 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022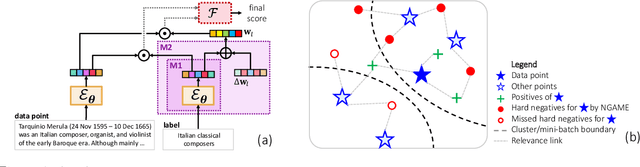
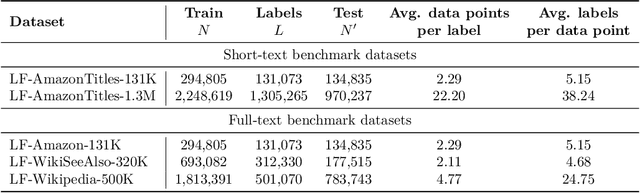
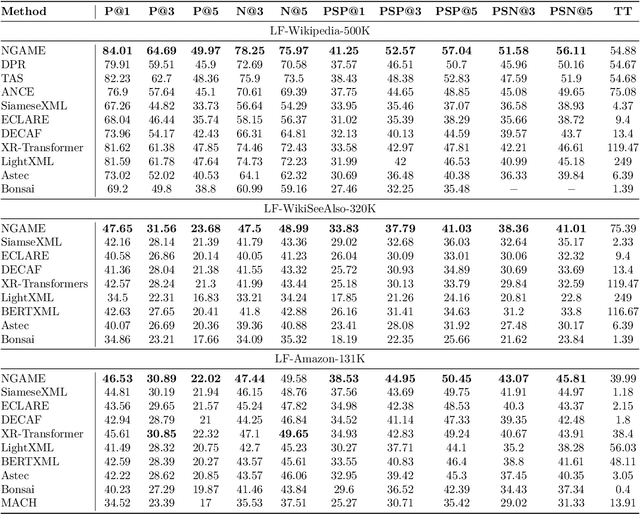
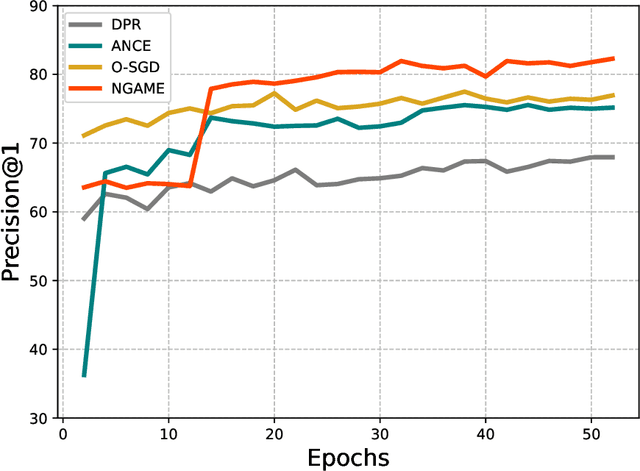
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021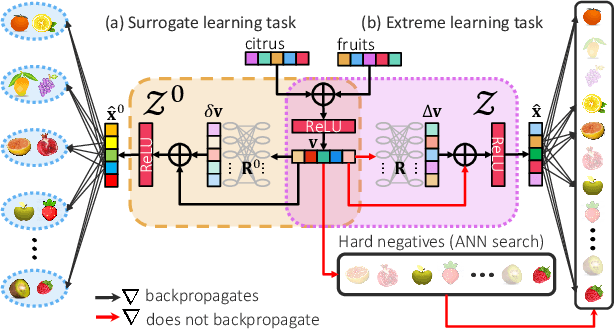
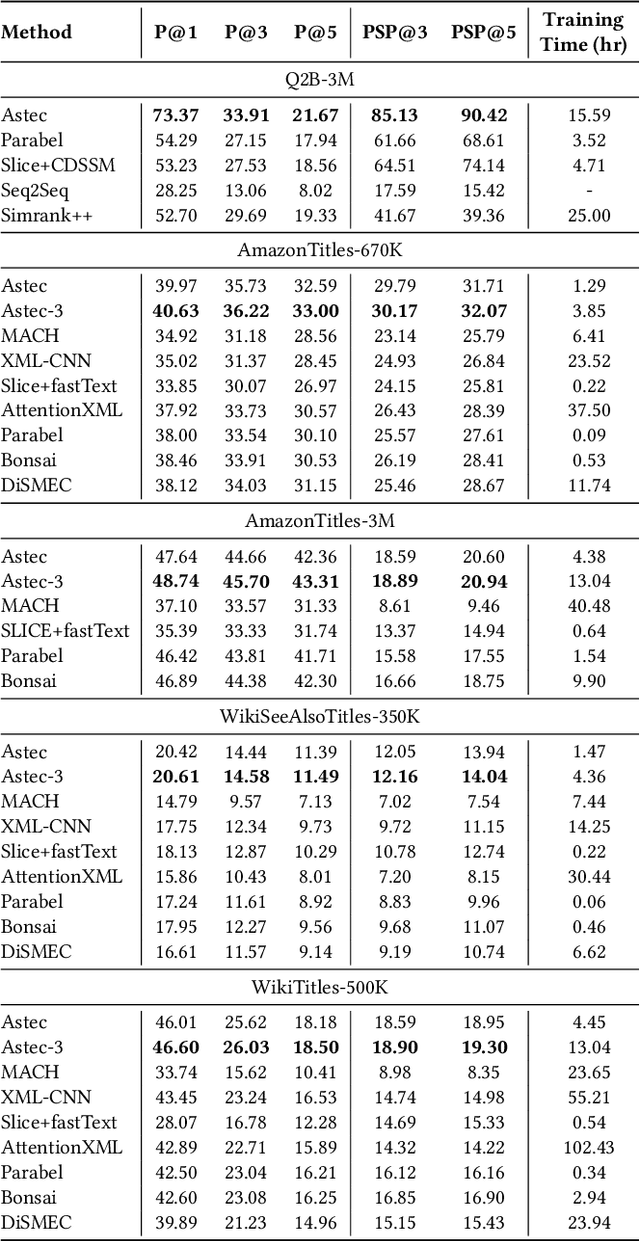

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
Hybrid Encoder: Towards Efficient and Precise Native AdsRecommendation via Hybrid Transformer Encoding Networks
Apr 22, 2021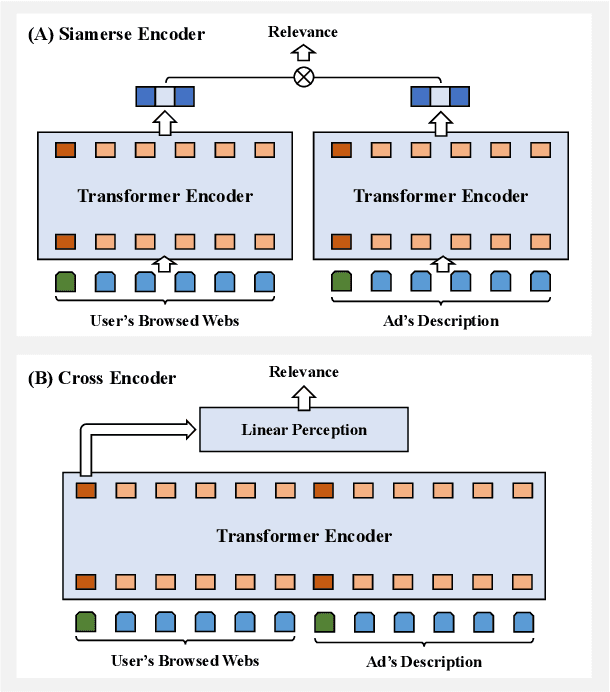
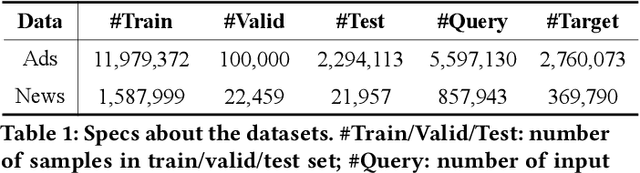
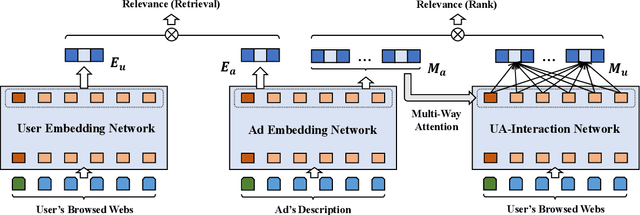
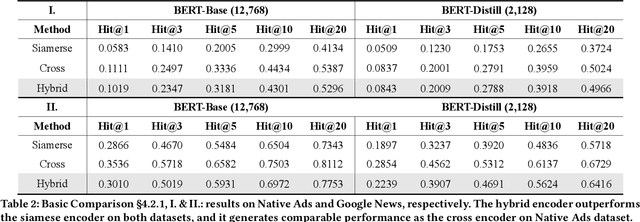
Transformer encoding networks have been proved to be a powerful tool of understanding natural languages. They are playing a critical role in native ads service, which facilitates the recommendation of appropriate ads based on user's web browsing history. For the sake of efficient recommendation, conventional methods would generate user and advertisement embeddings independently with a siamese transformer encoder, such that approximate nearest neighbour search (ANN) can be leveraged. Given that the underlying semantic about user and ad can be complicated, such independently generated embeddings are prone to information loss, which leads to inferior recommendation quality. Although another encoding strategy, the cross encoder, can be much more accurate, it will lead to huge running cost and become infeasible for realtime services, like native ads recommendation. In this work, we propose hybrid encoder, which makes efficient and precise native ads recommendation through two consecutive steps: retrieval and ranking. In the retrieval step, user and ad are encoded with a siamese component, which enables relevant candidates to be retrieved via ANN search. In the ranking step, it further represents each ad with disentangled embeddings and each user with ad-related embeddings, which contributes to the fine-grained selection of high-quality ads from the candidate set. Both steps are light-weighted, thanks to the pre-computed and cached intermedia results. To optimize the hybrid encoder's performance in this two-stage workflow, a progressive training pipeline is developed, which builds up the model's capability in the retrieval and ranking task step-by-step. The hybrid encoder's effectiveness is experimentally verified: with very little additional cost, it outperforms the siamese encoder significantly and achieves comparable recommendation quality as the cross encoder.
Multi-Interest-Aware User Modeling for Large-Scale Sequential Recommendations
Mar 04, 2021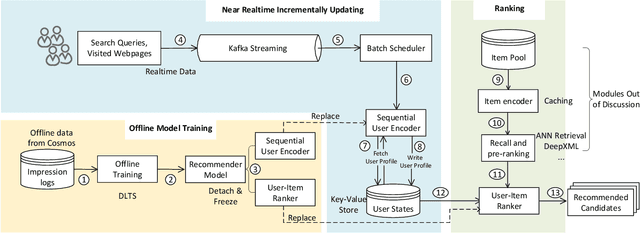
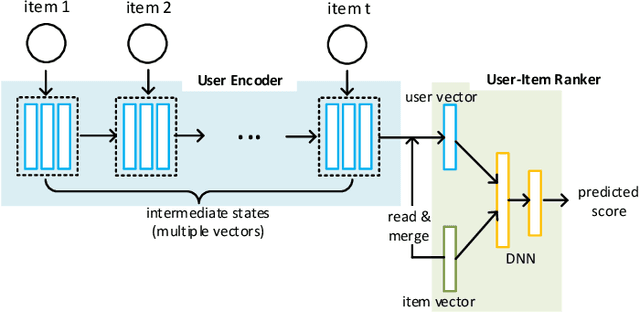
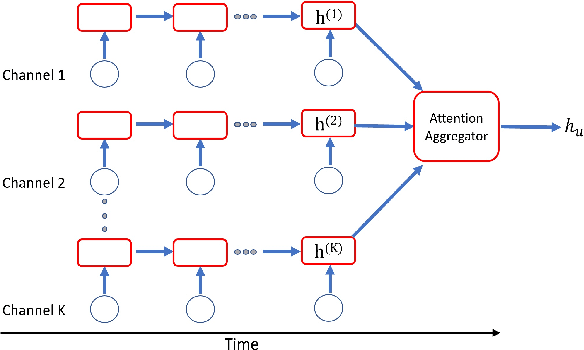
Precise user modeling is critical for online personalized recommendation services. Generally, users' interests are diverse and are not limited to a single aspect, which is particularly evident when their behaviors are observed for a longer time. For example, a user may demonstrate interests in cats/dogs, dancing and food \& delights when browsing short videos on Tik Tok; the same user may show interests in real estate and women's wear in her web browsing behaviors. Traditional models tend to encode a user's behaviors into a single embedding vector, which do not have enough capacity to effectively capture her diverse interests. This paper proposes a Sequential User Matrix (SUM) to accurately and efficiently capture users' diverse interests. SUM models user behavior with a multi-channel network, with each channel representing a different aspect of the user's interests. User states in different channels are updated by an \emph{erase-and-add} paradigm with interest- and instance-level attention. We further propose a local proximity debuff component and a highway connection component to make the model more robust and accurate. SUM can be maintained and updated incrementally, making it feasible to be deployed for large-scale online serving. We conduct extensive experiments on two datasets. Results demonstrate that SUM consistently outperforms state-of-the-art baselines.
Multi-Channel Sequential Behavior Networks for User Modeling in Online Advertising
Dec 27, 2020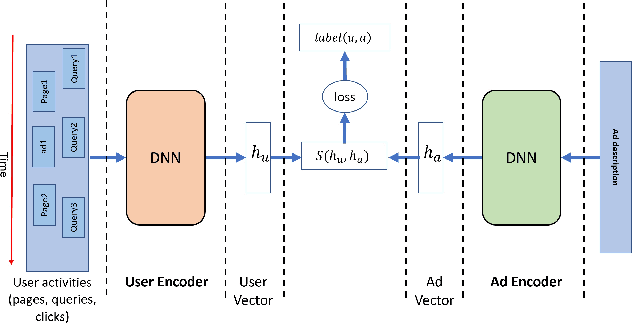


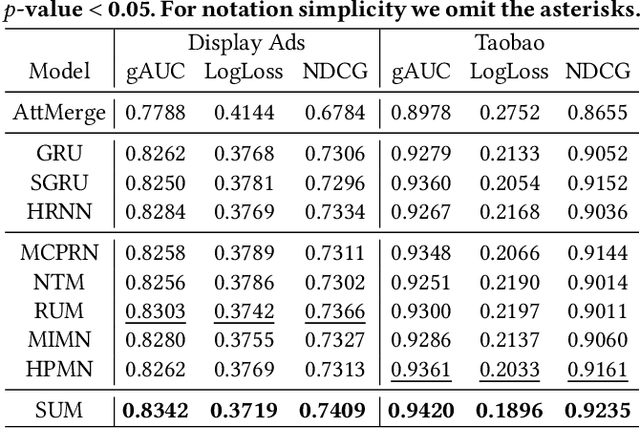
Multiple content providers rely on native advertisement for revenue by placing ads within the organic content of their pages. We refer to this setting as ``queryless'' to differentiate from search advertisement where a user submits a search query and gets back related ads. Understanding user intent is critical because relevant ads improve user experience and increase the likelihood of delivering clicks that have value to our advertisers. This paper presents Multi-Channel Sequential Behavior Network (MC-SBN), a deep learning approach for embedding users and ads in a semantic space in which relevance can be evaluated. Our proposed user encoder architecture summarizes user activities from multiple input channels--such as previous search queries, visited pages, or clicked ads--into a user vector. It uses multiple RNNs to encode sequences of event sessions from the different channels and then applies an attention mechanism to create the user representation. A key property of our approach is that user vectors can be maintained and updated incrementally, which makes it feasible to be deployed for large-scale serving. We conduct extensive experiments on real-world datasets. The results demonstrate that MC-SBN can improve the ranking of relevant ads and boost the performance of both click prediction and conversion prediction in the queryless native advertising setting.
On Learning Sparsely Used Dictionaries from Incomplete Samples
Apr 24, 2018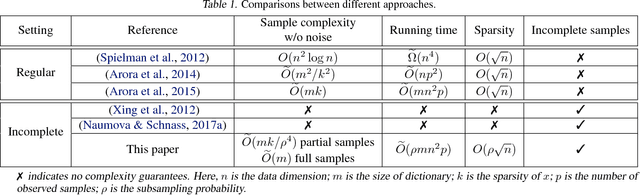
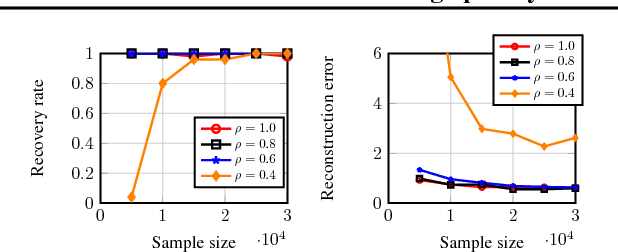
Most existing algorithms for dictionary learning assume that all entries of the (high-dimensional) input data are fully observed. However, in several practical applications (such as hyper-spectral imaging or blood glucose monitoring), only an incomplete fraction of the data entries may be available. For incomplete settings, no provably correct and polynomial-time algorithm has been reported in the dictionary learning literature. In this paper, we provide provable approaches for learning - from incomplete samples - a family of dictionaries whose atoms have sufficiently "spread-out" mass. First, we propose a descent-style iterative algorithm that linearly converges to the true dictionary when provided a sufficiently coarse initial estimate. Second, we propose an initialization algorithm that utilizes a small number of extra fully observed samples to produce such a coarse initial estimate. Finally, we theoretically analyze their performance and provide asymptotic statistical and computational guarantees.
DocTag2Vec: An Embedding Based Multi-label Learning Approach for Document Tagging
Jul 14, 2017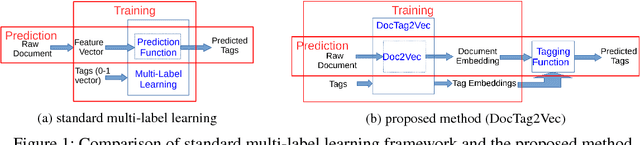
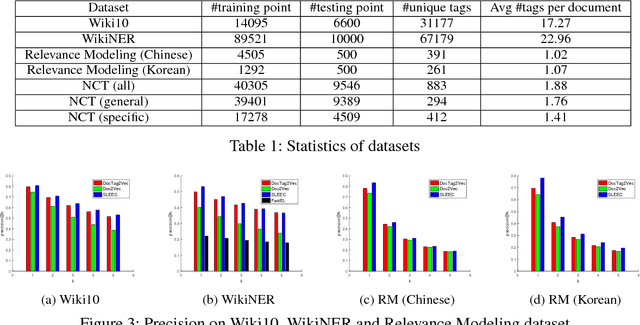
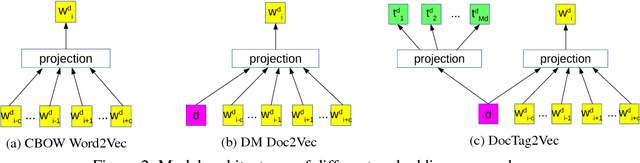
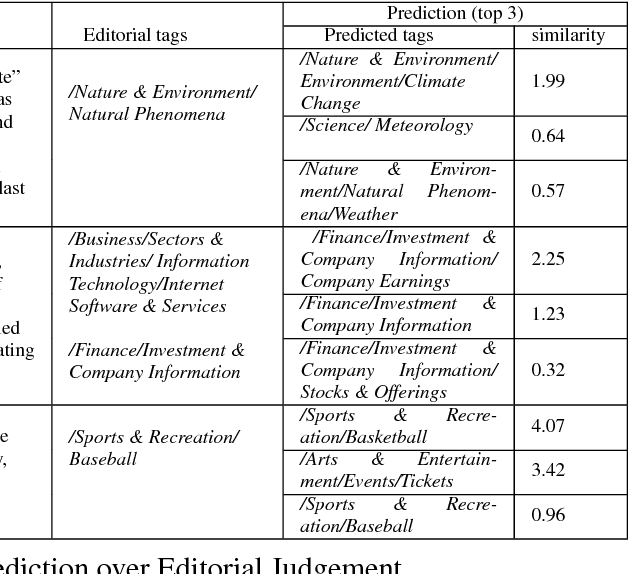
Tagging news articles or blog posts with relevant tags from a collection of predefined ones is coined as document tagging in this work. Accurate tagging of articles can benefit several downstream applications such as recommendation and search. In this work, we propose a novel yet simple approach called DocTag2Vec to accomplish this task. We substantially extend Word2Vec and Doc2Vec---two popular models for learning distributed representation of words and documents. In DocTag2Vec, we simultaneously learn the representation of words, documents, and tags in a joint vector space during training, and employ the simple $k$-nearest neighbor search to predict tags for unseen documents. In contrast to previous multi-label learning methods, DocTag2Vec directly deals with raw text instead of provided feature vector, and in addition, enjoys advantages like the learning of tag representation, and the ability of handling newly created tags. To demonstrate the effectiveness of our approach, we conduct experiments on several datasets and show promising results against state-of-the-art methods.
Online Article Ranking as a Constrained, Dynamic, Multi-Objective Optimization Problem
May 16, 2017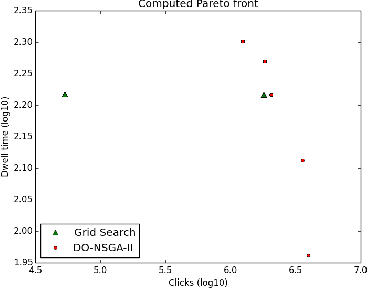

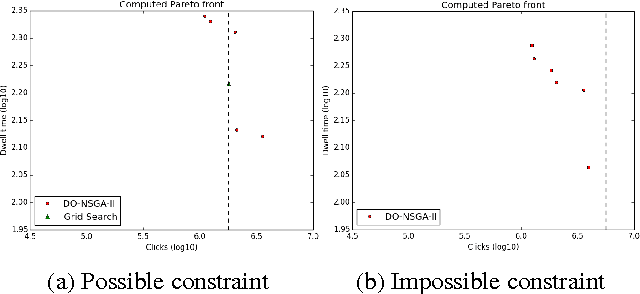
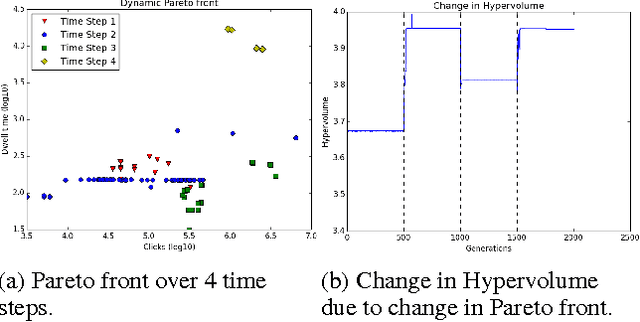
The content ranking problem in a social news website, is typically a function that maximizes a scalar metric of interest like dwell-time. However, like in most real-world applications we are interested in more than one metric---for instance simultaneously maximizing click-through rate, monetization metrics, dwell-time---and also satisfy the traffic requirements promised to different publishers. All this needs to be done on online data and under the settings where the objective function and the constraints can dynamically change; this could happen if for instance new publishers are added, some contracts are adjusted, or if some contracts are over. In this paper, we formulate this problem as a constrained, dynamic, multi-objective optimization problem. We propose a novel framework that extends a successful genetic optimization algorithm, NSGA-II, to solve this online, data-driven problem. We design the modules of NSGA-II to suit our problem. We evaluate optimization performance using Hypervolume and introduce a confidence interval metric for assessing the practicality of a solution. We demonstrate the application of this framework on a real-world Article Ranking problem. We observe that we make considerable improvements in both time and performance over a brute-force baseline technique that is currently in production.
Rank-to-engage: New Listwise Approaches to Maximize Engagement
Feb 24, 2017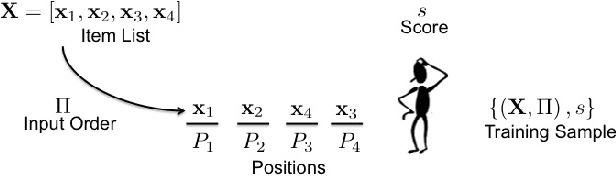



For many internet businesses, presenting a given list of items in an order that maximizes a certain metric of interest (e.g., click-through-rate, average engagement time etc.) is crucial. We approach the aforementioned task from a learning-to-rank perspective which reveals a new problem setup. In traditional learning-to-rank literature, it is implicitly assumed that during the training data generation one has access to the \emph{best or desired} order for the given list of items. In this work, we consider a problem setup where we do not observe the desired ranking. We present two novel solutions: the first solution is an extension of already existing listwise learning-to-rank technique--Listwise maximum likelihood estimation (ListMLE)--while the second one is a generic machine learning based framework that tackles the problem in its entire generality. We discuss several challenges associated with this generic framework, and propose a simple \emph{item-payoff} and \emph{positional-gain} model that addresses these challenges. We provide training algorithms, inference procedures, and demonstrate the effectiveness of the two approaches over traditional ListMLE on synthetic as well as on real-life setting of ranking news articles for increased dwell time.
RIPML: A Restricted Isometry Property based Approach to Multilabel Learning
Feb 16, 2017
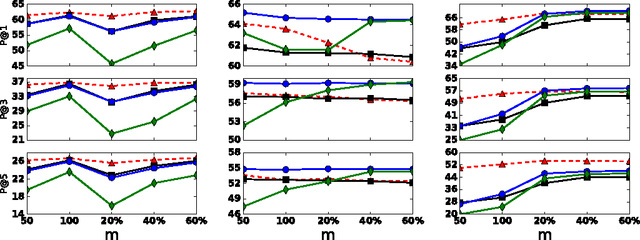
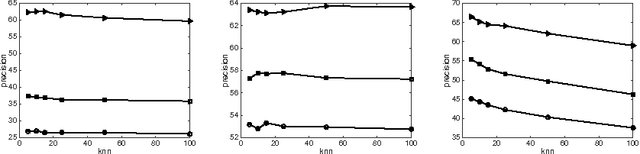

The multilabel learning problem with large number of labels, features, and data-points has generated a tremendous interest recently. A recurring theme of these problems is that only a few labels are active in any given datapoint as compared to the total number of labels. However, only a small number of existing work take direct advantage of this inherent extreme sparsity in the label space. By the virtue of Restricted Isometry Property (RIP), satisfied by many random ensembles, we propose a novel procedure for multilabel learning known as RIPML. During the training phase, in RIPML, labels are projected onto a random low-dimensional subspace followed by solving a least-square problem in this subspace. Inference is done by a k-nearest neighbor (kNN) based approach. We demonstrate the effectiveness of RIPML by conducting extensive simulations and comparing results with the state-of-the-art linear dimensionality reduction based approaches.