 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoGraMS: Enhancing Movie Screen-Play Summarization using Movie Character-Aware Discourse Graph
Oct 18, 2024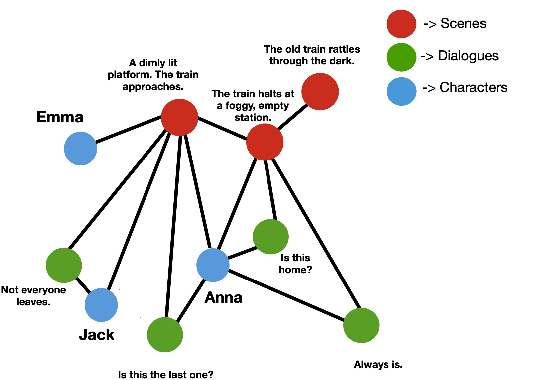
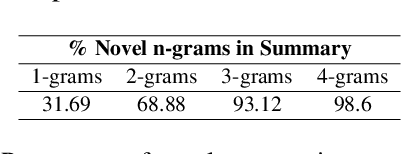
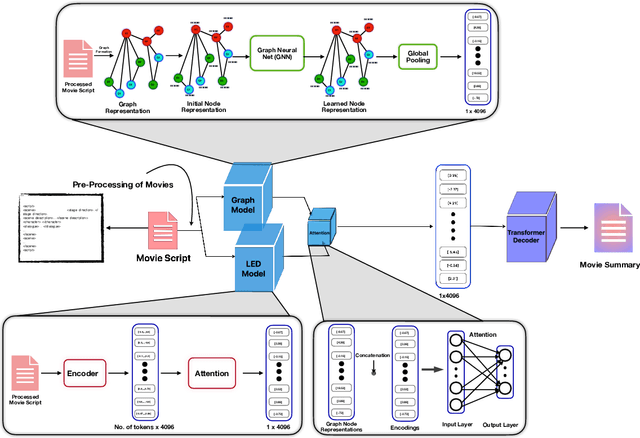
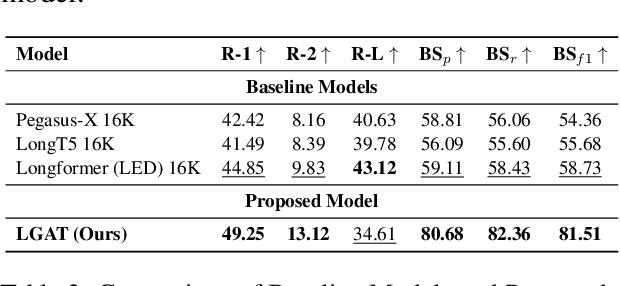
Summarizing movie screenplays presents a unique set of challenges compared to standard document summarization. Screenplays are not only lengthy, but also feature a complex interplay of characters, dialogues, and scenes, with numerous direct and subtle relationships and contextual nuances that are difficult for machine learning models to accurately capture and comprehend. Recent attempts at screenplay summarization focus on fine-tuning transformer-based pre-trained models, but these models often fall short in capturing long-term dependencies and latent relationships, and frequently encounter the "lost in the middle" issue. To address these challenges, we introduce DiscoGraMS, a novel resource that represents movie scripts as a movie character-aware discourse graph (CaD Graph). This approach is well-suited for various downstream tasks, such as summarization, question-answering, and salience detection. The model aims to preserve all salient information, offering a more comprehensive and faithful representation of the screenplay's content. We further explore a baseline method that combines the CaD Graph with the corresponding movie script through a late fusion of graph and text modalities, and we present very initial promising results.
Dual Mechanism Priming Effects in Hindi Word Order
Oct 25, 2022Word order choices during sentence production can be primed by preceding sentences. In this work, we test the DUAL MECHANISM hypothesis that priming is driven by multiple different sources. Using a Hindi corpus of text productions, we model lexical priming with an n-gram cache model and we capture more abstract syntactic priming with an adaptive neural language model. We permute the preverbal constituents of corpus sentences, and then use a logistic regression model to predict which sentences actually occurred in the corpus against artificially generated meaning-equivalent variants. Our results indicate that lexical priming and lexically-independent syntactic priming affect complementary sets of verb classes. By showing that different priming influences are separable from one another, our results support the hypothesis that multiple different cognitive mechanisms underlie priming.
Discourse Context Predictability Effects in Hindi Word Order
Oct 25, 2022We test the hypothesis that discourse predictability influences Hindi syntactic choice. While prior work has shown that a number of factors (e.g., information status, dependency length, and syntactic surprisal) influence Hindi word order preferences, the role of discourse predictability is underexplored in the literature. Inspired by prior work on syntactic priming, we investigate how the words and syntactic structures in a sentence influence the word order of the following sentences. Specifically, we extract sentences from the Hindi-Urdu Treebank corpus (HUTB), permute the preverbal constituents of those sentences, and build a classifier to predict which sentences actually occurred in the corpus against artificially generated distractors. The classifier uses a number of discourse-based features and cognitive features to make its predictions, including dependency length, surprisal, and information status. We find that information status and LSTM-based discourse predictability influence word order choices, especially for non-canonical object-fronted orders. We conclude by situating our results within the broader syntactic priming literature.