 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning with Narrative Twins for Modeling Story Salience
Jan 12, 2026Understanding narratives requires identifying which events are most salient for a story's progression. We present a contrastive learning framework for modeling narrative salience that learns story embeddings from narrative twins: stories that share the same plot but differ in surface form. Our model is trained to distinguish a story from both its narrative twin and a distractor with similar surface features but different plot. Using the resulting embeddings, we evaluate four narratologically motivated operations for inferring salience (deletion, shifting, disruption, and summarization). Experiments on short narratives from the ROCStories corpus and longer Wikipedia plot summaries show that contrastively learned story embeddings outperform a masked-language-model baseline, and that summarization is the most reliable operation for identifying salient sentences. If narrative twins are not available, random dropout can be used to generate the twins from a single story. Effective distractors can be obtained either by prompting LLMs or, in long-form narratives, by using different parts of the same story.
Plancraft: an evaluation dataset for planning with LLM agents
Dec 30, 2024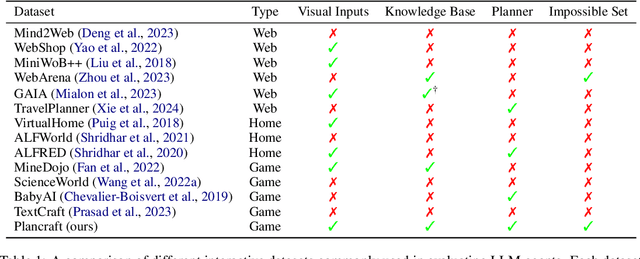


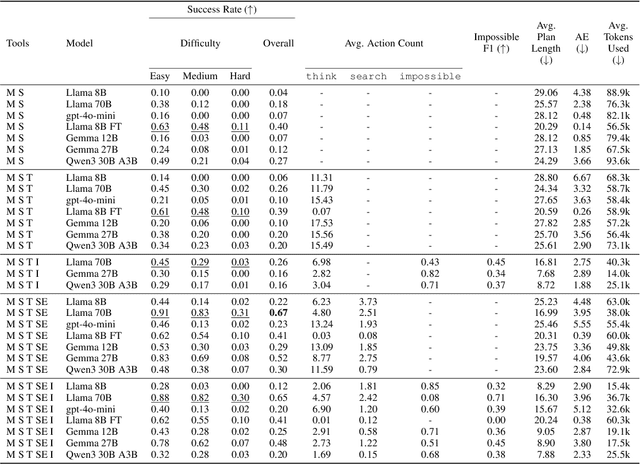
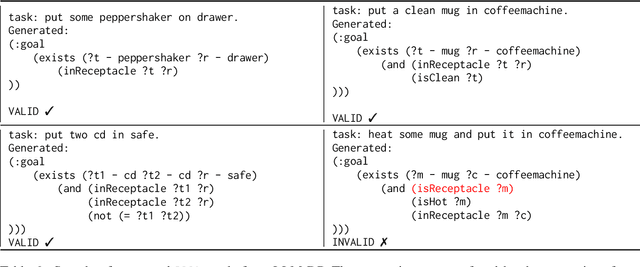
We present Plancraft, a multi-modal evaluation dataset for LLM agents. Plancraft has both a text-only and multi-modal interface, based on the Minecraft crafting GUI. We include the Minecraft Wiki to evaluate tool use and Retrieval Augmented Generation (RAG), as well as an oracle planner and oracle RAG information extractor, to ablate the different components of a modern agent architecture. To evaluate decision-making, Plancraft also includes a subset of examples that are intentionally unsolvable, providing a realistic challenge that requires the agent not only to complete tasks but also to decide whether they are solvable at all. We benchmark both open-source and closed-source LLMs and strategies on our task and compare their performance to a handcrafted planner. We find that LLMs and VLMs struggle with the planning problems that Plancraft introduces, and we offer suggestions on how to improve their capabilities.
Learning Visually Grounded Domain Ontologies via Embodied Conversation and Explanation
Dec 13, 2024In this paper, we offer a learning framework in which the agent's knowledge gaps are overcome through corrective feedback from a teacher whenever the agent explains its (incorrect) predictions. We test it in a low-resource visual processing scenario, in which the agent must learn to recognize distinct types of toy truck. The agent starts the learning process with no ontology about what types of trucks exist nor which parts they have, and a deficient model for recognizing those parts from visual input. The teacher's feedback to the agent's explanations addresses its lack of relevant knowledge in the ontology via a generic rule (e.g., "dump trucks have dumpers"), whereas an inaccurate part recognition is corrected by a deictic statement (e.g., "this is not a dumper"). The learner utilizes this feedback not only to improve its estimate of the hypothesis space of possible domain ontologies and probability distributions over them, but also to use those estimates to update its visual interpretation of the scene. Our experiments demonstrate that teacher-learner pairs utilizing explanations and corrections are more data-efficient than those without such a faculty.
Generating Driving Simulations via Conversation
Oct 13, 2024Cyber-physical systems like autonomous vehicles are tested in simulation before deployment, using domain-specific programs for scenario specification. To aid the testing of autonomous vehicles in simulation, we design a natural language interface, using an instruction-following large language model, to assist a non-coding domain expert in synthesising the desired scenarios and vehicle behaviours. We show that using it to convert utterances to the symbolic program is feasible, despite the very small training dataset. Human experiments show that dialogue is critical to successful simulation generation, leading to a 4.5 times higher success rate than a generation without engaging in extended conversation.
SECURE: Semantics-aware Embodied Conversation under Unawareness for Lifelong Robot Learning
Sep 26, 2024



This paper addresses a challenging interactive task learning scenario we call rearrangement under unawareness: to manipulate a rigid-body environment in a context where the robot is unaware of a concept that's key to solving the instructed task. We propose SECURE, an interactive task learning framework designed to solve such problems by fixing a deficient domain model using embodied conversation. Through dialogue, the robot discovers and then learns to exploit unforeseen possibilities. Using SECURE, the robot not only learns from the user's corrective feedback when it makes a mistake, but it also learns to make strategic dialogue decisions for revealing useful evidence about novel concepts for solving the instructed task. Together, these abilities allow the robot to generalise to subsequent tasks using newly acquired knowledge. We demonstrate that a robot that is semantics-aware -- that is, it exploits the logical consequences of both sentence and discourse semantics in the learning and inference process -- learns to solve rearrangement under unawareness more effectively than a robot that lacks such capabilities.
Dialogue-based generation of self-driving simulation scenarios using Large Language Models
Oct 26, 2023



Simulation is an invaluable tool for developing and evaluating controllers for self-driving cars. Current simulation frameworks are driven by highly-specialist domain specific languages, and so a natural language interface would greatly enhance usability. But there is often a gap, consisting of tacit assumptions the user is making, between a concise English utterance and the executable code that captures the user's intent. In this paper we describe a system that addresses this issue by supporting an extended multimodal interaction: the user can follow up prior instructions with refinements or revisions, in reaction to the simulations that have been generated from their utterances so far. We use Large Language Models (LLMs) to map the user's English utterances in this interaction into domain-specific code, and so we explore the extent to which LLMs capture the context sensitivity that's necessary for computing the speaker's intended message in discourse.
Dynamic Planning with a LLM
Aug 11, 2023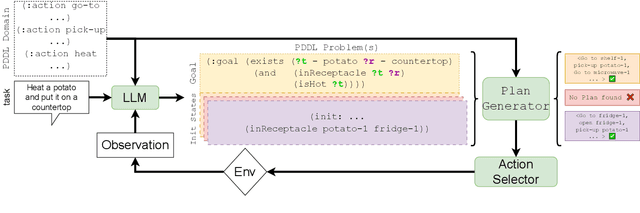
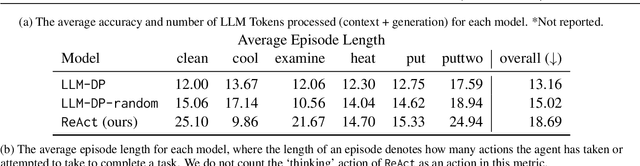

While Large Language Models (LLMs) can solve many NLP tasks in zero-shot settings, applications involving embodied agents remain problematic. In particular, complex plans that require multi-step reasoning become difficult and too costly as the context window grows. Planning requires understanding the likely effects of one's actions and identifying whether the current environment satisfies the goal state. While symbolic planners find optimal solutions quickly, they require a complete and accurate representation of the planning problem, severely limiting their use in practical scenarios. In contrast, modern LLMs cope with noisy observations and high levels of uncertainty when reasoning about a task. Our work presents LLM Dynamic Planner (LLM-DP): a neuro-symbolic framework where an LLM works hand-in-hand with a traditional planner to solve an embodied task. Given action-descriptions, LLM-DP solves Alfworld faster and more efficiently than a naive LLM ReAct baseline.
Interactive Acquisition of Fine-grained Visual Concepts by Exploiting Semantics of Generic Characterizations in Discourse
May 05, 2023Interactive Task Learning (ITL) concerns learning about unforeseen domain concepts via natural interactions with human users. The learner faces a number of significant constraints: learning should be online, incremental and few-shot, as it is expected to perform tangible belief updates right after novel words denoting unforeseen concepts are introduced. In this work, we explore a challenging symbol grounding task--discriminating among object classes that look very similar--within the constraints imposed by ITL. We demonstrate empirically that more data-efficient grounding results from exploiting the truth-conditions of the teacher's generic statements (e.g., "Xs have attribute Z.") and their implicatures in context (e.g., as an answer to "How are Xs and Ys different?", one infers Y lacks attribute Z).
Learning Manner of Execution from Partial Corrections
Feb 07, 2023



Some actions must be executed in different ways depending on the context. For example, wiping away marker requires vigorous force while wiping away almonds requires more gentle force. In this paper we provide a model where an agent learns which manner of action execution to use in which context, drawing on evidence from trial and error and verbal corrections when it makes a mistake (e.g., ``no, gently''). The learner starts out with a domain model that lacks the concepts denoted by the words in the teacher's feedback; both the words describing the context (e.g., marker) and the adverbs like ``gently''. We show that through the the semantics of coherence, our agent can perform the symbol grounding that's necessary for exploiting the teacher's feedback so as to solve its domain-level planning problem: to perform its actions in the current context in the right way.
Learning the Effects of Physical Actions in a Multi-modal Environment
Feb 03, 2023Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.