 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoil Fertility Prediction Using Combined USB-microscope Based Soil Image, Auxiliary Variables, and Portable X-Ray Fluorescence Spectrometry
Apr 17, 2024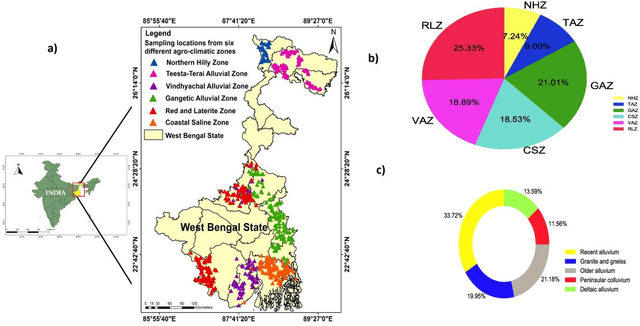
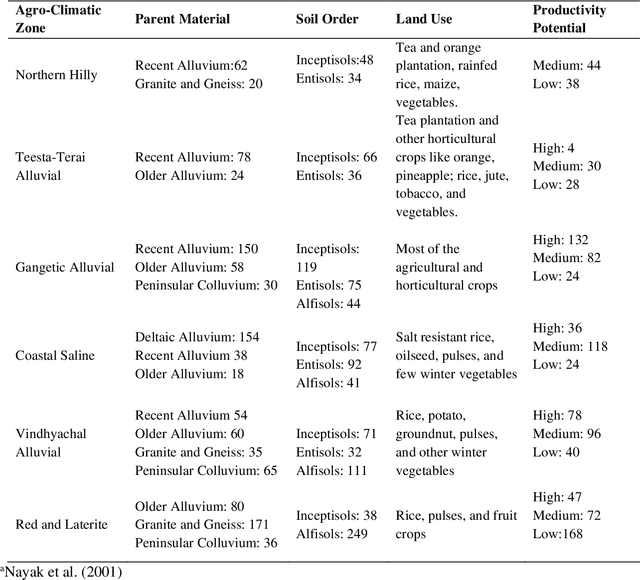


This study explored the application of portable X-ray fluorescence (PXRF) spectrometry and soil image analysis to rapidly assess soil fertility, focusing on critical parameters such as available B, organic carbon (OC), available Mn, available S, and the sulfur availability index (SAI). Analyzing 1,133 soil samples from various agro-climatic zones in Eastern India, the research combined color and texture features from microscopic soil images, PXRF data, and auxiliary soil variables (AVs) using a Random Forest model. Results indicated that integrating image features (IFs) with auxiliary variables (AVs) significantly enhanced prediction accuracy for available B (R^2 = 0.80) and OC (R^2 = 0.88). A data fusion approach, incorporating IFs, AVs, and PXRF data, further improved predictions for available Mn and SAI with R^2 values of 0.72 and 0.70, respectively. The study demonstrated how these integrated technologies have the potential to provide quick and affordable options for soil testing, opening up access to more sophisticated prediction models and a better comprehension of the fertility and health of the soil. Future research should focus on the application of deep learning models on a larger dataset of soil images, developed using soils from a broader range of agro-climatic zones under field condition.
Doodle Your 3D: From Abstract Freehand Sketches to Precise 3D Shapes
Dec 07, 2023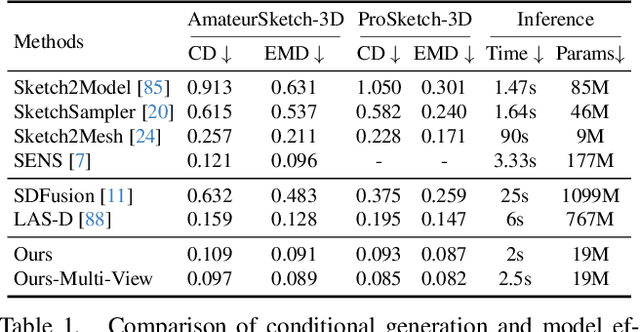
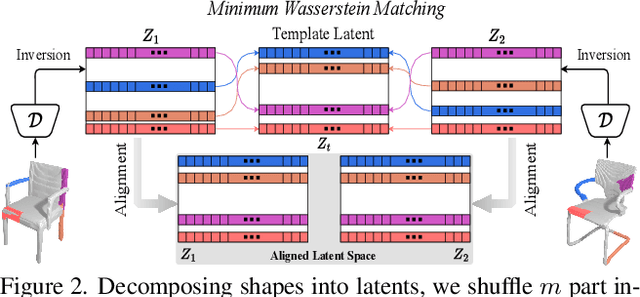
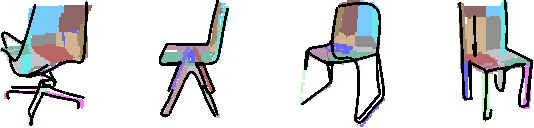
In this paper, we democratise 3D content creation, enabling precise generation of 3D shapes from abstract sketches while overcoming limitations tied to drawing skills. We introduce a novel part-level modelling and alignment framework that facilitates abstraction modelling and cross-modal correspondence. Leveraging the same part-level decoder, our approach seamlessly extends to sketch modelling by establishing correspondence between CLIPasso edgemaps and projected 3D part regions, eliminating the need for a dataset pairing human sketches and 3D shapes. Additionally, our method introduces a seamless in-position editing process as a byproduct of cross-modal part-aligned modelling. Operating in a low-dimensional implicit space, our approach significantly reduces computational demands and processing time.
Score Normalization for a Faster Diffusion Exponential Integrator Sampler
Nov 10, 2023Recently, Zhang et al. have proposed the Diffusion Exponential Integrator Sampler (DEIS) for fast generation of samples from Diffusion Models. It leverages the semi-linear nature of the probability flow ordinary differential equation (ODE) in order to greatly reduce integration error and improve generation quality at low numbers of function evaluations (NFEs). Key to this approach is the score function reparameterisation, which reduces the integration error incurred from using a fixed score function estimate over each integration step. The original authors use the default parameterisation used by models trained for noise prediction -- multiply the score by the standard deviation of the conditional forward noising distribution. We find that although the mean absolute value of this score parameterisation is close to constant for a large portion of the reverse sampling process, it changes rapidly at the end of sampling. As a simple fix, we propose to instead reparameterise the score (at inference) by dividing it by the average absolute value of previous score estimates at that time step collected from offline high NFE generations. We find that our score normalisation (DEIS-SN) consistently improves FID compared to vanilla DEIS, showing an improvement at 10 NFEs from 6.44 to 5.57 on CIFAR-10 and from 5.9 to 4.95 on LSUN-Church 64x64. Our code is available at https://github.com/mtkresearch/Diffusion-DEIS-SN
A study of the impact of generative AI-based data augmentation on software metadata classification
Oct 14, 2023This paper presents the system submitted by the team from IIT(ISM) Dhanbad in FIRE IRSE 2023 shared task 1 on the automatic usefulness prediction of code-comment pairs as well as the impact of Large Language Model(LLM) generated data on original base data towards an associated source code. We have developed a framework where we train a machine learning-based model using the neural contextual representations of the comments and their corresponding codes to predict the usefulness of code-comments pair and performance analysis with LLM-generated data with base data. In the official assessment, our system achieves a 4% increase in F1-score from baseline and the quality of generated data.
Image generation with shortest path diffusion
Jun 01, 2023The field of image generation has made significant progress thanks to the introduction of Diffusion Models, which learn to progressively reverse a given image corruption. Recently, a few studies introduced alternative ways of corrupting images in Diffusion Models, with an emphasis on blurring. However, these studies are purely empirical and it remains unclear what is the optimal procedure for corrupting an image. In this work, we hypothesize that the optimal procedure minimizes the length of the path taken when corrupting an image towards a given final state. We propose the Fisher metric for the path length, measured in the space of probability distributions. We compute the shortest path according to this metric, and we show that it corresponds to a combination of image sharpening, rather than blurring, and noise deblurring. While the corruption was chosen arbitrarily in previous work, our Shortest Path Diffusion (SPD) determines uniquely the entire spatiotemporal structure of the corruption. We show that SPD improves on strong baselines without any hyperparameter tuning, and outperforms all previous Diffusion Models based on image blurring. Furthermore, any small deviation from the shortest path leads to worse performance, suggesting that SPD provides the optimal procedure to corrupt images. Our work sheds new light on observations made in recent works and provides a new approach to improve diffusion models on images and other types of data.
ChiroDiff: Modelling chirographic data with Diffusion Models
Apr 07, 2023



Generative modelling over continuous-time geometric constructs, a.k.a such as handwriting, sketches, drawings etc., have been accomplished through autoregressive distributions. Such strictly-ordered discrete factorization however falls short of capturing key properties of chirographic data -- it fails to build holistic understanding of the temporal concept due to one-way visibility (causality). Consequently, temporal data has been modelled as discrete token sequences of fixed sampling rate instead of capturing the true underlying concept. In this paper, we introduce a powerful model-class namely "Denoising Diffusion Probabilistic Models" or DDPMs for chirographic data that specifically addresses these flaws. Our model named "ChiroDiff", being non-autoregressive, learns to capture holistic concepts and therefore remains resilient to higher temporal sampling rate up to a good extent. Moreover, we show that many important downstream utilities (e.g. conditional sampling, creative mixing) can be flexibly implemented using ChiroDiff. We further show some unique use-cases like stochastic vectorization, de-noising/healing, abstraction are also possible with this model-class. We perform quantitative and qualitative evaluation of our framework on relevant datasets and found it to be better or on par with competing approaches.
Cloud2Curve: Generation and Vectorization of Parametric Sketches
Mar 29, 2021

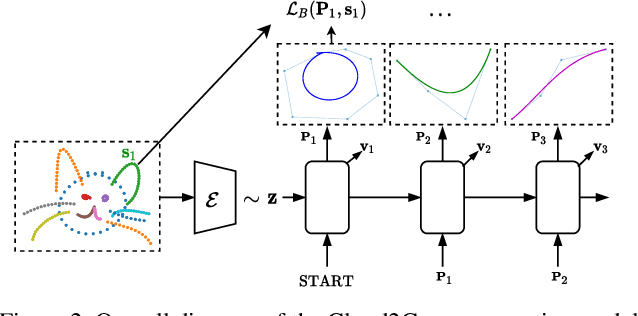

Analysis of human sketches in deep learning has advanced immensely through the use of waypoint-sequences rather than raster-graphic representations. We further aim to model sketches as a sequence of low-dimensional parametric curves. To this end, we propose an inverse graphics framework capable of approximating a raster or waypoint based stroke encoded as a point-cloud with a variable-degree B\'ezier curve. Building on this module, we present Cloud2Curve, a generative model for scalable high-resolution vector sketches that can be trained end-to-end using point-cloud data alone. As a consequence, our model is also capable of deterministic vectorization which can map novel raster or waypoint based sketches to their corresponding high-resolution scalable B\'ezier equivalent. We evaluate the generation and vectorization capabilities of our model on Quick, Draw! and K-MNIST datasets.
BézierSketch: A generative model for scalable vector sketches
Jul 14, 2020
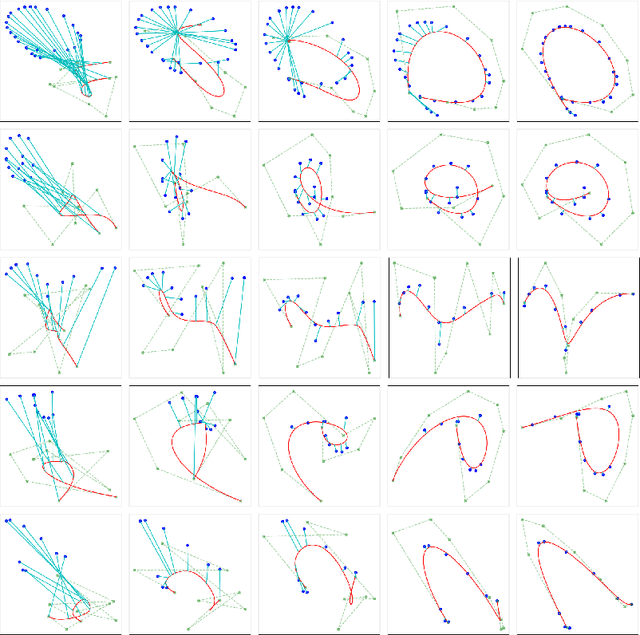

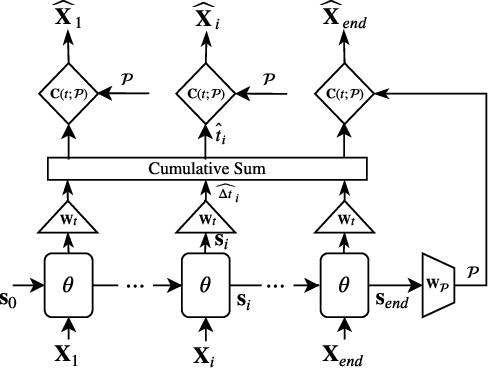
The study of neural generative models of human sketches is a fascinating contemporary modeling problem due to the links between sketch image generation and the human drawing process. The landmark SketchRNN provided breakthrough by sequentially generating sketches as a sequence of waypoints. However this leads to low-resolution image generation, and failure to model long sketches. In this paper we present B\'ezierSketch, a novel generative model for fully vector sketches that are automatically scalable and high-resolution. To this end, we first introduce a novel inverse graphics approach to stroke embedding that trains an encoder to embed each stroke to its best fit B\'ezier curve. This enables us to treat sketches as short sequences of paramaterized strokes and thus train a recurrent sketch generator with greater capacity for longer sketches, while producing scalable high-resolution results. We report qualitative and quantitative results on the Quick, Draw! benchmark.
Improving cross-lingual model transfer by chunking
Feb 27, 2020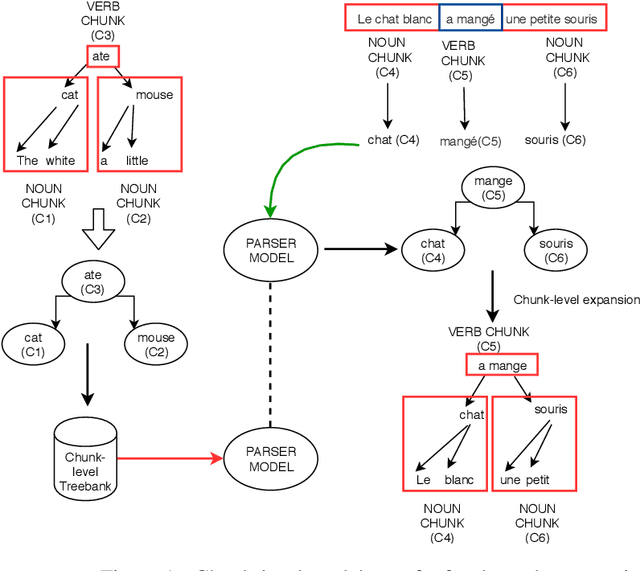



We present a shallow parser guided cross-lingual model transfer approach in order to address the syntactic differences between source and target languages more effectively. In this work, we assume the chunks or phrases in a sentence as transfer units in order to address the syntactic differences between the source and target languages arising due to the differences in ordering of words in the phrases and the ordering of phrases in a sentence separately.
HMM-based Indic Handwritten Word Recognition using Zone Segmentation
Aug 01, 2017



This paper presents a novel approach towards Indic handwritten word recognition using zone-wise information. Because of complex nature due to compound characters, modifiers, overlapping and touching, etc., character segmentation and recognition is a tedious job in Indic scripts (e.g. Devanagari, Bangla, Gurumukhi, and other similar scripts). To avoid character segmentation in such scripts, HMM-based sequence modeling has been used earlier in holistic way. This paper proposes an efficient word recognition framework by segmenting the handwritten word images horizontally into three zones (upper, middle and lower) and recognize the corresponding zones. The main aim of this zone segmentation approach is to reduce the number of distinct component classes compared to the total number of classes in Indic scripts. As a result, use of this zone segmentation approach enhances the recognition performance of the system. The components in middle zone where characters are mostly touching are recognized using HMM. After the recognition of middle zone, HMM based Viterbi forced alignment is applied to mark the left and right boundaries of the characters. Next, the residue components, if any, in upper and lower zones in their respective boundary are combined to achieve the final word level recognition. Water reservoir feature has been integrated in this framework to improve the zone segmentation and character alignment defects while segmentation. A novel sliding window-based feature, called Pyramid Histogram of Oriented Gradient (PHOG) is proposed for middle zone recognition. An exhaustive experiment is performed on two Indic scripts namely, Bangla and Devanagari for the performance evaluation. From the experiment, it has been noted that proposed zone-wise recognition improves accuracy with respect to the traditional way of Indic word recognition.
* Published in Pattern Recognition(2016)