guessed solution to satisfy the preferences that constitute a particular user type by backpropagating through the learned differentiable model. An advantage of structuring generative models in this way is that it allows us to extract causal relationships between symbols that might form part of the user's specification of the task, as manifested in the demonstrations. We show that the proposed method is capable of correctly distinguishing between three user types, who differ in degrees of cautiousness in their motion, while performing the task of moving objects with a kinesthetically driven robot in a tabletop environment. Our method successfully identifies the correct type, within the specified time, in 99% [97.8 - 99.8] of the cases, which outperforms an IRL baseline. We also show that our proposed method correctly changes a default trajectory to one satisfying a particular user specification even with unseen objects. The resulting trajectory is shown to be directly implementable on a PR2 humanoid robot completing the same task.