 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging the Power of LLMs: A Fine-Tuning Approach for High-Quality Aspect-Based Summarization
Aug 05, 2024



The ever-increasing volume of digital information necessitates efficient methods for users to extract key insights from lengthy documents. Aspect-based summarization offers a targeted approach, generating summaries focused on specific aspects within a document. Despite advancements in aspect-based summarization research, there is a continuous quest for improved model performance. Given that large language models (LLMs) have demonstrated the potential to revolutionize diverse tasks within natural language processing, particularly in the problem of summarization, this paper explores the potential of fine-tuning LLMs for the aspect-based summarization task. We evaluate the impact of fine-tuning open-source foundation LLMs, including Llama2, Mistral, Gemma and Aya, on a publicly available domain-specific aspect based summary dataset. We hypothesize that this approach will enable these models to effectively identify and extract aspect-related information, leading to superior quality aspect-based summaries compared to the state-of-the-art. We establish a comprehensive evaluation framework to compare the performance of fine-tuned LLMs against competing aspect-based summarization methods and vanilla counterparts of the fine-tuned LLMs. Our work contributes to the field of aspect-based summarization by demonstrating the efficacy of fine-tuning LLMs for generating high-quality aspect-based summaries. Furthermore, it opens doors for further exploration of using LLMs for targeted information extraction tasks across various NLP domains.
Building a Domain-specific Guardrail Model in Production
Jul 24, 2024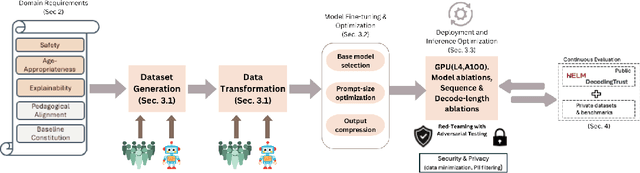
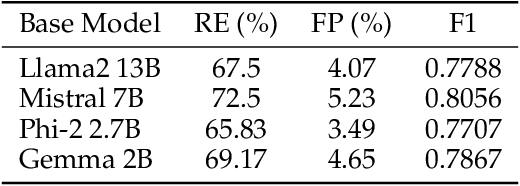

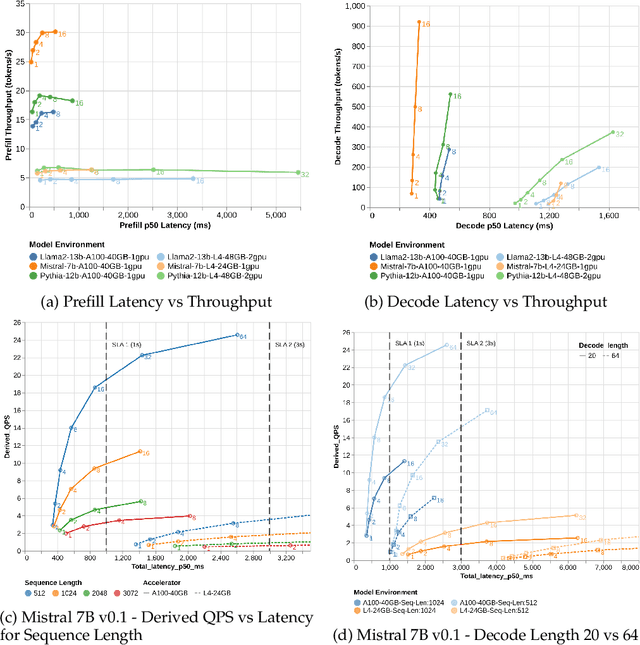
Generative AI holds the promise of enabling a range of sought-after capabilities and revolutionizing workflows in various consumer and enterprise verticals. However, putting a model in production involves much more than just generating an output. It involves ensuring the model is reliable, safe, performant and also adheres to the policy of operation in a particular domain. Guardrails as a necessity for models has evolved around the need to enforce appropriate behavior of models, especially when they are in production. In this paper, we use education as a use case, given its stringent requirements of the appropriateness of content in the domain, to demonstrate how a guardrail model can be trained and deployed in production. Specifically, we describe our experience in building a production-grade guardrail model for a K-12 educational platform. We begin by formulating the requirements for deployment to this sensitive domain. We then describe the training and benchmarking of our domain-specific guardrail model, which outperforms competing open- and closed- instruction-tuned models of similar and larger size, on proprietary education-related benchmarks and public benchmarks related to general aspects of safety. Finally, we detail the choices we made on architecture and the optimizations for deploying this service in production; these range across the stack from the hardware infrastructure to the serving layer to language model inference optimizations. We hope this paper will be instructive to other practitioners looking to create production-grade domain-specific services based on generative AI and large language models.
Agent-E: From Autonomous Web Navigation to Foundational Design Principles in Agentic Systems
Jul 17, 2024



AI Agents are changing the way work gets done, both in consumer and enterprise domains. However, the design patterns and architectures to build highly capable agents or multi-agent systems are still developing, and the understanding of the implication of various design choices and algorithms is still evolving. In this paper, we present our work on building a novel web agent, Agent-E \footnote{Our code is available at \url{https://github.com/EmergenceAI/Agent-E}}. Agent-E introduces numerous architectural improvements over prior state-of-the-art web agents such as hierarchical architecture, flexible DOM distillation and denoising method, and the concept of \textit{change observation} to guide the agent towards more accurate performance. We first present the results of an evaluation of Agent-E on WebVoyager benchmark dataset and show that Agent-E beats other SOTA text and multi-modal web agents on this benchmark in most categories by 10-30\%. We then synthesize our learnings from the development of Agent-E into general design principles for developing agentic systems. These include the use of domain-specific primitive skills, the importance of distillation and de-noising of environmental observations, the advantages of a hierarchical architecture, and the role of agentic self-improvement to enhance agent efficiency and efficacy as the agent gathers experience.
On The Persona-based Summarization of Domain-Specific Documents
Jun 06, 2024



In an ever-expanding world of domain-specific knowledge, the increasing complexity of consuming, and storing information necessitates the generation of summaries from large information repositories. However, every persona of a domain has different requirements of information and hence their summarization. For example, in the healthcare domain, a persona-based (such as Doctor, Nurse, Patient etc.) approach is imperative to deliver targeted medical information efficiently. Persona-based summarization of domain-specific information by humans is a high cognitive load task and is generally not preferred. The summaries generated by two different humans have high variability and do not scale in cost and subject matter expertise as domains and personas grow. Further, AI-generated summaries using generic Large Language Models (LLMs) may not necessarily offer satisfactory accuracy for different domains unless they have been specifically trained on domain-specific data and can also be very expensive to use in day-to-day operations. Our contribution in this paper is two-fold: 1) We present an approach to efficiently fine-tune a domain-specific small foundation LLM using a healthcare corpus and also show that we can effectively evaluate the summarization quality using AI-based critiquing. 2) We further show that AI-based critiquing has good concordance with Human-based critiquing of the summaries. Hence, such AI-based pipelines to generate domain-specific persona-based summaries can be easily scaled to other domains such as legal, enterprise documents, education etc. in a very efficient and cost-effective manner.
Long Dialog Summarization: An Analysis
Feb 26, 2024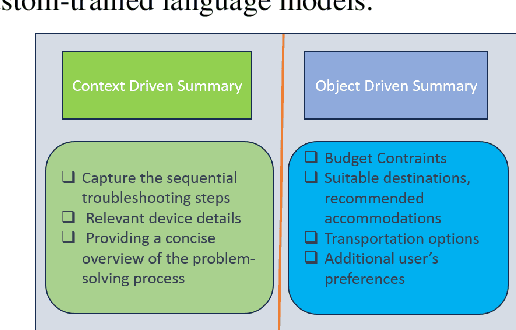

Dialog summarization has become increasingly important in managing and comprehending large-scale conversations across various domains. This task presents unique challenges in capturing the key points, context, and nuances of multi-turn long conversations for summarization. It is worth noting that the summarization techniques may vary based on specific requirements such as in a shopping-chatbot scenario, the dialog summary helps to learn user preferences, whereas in the case of a customer call center, the summary may involve the problem attributes that a user specified, and the final resolution provided. This work emphasizes the significance of creating coherent and contextually rich summaries for effective communication in various applications. We explore current state-of-the-art approaches for long dialog summarization in different domains and benchmark metrics based evaluations show that one single model does not perform well across various areas for distinct summarization tasks.
Automating question generation from educational text
Sep 26, 2023The use of question-based activities (QBAs) is wide-spread in education, traditionally forming an integral part of the learning and assessment process. In this paper, we design and evaluate an automated question generation tool for formative and summative assessment in schools. We present an expert survey of one hundred and four teachers, demonstrating the need for automated generation of QBAs, as a tool that can significantly reduce the workload of teachers and facilitate personalized learning experiences. Leveraging the recent advancements in generative AI, we then present a modular framework employing transformer based language models for automatic generation of multiple-choice questions (MCQs) from textual content. The presented solution, with distinct modules for question generation, correct answer prediction, and distractor formulation, enables us to evaluate different language models and generation techniques. Finally, we perform an extensive quantitative and qualitative evaluation, demonstrating trade-offs in the use of different techniques and models.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022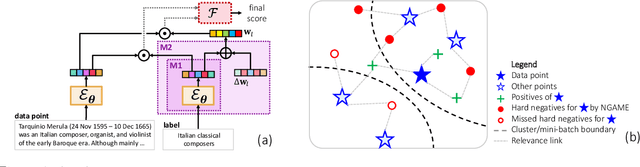
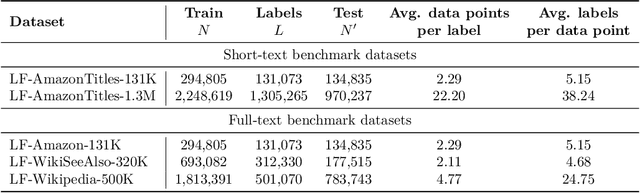
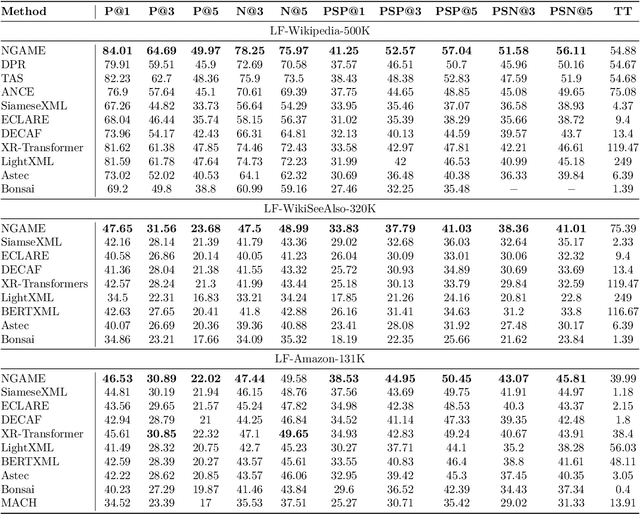
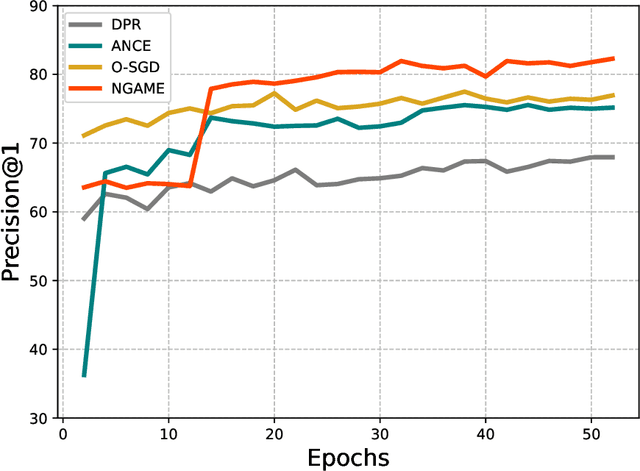
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Design and Evaluation of a Tutor Platform for Personalized Vocabulary Learning
Jul 09, 2018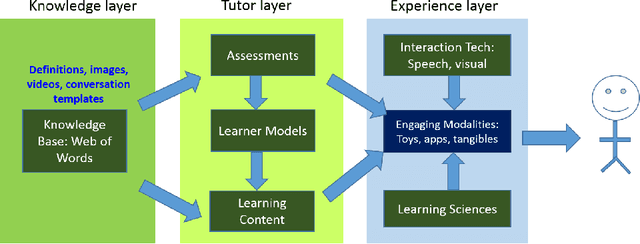
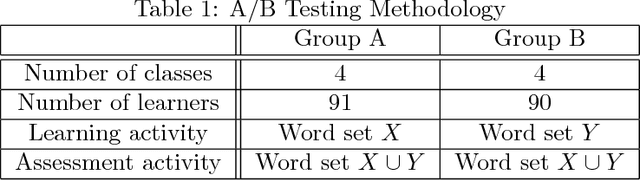
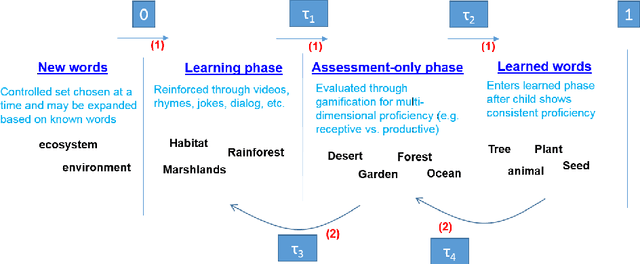

This paper presents our experiences in designing, implementing, and piloting an intelligent vocabulary learning tutor. The design builds on several intelligent tutoring design concepts, including graph-based knowledge representation, learner modeling, and adaptive learning content and assessment exposition. Specifically, we design a novel phased learner model approach to enable systematic exposure to words during vocabulary instruction. We also built an example application over the tutor platform that uses a learning activity involving videos and an assessment activity involving word to picture/image association. More importantly, the tutor adapts to the significant variation in children's knowledge at the beginning of kindergarten, and evolves the application at the speed of each individual learner. A pilot study with 180 kindergarten learners allowed the tutor to collect various kinds of activity information suitable for insights and interventions both at an individual- and class-level. The effort also demonstrates that we can do A/B testing for a variety of hypotheses at scale with such a framework.
HMM-based Indic Handwritten Word Recognition using Zone Segmentation
Aug 01, 2017



This paper presents a novel approach towards Indic handwritten word recognition using zone-wise information. Because of complex nature due to compound characters, modifiers, overlapping and touching, etc., character segmentation and recognition is a tedious job in Indic scripts (e.g. Devanagari, Bangla, Gurumukhi, and other similar scripts). To avoid character segmentation in such scripts, HMM-based sequence modeling has been used earlier in holistic way. This paper proposes an efficient word recognition framework by segmenting the handwritten word images horizontally into three zones (upper, middle and lower) and recognize the corresponding zones. The main aim of this zone segmentation approach is to reduce the number of distinct component classes compared to the total number of classes in Indic scripts. As a result, use of this zone segmentation approach enhances the recognition performance of the system. The components in middle zone where characters are mostly touching are recognized using HMM. After the recognition of middle zone, HMM based Viterbi forced alignment is applied to mark the left and right boundaries of the characters. Next, the residue components, if any, in upper and lower zones in their respective boundary are combined to achieve the final word level recognition. Water reservoir feature has been integrated in this framework to improve the zone segmentation and character alignment defects while segmentation. A novel sliding window-based feature, called Pyramid Histogram of Oriented Gradient (PHOG) is proposed for middle zone recognition. An exhaustive experiment is performed on two Indic scripts namely, Bangla and Devanagari for the performance evaluation. From the experiment, it has been noted that proposed zone-wise recognition improves accuracy with respect to the traditional way of Indic word recognition.
* Published in Pattern Recognition(2016)