 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlancraft: an evaluation dataset for planning with LLM agents
Dec 30, 2024


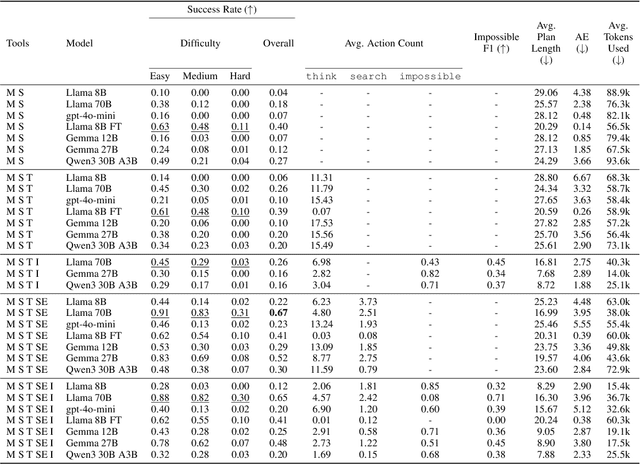
We present Plancraft, a multi-modal evaluation dataset for LLM agents. Plancraft has both a text-only and multi-modal interface, based on the Minecraft crafting GUI. We include the Minecraft Wiki to evaluate tool use and Retrieval Augmented Generation (RAG), as well as an oracle planner and oracle RAG information extractor, to ablate the different components of a modern agent architecture. To evaluate decision-making, Plancraft also includes a subset of examples that are intentionally unsolvable, providing a realistic challenge that requires the agent not only to complete tasks but also to decide whether they are solvable at all. We benchmark both open-source and closed-source LLMs and strategies on our task and compare their performance to a handcrafted planner. We find that LLMs and VLMs struggle with the planning problems that Plancraft introduces, and we offer suggestions on how to improve their capabilities.
CAST: Cross-modal Alignment Similarity Test for Vision Language Models
Sep 17, 2024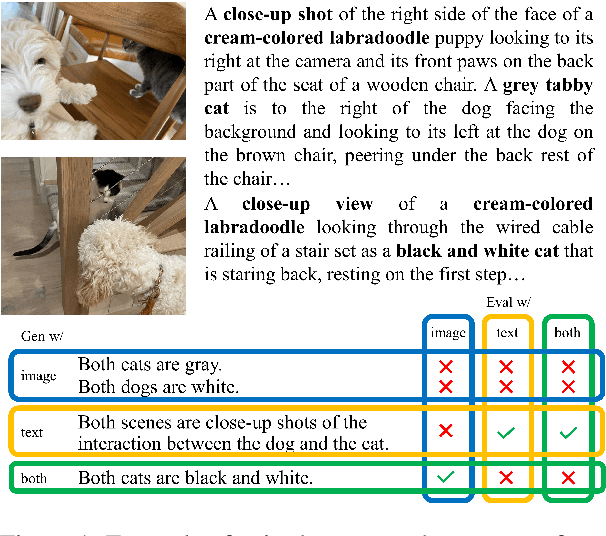
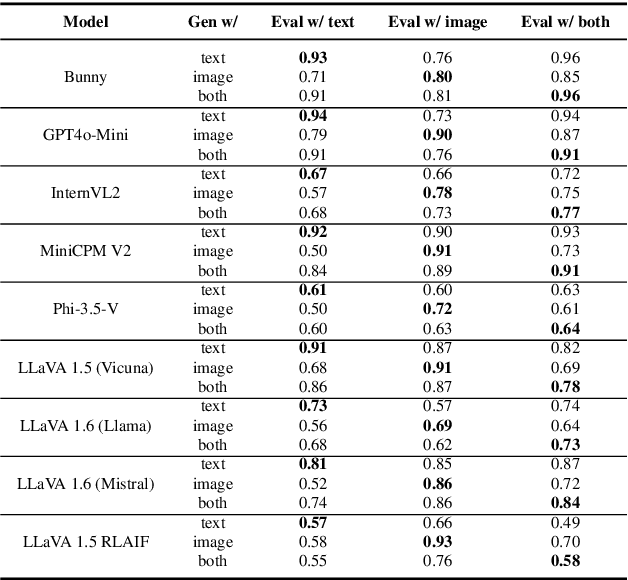
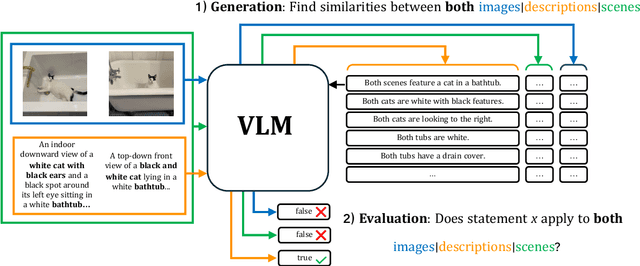

Vision Language Models (VLMs) are typically evaluated with Visual Question Answering (VQA) tasks which assess a model's understanding of scenes. Good VQA performance is taken as evidence that the model will perform well on a broader range of tasks that require both visual and language inputs. However, scene-aware VQA does not fully capture input biases or assess hallucinations caused by a misalignment between modalities. To address this, we propose a Cross-modal Alignment Similarity Test (CAST) to probe VLMs for self-consistency across modalities. This test involves asking the models to identify similarities between two scenes through text-only, image-only, or both and then assess the truthfulness of the similarities they generate. Since there is no ground-truth to compare against, this evaluation does not focus on objective accuracy but rather on whether VLMs are internally consistent in their outputs. We argue that while not all self-consistent models are capable or accurate, all capable VLMs must be self-consistent.
Getting the most out of your tokenizer for pre-training and domain adaptation
Feb 07, 2024



Tokenization is an understudied and often neglected component of modern LLMs. Most published works use a single tokenizer for all experiments, often borrowed from another model, without performing ablations or analysis to optimize tokenization. Moreover, the tokenizer is generally kept unchanged when fine-tuning a base model. In this paper, we show that the size, pre-tokenization regular expression, and training data of a tokenizer can significantly impact the model's generation speed, effective context size, memory usage, and downstream performance. We train specialized Byte-Pair Encoding code tokenizers, and conduct extensive ablations on the impact of tokenizer design on the performance of LLMs for code generation tasks such as HumanEval and MBPP, and provide recommendations for tokenizer hyper-parameters selection and switching the tokenizer in a pre-trained LLM. We perform our experiments on models trained from scratch and from pre-trained models, verifying their applicability to a wide range of use-cases. We find that when fine-tuning on more than 50 billion tokens, we can specialize the tokenizer of a pre-trained LLM to obtain large gains in generation speed and effective context size.
Dynamic Planning with a LLM
Aug 11, 2023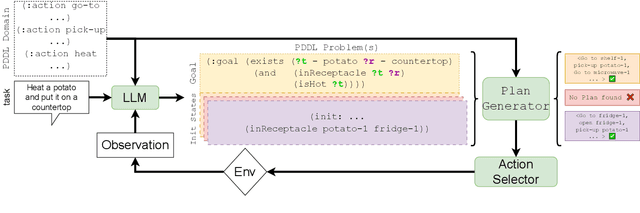
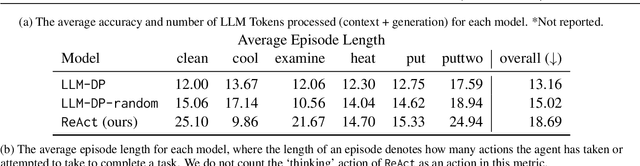

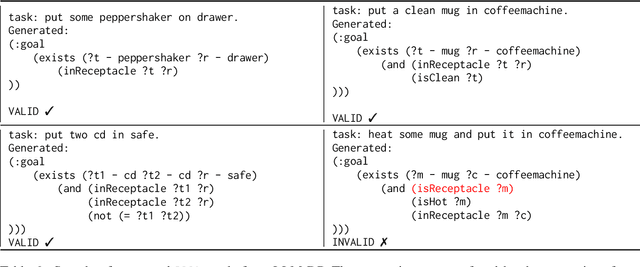
While Large Language Models (LLMs) can solve many NLP tasks in zero-shot settings, applications involving embodied agents remain problematic. In particular, complex plans that require multi-step reasoning become difficult and too costly as the context window grows. Planning requires understanding the likely effects of one's actions and identifying whether the current environment satisfies the goal state. While symbolic planners find optimal solutions quickly, they require a complete and accurate representation of the planning problem, severely limiting their use in practical scenarios. In contrast, modern LLMs cope with noisy observations and high levels of uncertainty when reasoning about a task. Our work presents LLM Dynamic Planner (LLM-DP): a neuro-symbolic framework where an LLM works hand-in-hand with a traditional planner to solve an embodied task. Given action-descriptions, LLM-DP solves Alfworld faster and more efficiently than a naive LLM ReAct baseline.
Learning the Effects of Physical Actions in a Multi-modal Environment
Feb 03, 2023Large Language Models (LLMs) handle physical commonsense information inadequately. As a result of being trained in a disembodied setting, LLMs often fail to predict an action's outcome in a given environment. However, predicting the effects of an action before it is executed is crucial in planning, where coherent sequences of actions are often needed to achieve a goal. Therefore, we introduce the multi-modal task of predicting the outcomes of actions solely from realistic sensory inputs (images and text). Next, we extend an LLM to model latent representations of objects to better predict action outcomes in an environment. We show that multi-modal models can capture physical commonsense when augmented with visual information. Finally, we evaluate our model's performance on novel actions and objects and find that combining modalities help models to generalize and learn physical commonsense reasoning better.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Co-evolution of language and agents in referential games
Jan 10, 2020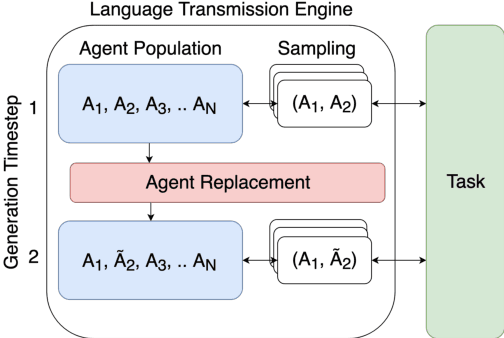
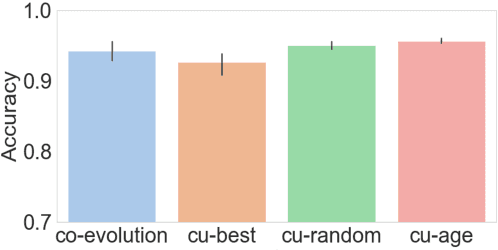
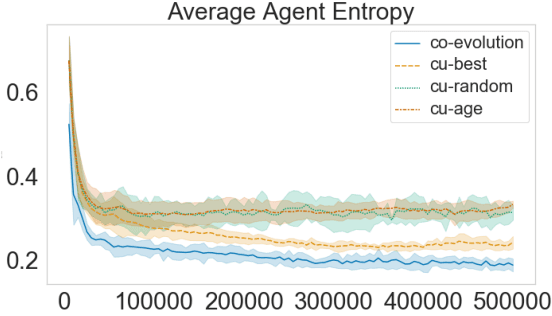
Referential games offer a grounded learning environment for neural agents, that accounts for the functional aspects of language. However, they fail to account for another fundamental aspect of human language: Because languages are transmitted from generation to generation, they have to be learnable by new language users, which makes them subject to cultural evolution. Recent work has shown that incorporating cultural evolution in referential game results in considerable improvements in the properties of the languages that emerge in the game. In this work, we first substantiate this claim with a different data set and a wider array of evaluation metrics. Then, drawing inspiration from linguistic theories of human language evolution, we consider a scenario in which not only cultural but also genetic evolution is integrated. As our core contribution, we introduce the Language Transmission Engine, in which cultural evolution of the language is combined with genetic evolution of the agents' architecture. We show that this co-evolution scenario leads to across-the-board improvements on all considered metrics. These results stress that cultural evolution is important for language emergence studies, but also the suitability of the architecture itself should be considered.
Location Attention for Extrapolation to Longer Sequences
Nov 10, 2019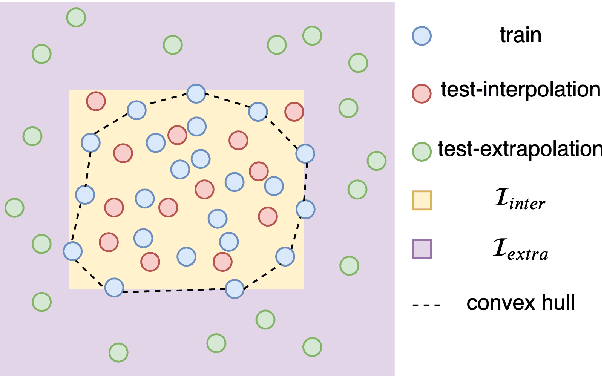
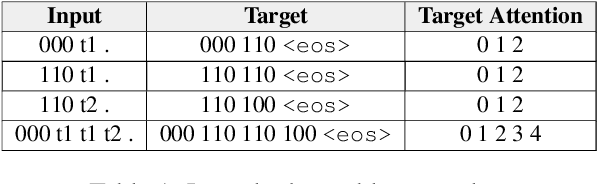
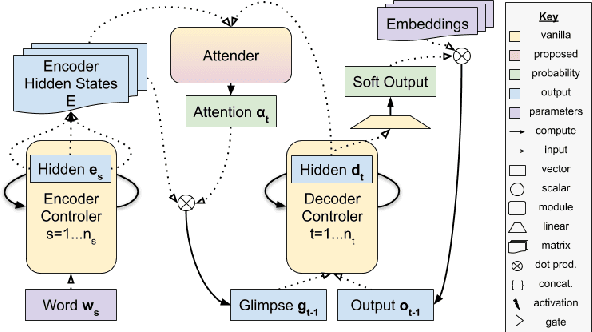
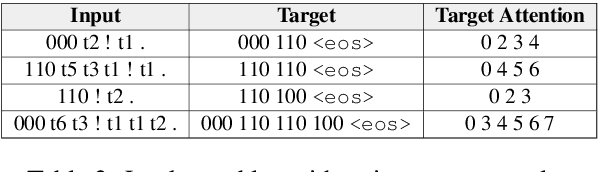
Neural networks are surprisingly good at interpolating and perform remarkably well when the training set examples resemble those in the test set. However, they are often unable to extrapolate patterns beyond the seen data, even when the abstractions required for such patterns are simple. In this paper, we first review the notion of extrapolation, why it is important and how one could hope to tackle it. We then focus on a specific type of extrapolation which is especially useful for natural language processing: generalization to sequences that are longer than the training ones. We hypothesize that models with a separate content- and location-based attention are more likely to extrapolate than those with common attention mechanisms. We empirically support our claim for recurrent seq2seq models with our proposed attention on variants of the Lookup Table task. This sheds light on some striking failures of neural models for sequences and on possible methods to approaching such issues.