 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST: Cross-modal Alignment Similarity Test for Vision Language Models
Paper and Code
Sep 17, 2024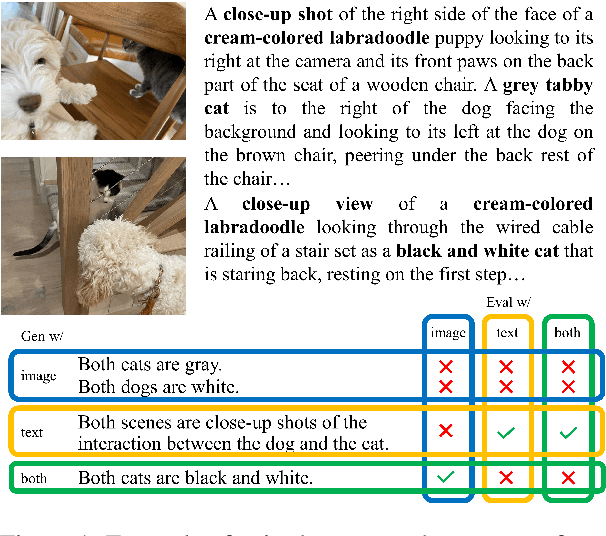
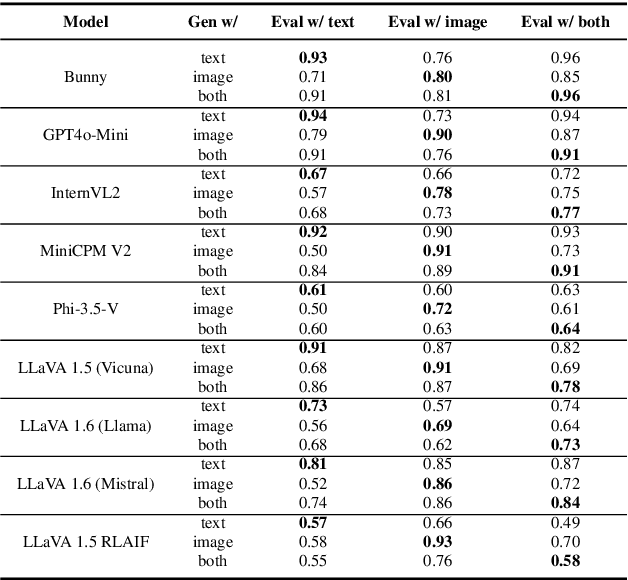
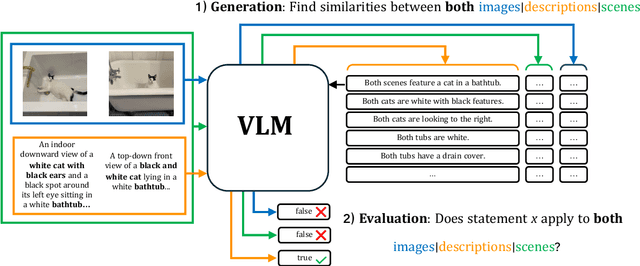

Vision Language Models (VLMs) are typically evaluated with Visual Question Answering (VQA) tasks which assess a model's understanding of scenes. Good VQA performance is taken as evidence that the model will perform well on a broader range of tasks that require both visual and language inputs. However, scene-aware VQA does not fully capture input biases or assess hallucinations caused by a misalignment between modalities. To address this, we propose a Cross-modal Alignment Similarity Test (CAST) to probe VLMs for self-consistency across modalities. This test involves asking the models to identify similarities between two scenes through text-only, image-only, or both and then assess the truthfulness of the similarities they generate. Since there is no ground-truth to compare against, this evaluation does not focus on objective accuracy but rather on whether VLMs are internally consistent in their outputs. We argue that while not all self-consistent models are capable or accurate, all capable VLMs must be self-consistent.