 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTrans: Accelerating Transformer Compression with Variational Information Bottleneck based Pruning
Paper and Code
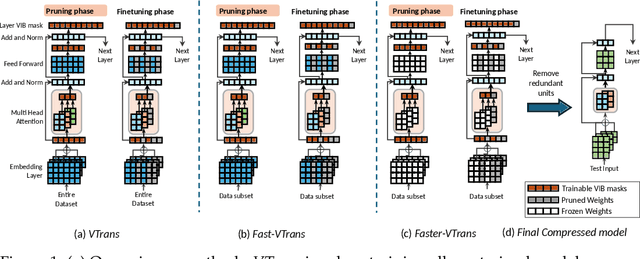
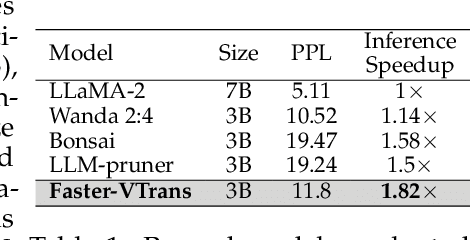
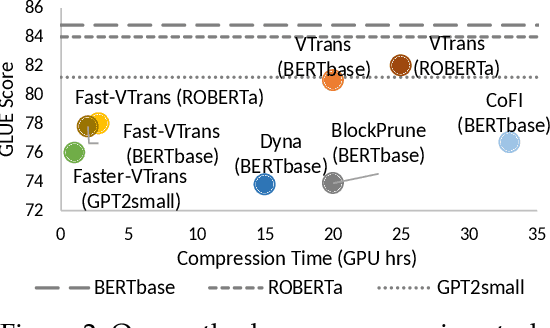
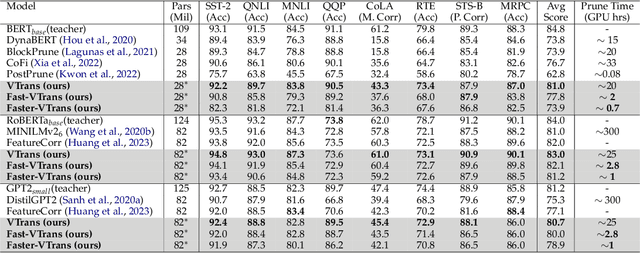
In recent years, there has been a growing emphasis on compressing large pre-trained transformer models for resource-constrained devices. However, traditional pruning methods often leave the embedding layer untouched, leading to model over-parameterization. Additionally, they require extensive compression time with large datasets to maintain performance in pruned models. To address these challenges, we propose VTrans, an iterative pruning framework guided by the Variational Information Bottleneck (VIB) principle. Our method compresses all structural components, including embeddings, attention heads, and layers using VIB-trained masks. This approach retains only essential weights in each layer, ensuring compliance with specified model size or computational constraints. Notably, our method achieves upto 70% more compression than prior state-of-the-art approaches, both task-agnostic and task-specific. We further propose faster variants of our method: Fast-VTrans utilizing only 3% of the data and Faster-VTrans, a time efficient alternative that involves exclusive finetuning of VIB masks, accelerating compression by upto 25 times with minimal performance loss compared to previous methods. Extensive experiments on BERT, ROBERTa, and GPT-2 models substantiate the efficacy of our method. Moreover, our method demonstrates scalability in compressing large models such as LLaMA-2-7B, achieving superior performance compared to previous pruning methods. Additionally, we use attention-based probing to qualitatively assess model redundancy and interpret the efficiency of our approach. Notably, our method considers heads with high attention to special and current tokens in un-pruned model as foremost candidates for pruning while retained heads are observed to attend more to task-critical keywords.