 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Dependency Locality Predict Non-canonical Word Order in Hindi?
May 13, 2024Previous work has shown that isolated non-canonical sentences with Object-before-Subject (OSV) order are initially harder to process than their canonical counterparts with Subject-before-Object (SOV) order. Although this difficulty diminishes with appropriate discourse context, the underlying cognitive factors responsible for alleviating processing challenges in OSV sentences remain a question. In this work, we test the hypothesis that dependency length minimization is a significant predictor of non-canonical (OSV) syntactic choices, especially when controlling for information status such as givenness and surprisal measures. We extract sentences from the Hindi-Urdu Treebank corpus (HUTB) that contain clearly-defined subjects and objects, systematically permute the preverbal constituents of those sentences, and deploy a classifier to distinguish between original corpus sentences and artificially generated alternatives. The classifier leverages various discourse-based and cognitive features, including dependency length, surprisal, and information status, to inform its predictions. Our results suggest that, although there exists a preference for minimizing dependency length in non-canonical corpus sentences amidst the generated variants, this factor does not significantly contribute in identifying corpus sentences above and beyond surprisal and givenness measures. Notably, discourse predictability emerges as the primary determinant of constituent-order preferences. These findings are further supported by human evaluations involving 44 native Hindi speakers. Overall, this work sheds light on the role of expectation adaptation in word-ordering decisions. We conclude by situating our results within the theories of discourse production and information locality.
Work Smarter...Not Harder: Efficient Minimization of Dependency Length in SOV Languages
Apr 29, 2024

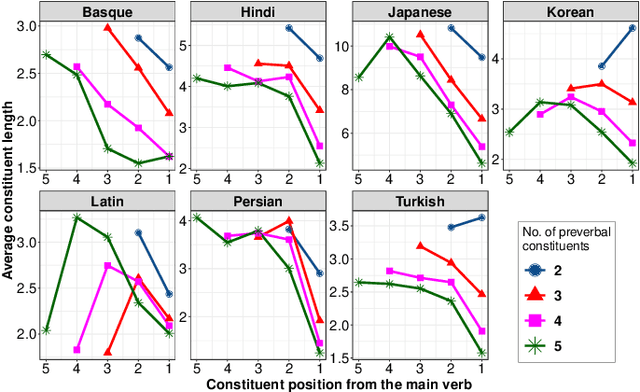

Dependency length minimization is a universally observed quantitative property of natural languages. However, the extent of dependency length minimization, and the cognitive mechanisms through which the language processor achieves this minimization remain unclear. This research offers mechanistic insights by postulating that moving a short preverbal constituent next to the main verb explains preverbal constituent ordering decisions better than global minimization of dependency length in SOV languages. This approach constitutes a least-effort strategy because it's just one operation but simultaneously reduces the length of all preverbal dependencies linked to the main verb. We corroborate this strategy using large-scale corpus evidence across all seven SOV languages that are prominently represented in the Universal Dependency Treebank. These findings align with the concept of bounded rationality, where decision-making is influenced by 'quick-yet-economical' heuristics rather than exhaustive searches for optimal solutions. Overall, this work sheds light on the role of bounded rationality in linguistic decision-making and language evolution.
A bounded rationality account of dependency length minimization in Hindi
Apr 22, 2023The principle of DEPENDENCY LENGTH MINIMIZATION, which seeks to keep syntactically related words close in a sentence, is thought to universally shape the structure of human languages for effective communication. However, the extent to which dependency length minimization is applied in human language systems is not yet fully understood. Preverbally, the placement of long-before-short constituents and postverbally, short-before-long constituents are known to minimize overall dependency length of a sentence. In this study, we test the hypothesis that placing only the shortest preverbal constituent next to the main-verb explains word order preferences in Hindi (a SOV language) as opposed to the global minimization of dependency length. We characterize this approach as a least-effort strategy because it is a cost-effective way to shorten all dependencies between the verb and its preverbal dependencies. As such, this approach is consistent with the bounded-rationality perspective according to which decision making is governed by "fast but frugal" heuristics rather than by a search for optimal solutions. Consistent with this idea, our results indicate that actual corpus sentences in the Hindi-Urdu Treebank corpus are better explained by the least effort strategy than by global minimization of dependency lengths. Additionally, for the task of distinguishing corpus sentences from counterfactual variants, we find that the dependency length and constituent length of the constituent closest to the main verb are much better predictors of whether a sentence appeared in the corpus than total dependency length. Overall, our findings suggest that cognitive resource constraints play a crucial role in shaping natural languages.
Discourse Context Predictability Effects in Hindi Word Order
Oct 25, 2022We test the hypothesis that discourse predictability influences Hindi syntactic choice. While prior work has shown that a number of factors (e.g., information status, dependency length, and syntactic surprisal) influence Hindi word order preferences, the role of discourse predictability is underexplored in the literature. Inspired by prior work on syntactic priming, we investigate how the words and syntactic structures in a sentence influence the word order of the following sentences. Specifically, we extract sentences from the Hindi-Urdu Treebank corpus (HUTB), permute the preverbal constituents of those sentences, and build a classifier to predict which sentences actually occurred in the corpus against artificially generated distractors. The classifier uses a number of discourse-based features and cognitive features to make its predictions, including dependency length, surprisal, and information status. We find that information status and LSTM-based discourse predictability influence word order choices, especially for non-canonical object-fronted orders. We conclude by situating our results within the broader syntactic priming literature.
Dual Mechanism Priming Effects in Hindi Word Order
Oct 25, 2022Word order choices during sentence production can be primed by preceding sentences. In this work, we test the DUAL MECHANISM hypothesis that priming is driven by multiple different sources. Using a Hindi corpus of text productions, we model lexical priming with an n-gram cache model and we capture more abstract syntactic priming with an adaptive neural language model. We permute the preverbal constituents of corpus sentences, and then use a logistic regression model to predict which sentences actually occurred in the corpus against artificially generated meaning-equivalent variants. Our results indicate that lexical priming and lexically-independent syntactic priming affect complementary sets of verb classes. By showing that different priming influences are separable from one another, our results support the hypothesis that multiple different cognitive mechanisms underlie priming.