 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Implicit Arguments in Procedural Video Instructions
May 27, 2025Procedural texts help AI enhance reasoning about context and action sequences. Transforming these into Semantic Role Labeling (SRL) improves understanding of individual steps by identifying predicate-argument structure like {verb,what,where/with}. Procedural instructions are highly elliptic, for instance, (i) add cucumber to the bowl and (ii) add sliced tomatoes, the second step's where argument is inferred from the context, referring to where the cucumber was placed. Prior SRL benchmarks often miss implicit arguments, leading to incomplete understanding. To address this, we introduce Implicit-VidSRL, a dataset that necessitates inferring implicit and explicit arguments from contextual information in multimodal cooking procedures. Our proposed dataset benchmarks multimodal models' contextual reasoning, requiring entity tracking through visual changes in recipes. We study recent multimodal LLMs and reveal that they struggle to predict implicit arguments of what and where/with from multi-modal procedural data given the verb. Lastly, we propose iSRL-Qwen2-VL, which achieves a 17% relative improvement in F1-score for what-implicit and a 14.7% for where/with-implicit semantic roles over GPT-4o.
CAST: Cross-modal Alignment Similarity Test for Vision Language Models
Sep 17, 2024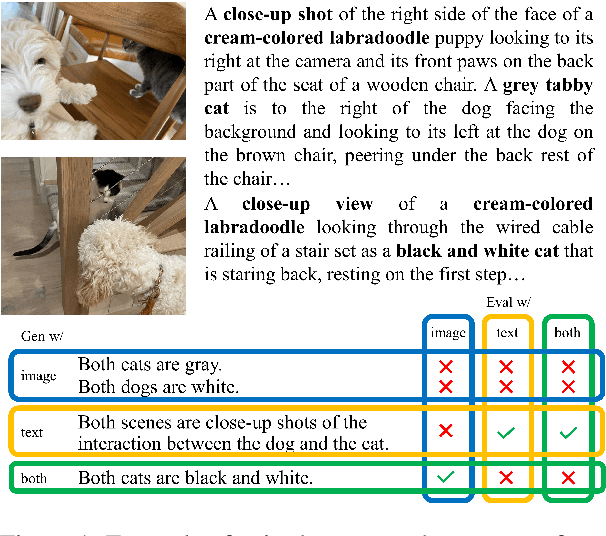
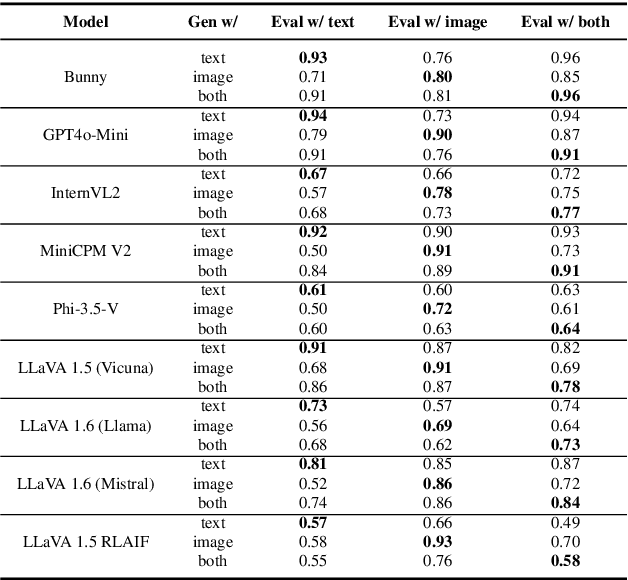
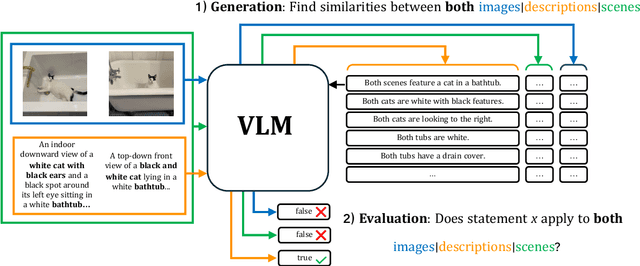

Vision Language Models (VLMs) are typically evaluated with Visual Question Answering (VQA) tasks which assess a model's understanding of scenes. Good VQA performance is taken as evidence that the model will perform well on a broader range of tasks that require both visual and language inputs. However, scene-aware VQA does not fully capture input biases or assess hallucinations caused by a misalignment between modalities. To address this, we propose a Cross-modal Alignment Similarity Test (CAST) to probe VLMs for self-consistency across modalities. This test involves asking the models to identify similarities between two scenes through text-only, image-only, or both and then assess the truthfulness of the similarities they generate. Since there is no ground-truth to compare against, this evaluation does not focus on objective accuracy but rather on whether VLMs are internally consistent in their outputs. We argue that while not all self-consistent models are capable or accurate, all capable VLMs must be self-consistent.
Efficient Pre-training for Localized Instruction Generation of Videos
Nov 27, 2023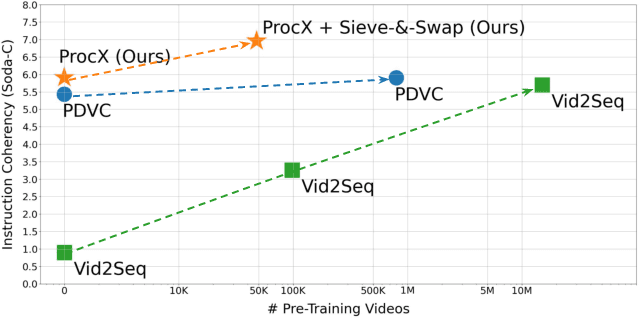


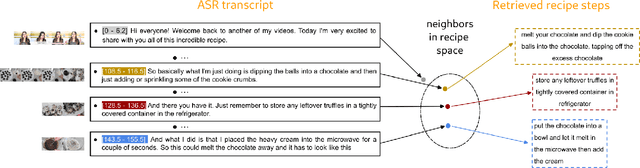
Procedural videos show step-by-step demonstrations of tasks like recipe preparation. Understanding such videos is challenging, involving the precise localization of steps and the generation of textual instructions. Manually annotating steps and writing instructions is costly, which limits the size of current datasets and hinders effective learning. Leveraging large but noisy video-transcript datasets for pre-training can boost performance, but demands significant computational resources. Furthermore, transcripts contain irrelevant content and exhibit style variation compared to instructions written by human annotators. To mitigate both issues, we propose a technique, Sieve-&-Swap, to automatically curate a smaller dataset: (i) Sieve filters irrelevant transcripts and (ii) Swap enhances the quality of the text instruction by automatically replacing the transcripts with human-written instructions from a text-only recipe dataset. The curated dataset, three orders of magnitude smaller than current web-scale datasets, enables efficient training of large-scale models with competitive performance. We complement our Sieve-\&-Swap approach with a Procedure Transformer (ProcX) for end-to-end step localization and instruction generation for procedural videos. When this model is pre-trained on our curated dataset, it achieves state-of-the-art performance in zero-shot and finetuning settings on YouCook2 and Tasty, while using a fraction of the computational resources.
Image generation with shortest path diffusion
Jun 01, 2023The field of image generation has made significant progress thanks to the introduction of Diffusion Models, which learn to progressively reverse a given image corruption. Recently, a few studies introduced alternative ways of corrupting images in Diffusion Models, with an emphasis on blurring. However, these studies are purely empirical and it remains unclear what is the optimal procedure for corrupting an image. In this work, we hypothesize that the optimal procedure minimizes the length of the path taken when corrupting an image towards a given final state. We propose the Fisher metric for the path length, measured in the space of probability distributions. We compute the shortest path according to this metric, and we show that it corresponds to a combination of image sharpening, rather than blurring, and noise deblurring. While the corruption was chosen arbitrarily in previous work, our Shortest Path Diffusion (SPD) determines uniquely the entire spatiotemporal structure of the corruption. We show that SPD improves on strong baselines without any hyperparameter tuning, and outperforms all previous Diffusion Models based on image blurring. Furthermore, any small deviation from the shortest path leads to worse performance, suggesting that SPD provides the optimal procedure to corrupt images. Our work sheds new light on observations made in recent works and provides a new approach to improve diffusion models on images and other types of data.
A Closer Look at Temporal Ordering in the Segmentation of Instructional Videos
Oct 07, 2022
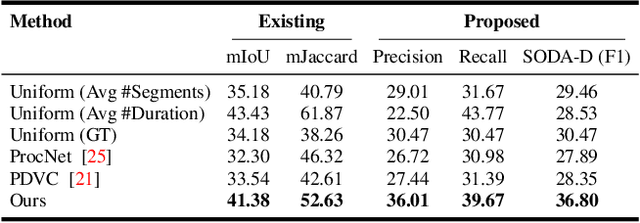
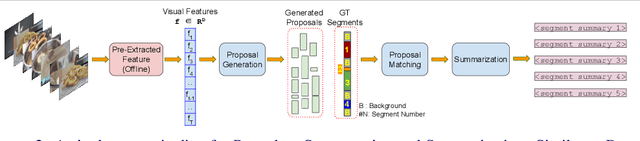
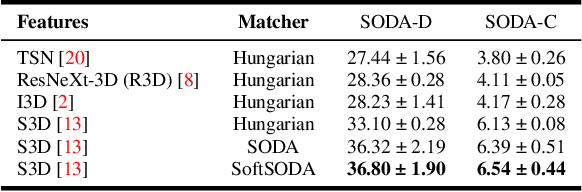
Understanding the steps required to perform a task is an important skill for AI systems. Learning these steps from instructional videos involves two subproblems: (i) identifying the temporal boundary of sequentially occurring segments and (ii) summarizing these steps in natural language. We refer to this task as Procedure Segmentation and Summarization (PSS). In this paper, we take a closer look at PSS and propose three fundamental improvements over current methods. The segmentation task is critical, as generating a correct summary requires each step of the procedure to be correctly identified. However, current segmentation metrics often overestimate the segmentation quality because they do not consider the temporal order of segments. In our first contribution, we propose a new segmentation metric that takes into account the order of segments, giving a more reliable measure of the accuracy of a given predicted segmentation. Current PSS methods are typically trained by proposing segments, matching them with the ground truth and computing a loss. However, much like segmentation metrics, existing matching algorithms do not consider the temporal order of the mapping between candidate segments and the ground truth. In our second contribution, we propose a matching algorithm that constrains the temporal order of segment mapping, and is also differentiable. Lastly, we introduce multi-modal feature training for PSS, which further improves segmentation. We evaluate our approach on two instructional video datasets (YouCook2 and Tasty) and observe an improvement over the state-of-the-art of $\sim7\%$ and $\sim2.5\%$ for procedure segmentation and summarization, respectively.