 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTrans: Accelerating Transformer Compression with Variational Information Bottleneck based Pruning
Jun 11, 2024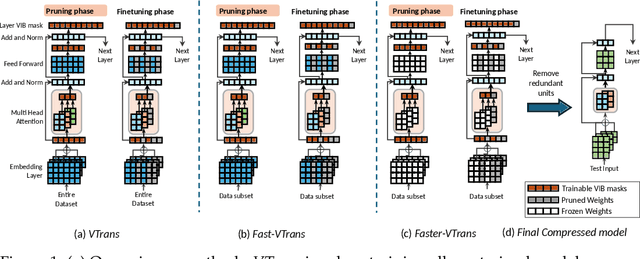
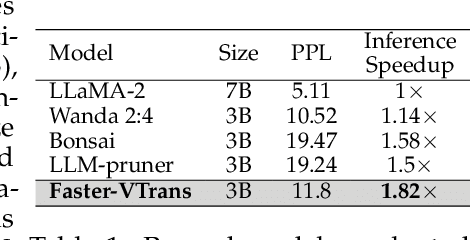
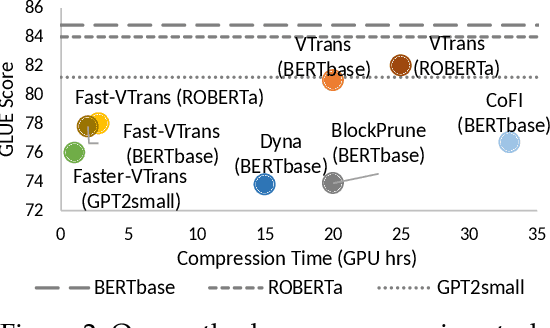
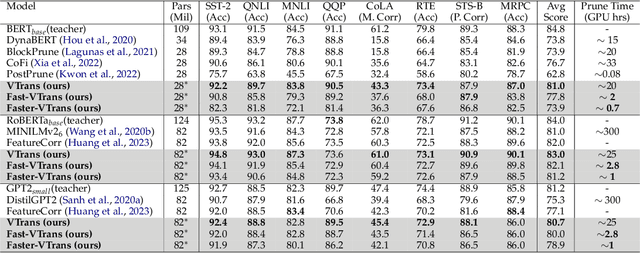
In recent years, there has been a growing emphasis on compressing large pre-trained transformer models for resource-constrained devices. However, traditional pruning methods often leave the embedding layer untouched, leading to model over-parameterization. Additionally, they require extensive compression time with large datasets to maintain performance in pruned models. To address these challenges, we propose VTrans, an iterative pruning framework guided by the Variational Information Bottleneck (VIB) principle. Our method compresses all structural components, including embeddings, attention heads, and layers using VIB-trained masks. This approach retains only essential weights in each layer, ensuring compliance with specified model size or computational constraints. Notably, our method achieves upto 70% more compression than prior state-of-the-art approaches, both task-agnostic and task-specific. We further propose faster variants of our method: Fast-VTrans utilizing only 3% of the data and Faster-VTrans, a time efficient alternative that involves exclusive finetuning of VIB masks, accelerating compression by upto 25 times with minimal performance loss compared to previous methods. Extensive experiments on BERT, ROBERTa, and GPT-2 models substantiate the efficacy of our method. Moreover, our method demonstrates scalability in compressing large models such as LLaMA-2-7B, achieving superior performance compared to previous pruning methods. Additionally, we use attention-based probing to qualitatively assess model redundancy and interpret the efficiency of our approach. Notably, our method considers heads with high attention to special and current tokens in un-pruned model as foremost candidates for pruning while retained heads are observed to attend more to task-critical keywords.
Graph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
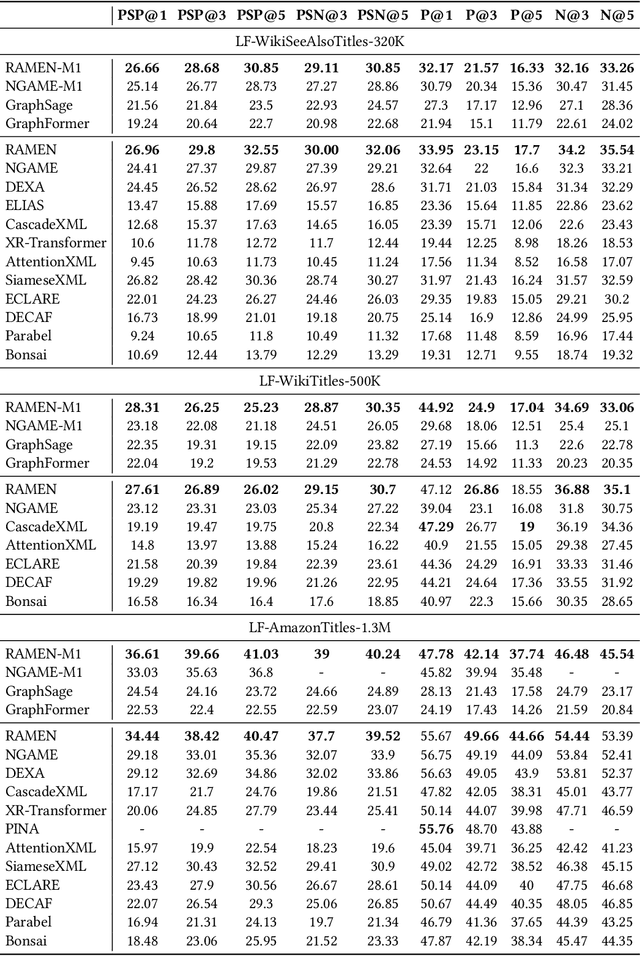
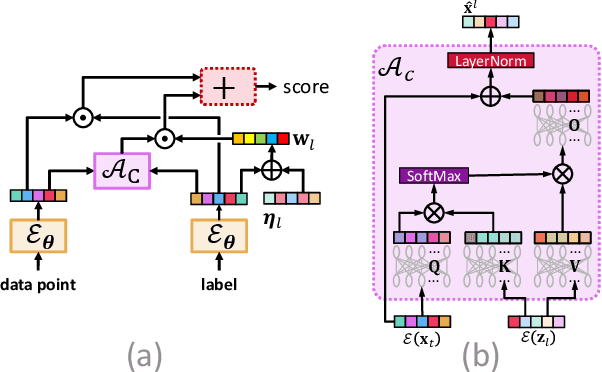
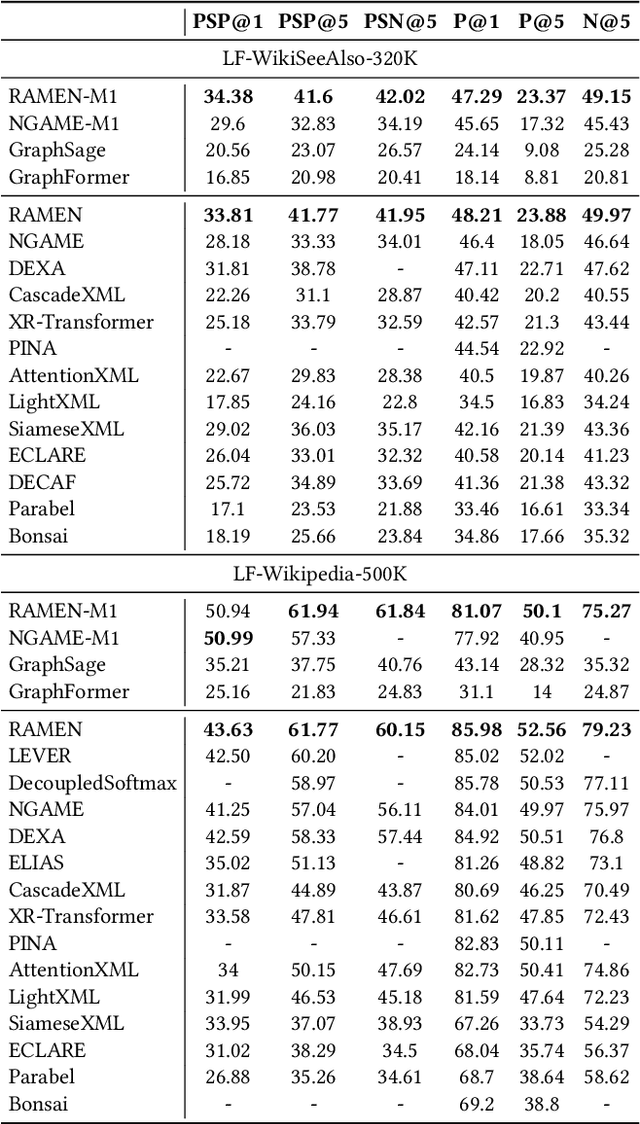
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
Multi-modal Extreme Classification
Sep 10, 2023This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
Search-time Efficient Device Constraints-Aware Neural Architecture Search
Jul 10, 2023



Edge computing aims to enable edge devices, such as IoT devices, to process data locally instead of relying on the cloud. However, deep learning techniques like computer vision and natural language processing can be computationally expensive and memory-intensive. Creating manual architectures specialized for each device is infeasible due to their varying memory and computational constraints. To address these concerns, we automate the construction of task-specific deep learning architectures optimized for device constraints through Neural Architecture Search (NAS). We present DCA-NAS, a principled method of fast neural network architecture search that incorporates edge-device constraints such as model size and floating-point operations. It incorporates weight sharing and channel bottleneck techniques to speed up the search time. Based on our experiments, we see that DCA-NAS outperforms manual architectures for similar sized models and is comparable to popular mobile architectures on various image classification datasets like CIFAR-10, CIFAR-100, and Imagenet-1k. Experiments with search spaces -- DARTS and NAS-Bench-201 show the generalization capabilities of DCA-NAS. On further evaluating our approach on Hardware-NAS-Bench, device-specific architectures with low inference latency and state-of-the-art performance were discovered.
Discourse Context Predictability Effects in Hindi Word Order
Oct 25, 2022We test the hypothesis that discourse predictability influences Hindi syntactic choice. While prior work has shown that a number of factors (e.g., information status, dependency length, and syntactic surprisal) influence Hindi word order preferences, the role of discourse predictability is underexplored in the literature. Inspired by prior work on syntactic priming, we investigate how the words and syntactic structures in a sentence influence the word order of the following sentences. Specifically, we extract sentences from the Hindi-Urdu Treebank corpus (HUTB), permute the preverbal constituents of those sentences, and build a classifier to predict which sentences actually occurred in the corpus against artificially generated distractors. The classifier uses a number of discourse-based features and cognitive features to make its predictions, including dependency length, surprisal, and information status. We find that information status and LSTM-based discourse predictability influence word order choices, especially for non-canonical object-fronted orders. We conclude by situating our results within the broader syntactic priming literature.
Dual Mechanism Priming Effects in Hindi Word Order
Oct 25, 2022Word order choices during sentence production can be primed by preceding sentences. In this work, we test the DUAL MECHANISM hypothesis that priming is driven by multiple different sources. Using a Hindi corpus of text productions, we model lexical priming with an n-gram cache model and we capture more abstract syntactic priming with an adaptive neural language model. We permute the preverbal constituents of corpus sentences, and then use a logistic regression model to predict which sentences actually occurred in the corpus against artificially generated meaning-equivalent variants. Our results indicate that lexical priming and lexically-independent syntactic priming affect complementary sets of verb classes. By showing that different priming influences are separable from one another, our results support the hypothesis that multiple different cognitive mechanisms underlie priming.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022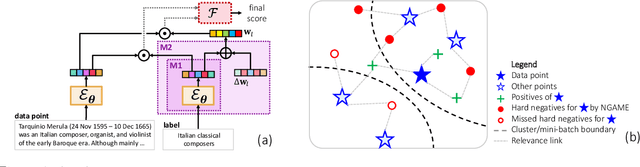
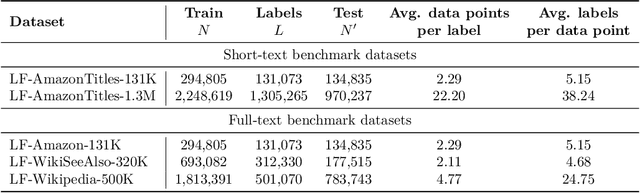
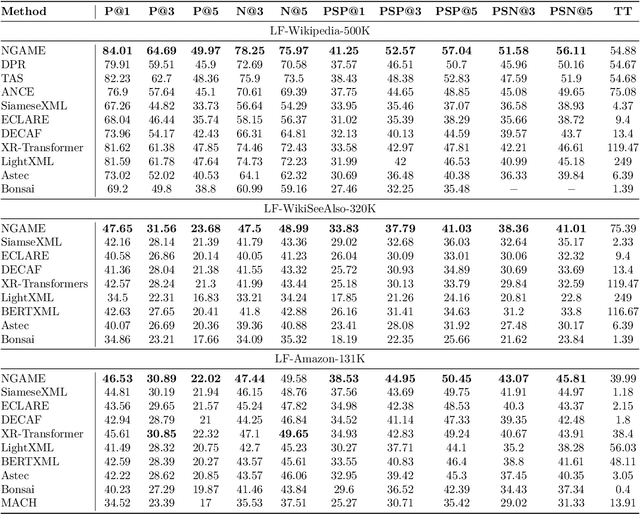
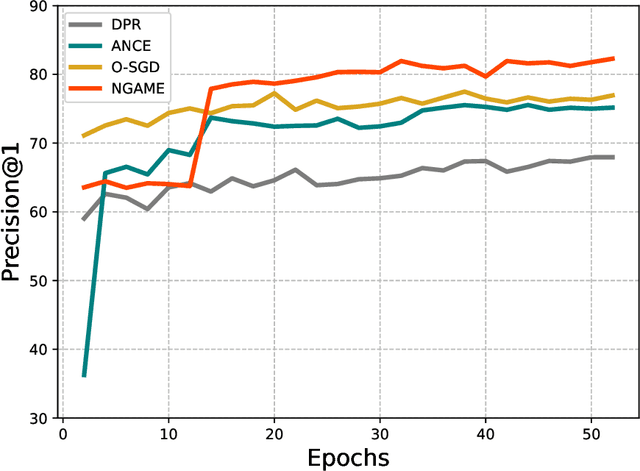
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021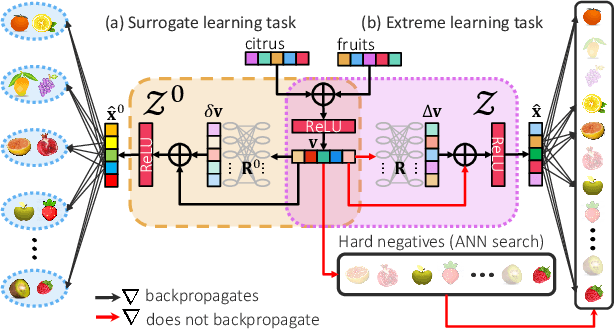
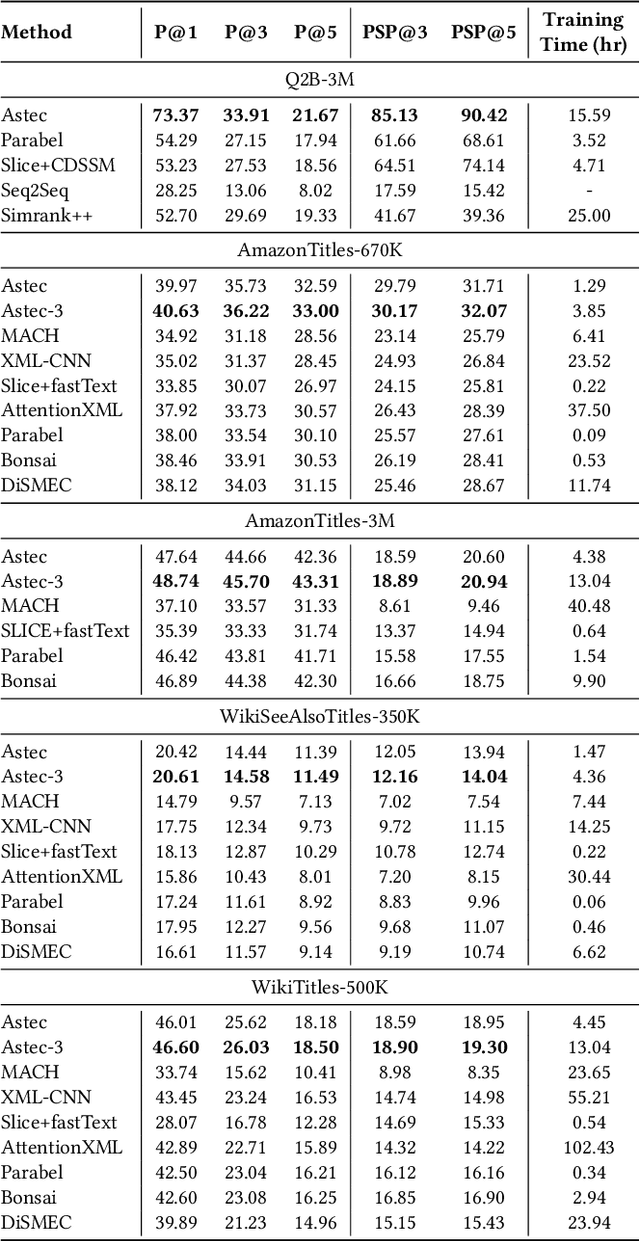

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021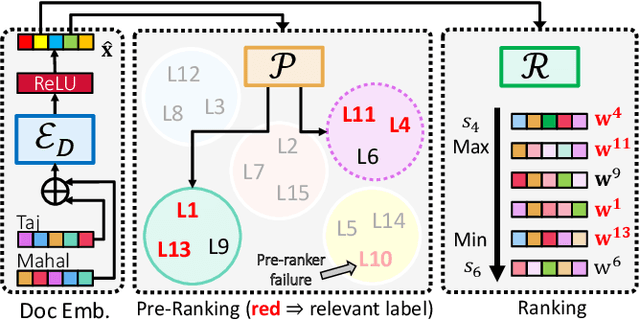
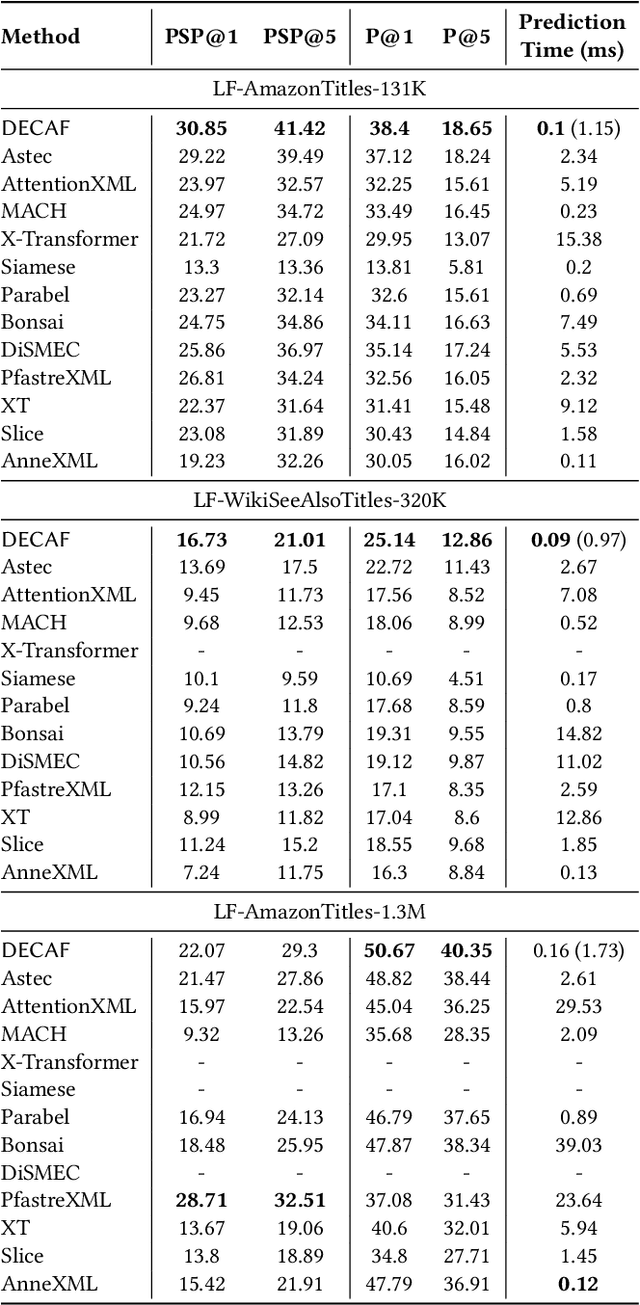
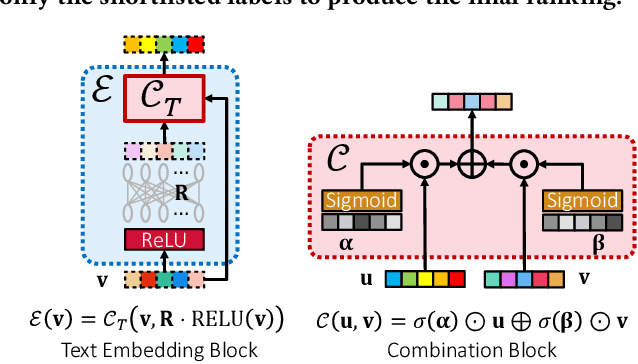
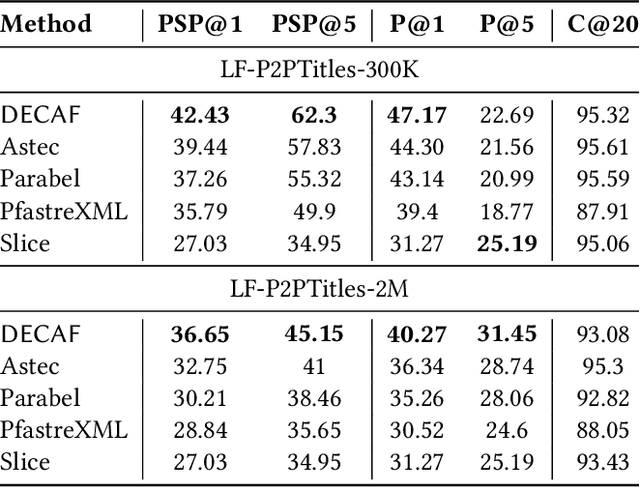
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.
ECLARE: Extreme Classification with Label Graph Correlations
Jul 31, 2021
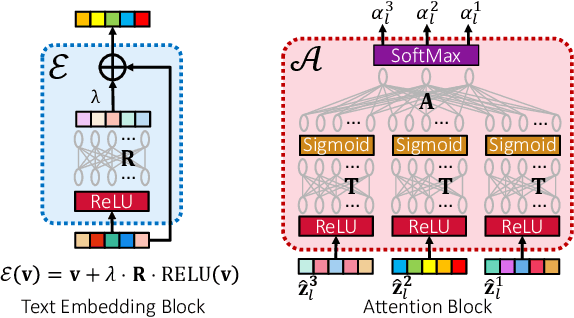
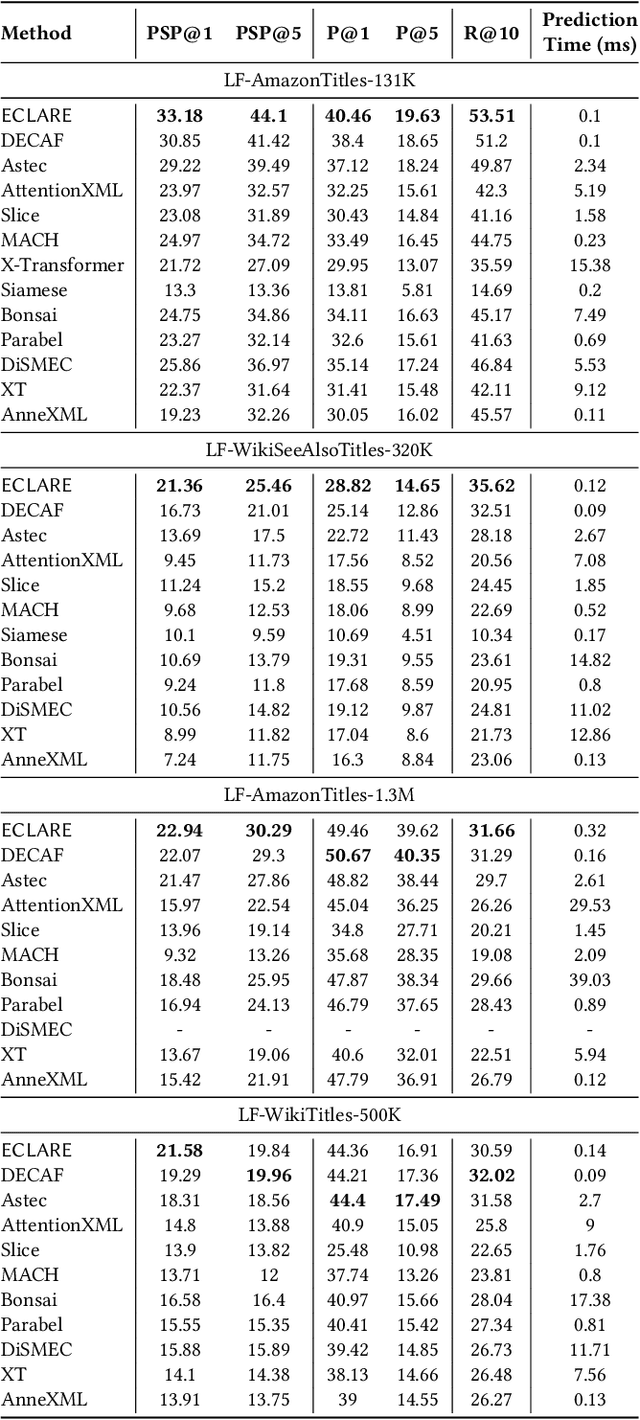
Deep extreme classification (XC) seeks to train deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. The core utility of XC comes from predicting labels that are rarely seen during training. Such rare labels hold the key to personalized recommendations that can delight and surprise a user. However, the large number of rare labels and small amount of training data per rare label offer significant statistical and computational challenges. State-of-the-art deep XC methods attempt to remedy this by incorporating textual descriptions of labels but do not adequately address the problem. This paper presents ECLARE, a scalable deep learning architecture that incorporates not only label text, but also label correlations, to offer accurate real-time predictions within a few milliseconds. Core contributions of ECLARE include a frugal architecture and scalable techniques to train deep models along with label correlation graphs at the scale of millions of labels. In particular, ECLARE offers predictions that are 2 to 14% more accurate on both publicly available benchmark datasets as well as proprietary datasets for a related products recommendation task sourced from the Bing search engine. Code for ECLARE is available at https://github.com/Extreme-classification/ECLARE.