 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Regularized Encoder Training for Extreme Classification
Feb 28, 2024
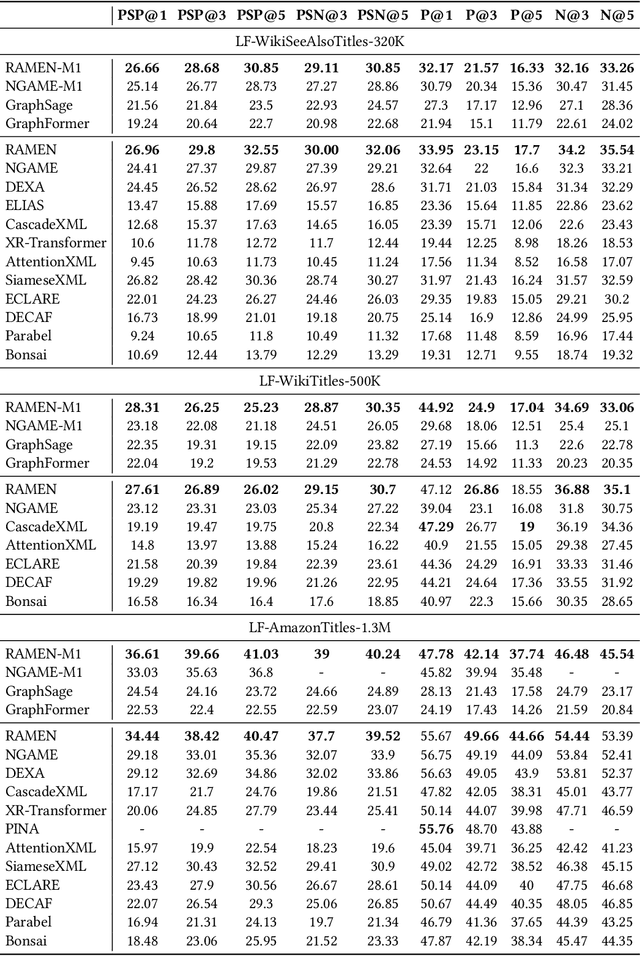
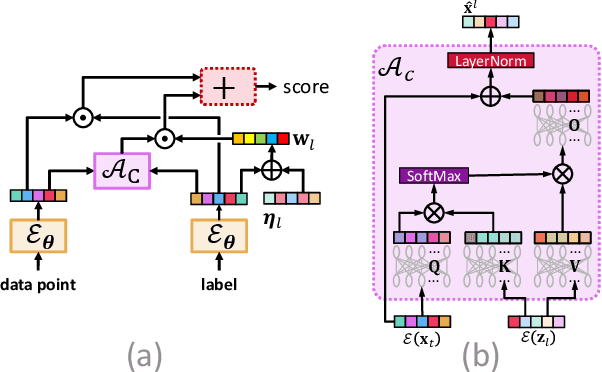
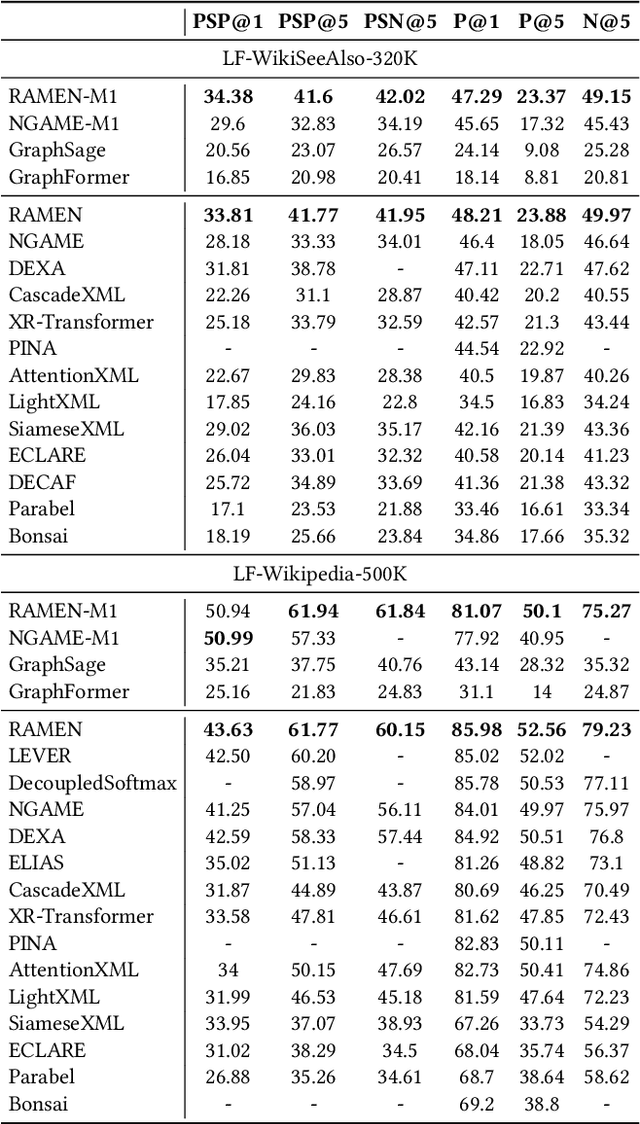
Deep extreme classification (XC) aims to train an encoder architecture and an accompanying classifier architecture to tag a data point with the most relevant subset of labels from a very large universe of labels. XC applications in ranking, recommendation and tagging routinely encounter tail labels for which the amount of training data is exceedingly small. Graph convolutional networks (GCN) present a convenient but computationally expensive way to leverage task metadata and enhance model accuracies in these settings. This paper formally establishes that in several use cases, the steep computational cost of GCNs is entirely avoidable by replacing GCNs with non-GCN architectures. The paper notices that in these settings, it is much more effective to use graph data to regularize encoder training than to implement a GCN. Based on these insights, an alternative paradigm RAMEN is presented to utilize graph metadata in XC settings that offers significant performance boosts with zero increase in inference computational costs. RAMEN scales to datasets with up to 1M labels and offers prediction accuracy up to 15% higher on benchmark datasets than state of the art methods, including those that use graph metadata to train GCNs. RAMEN also offers 10% higher accuracy over the best baseline on a proprietary recommendation dataset sourced from click logs of a popular search engine. Code for RAMEN will be released publicly.
Multi-modal Extreme Classification
Sep 10, 2023This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
Corruption-tolerant Algorithms for Generalized Linear Models
Dec 11, 2022
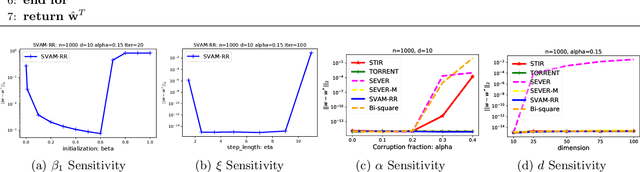
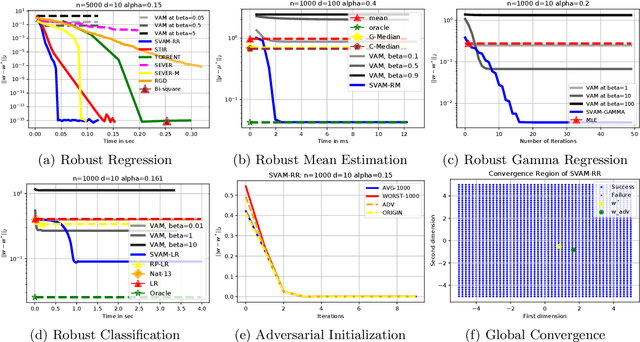

This paper presents SVAM (Sequential Variance-Altered MLE), a unified framework for learning generalized linear models under adversarial label corruption in training data. SVAM extends to tasks such as least squares regression, logistic regression, and gamma regression, whereas many existing works on learning with label corruptions focus only on least squares regression. SVAM is based on a novel variance reduction technique that may be of independent interest and works by iteratively solving weighted MLEs over variance-altered versions of the GLM objective. SVAM offers provable model recovery guarantees superior to the state-of-the-art for robust regression even when a constant fraction of training labels are adversarially corrupted. SVAM also empirically outperforms several existing problem-specific techniques for robust regression and classification. Code for SVAM is available at https://github.com/purushottamkar/svam/
DELFI: Deep Mixture Models for Long-term Air Quality Forecasting in the Delhi National Capital Region
Oct 28, 2022

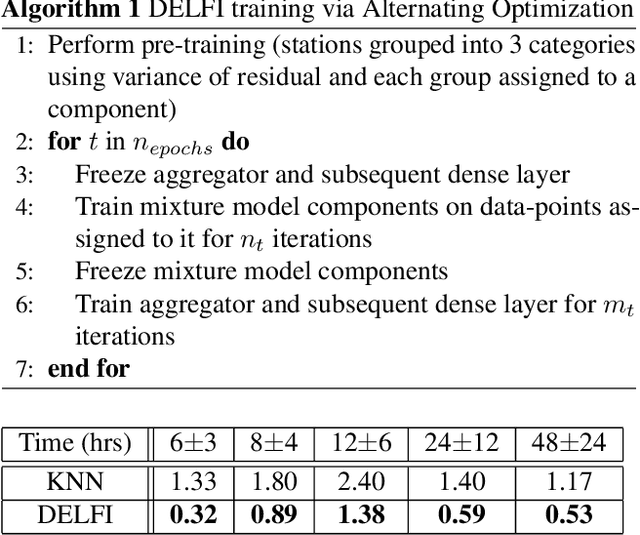

The identification and control of human factors in climate change is a rapidly growing concern and robust, real-time air-quality monitoring and forecasting plays a critical role in allowing effective policy formulation and implementation. This paper presents DELFI, a novel deep learning-based mixture model to make effective long-term predictions of Particulate Matter (PM) 2.5 concentrations. A key novelty in DELFI is its multi-scale approach to the forecasting problem. The observation that point predictions are more suitable in the short-term and probabilistic predictions in the long-term allows accurate predictions to be made as much as 24 hours in advance. DELFI incorporates meteorological data as well as pollutant-based features to ensure a robust model that is divided into two parts: (i) a stack of three Long Short-Term Memory (LSTM) networks that perform differential modelling of the same window of past data, and (ii) a fully-connected layer enabling attention to each of the components. Experimental evaluation based on deployment of 13 stations in the Delhi National Capital Region (Delhi-NCR) in India establishes that DELFI offers far superior predictions especially in the long-term as compared to even non-parametric baselines. The Delhi-NCR recorded the 3rd highest PM levels amongst 39 mega-cities across the world during 2011-2015 and DELFI's performance establishes it as a potential tool for effective long-term forecasting of PM levels to enable public health management and environment protection.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022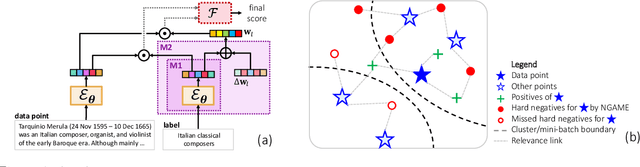
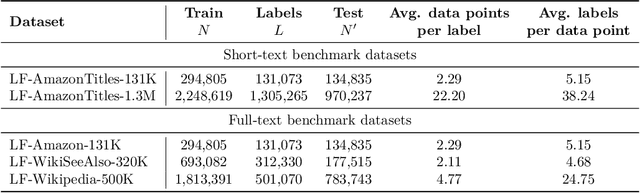
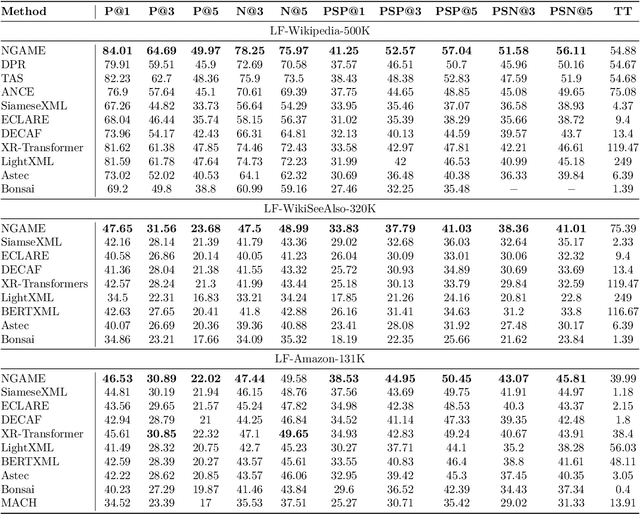
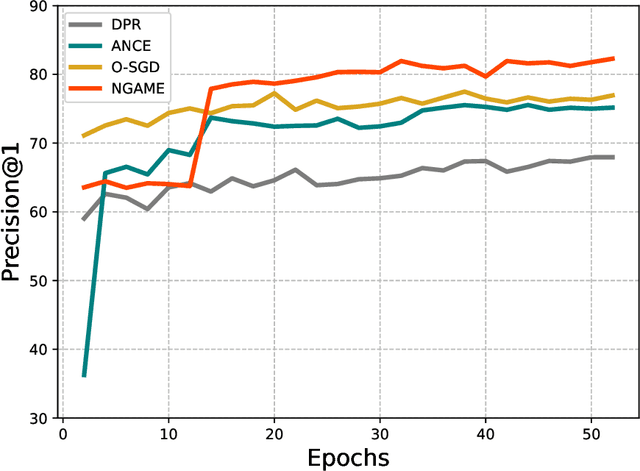
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
AGGLIO: Global Optimization for Locally Convex Functions
Nov 06, 2021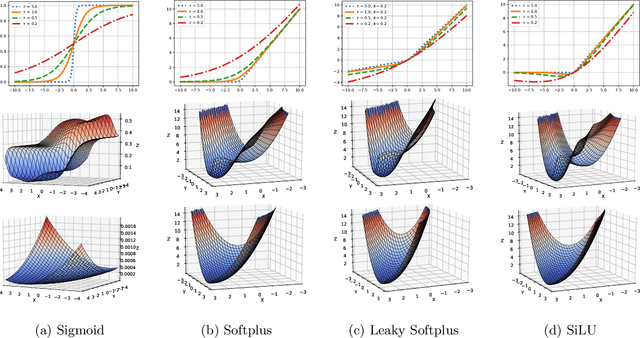

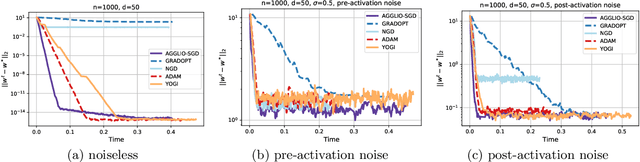
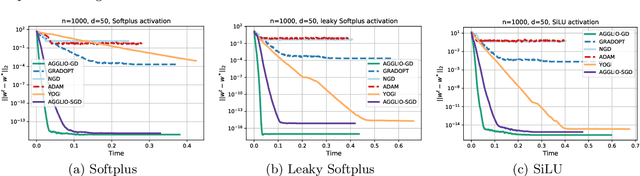
This paper presents AGGLIO (Accelerated Graduated Generalized LInear-model Optimization), a stage-wise, graduated optimization technique that offers global convergence guarantees for non-convex optimization problems whose objectives offer only local convexity and may fail to be even quasi-convex at a global scale. In particular, this includes learning problems that utilize popular activation functions such as sigmoid, softplus and SiLU that yield non-convex training objectives. AGGLIO can be readily implemented using point as well as mini-batch SGD updates and offers provable convergence to the global optimum in general conditions. In experiments, AGGLIO outperformed several recently proposed optimization techniques for non-convex and locally convex objectives in terms of convergence rate as well as convergent accuracy. AGGLIO relies on a graduation technique for generalized linear models, as well as a novel proof strategy, both of which may be of independent interest.
IGLU: Efficient GCN Training via Lazy Updates
Sep 28, 2021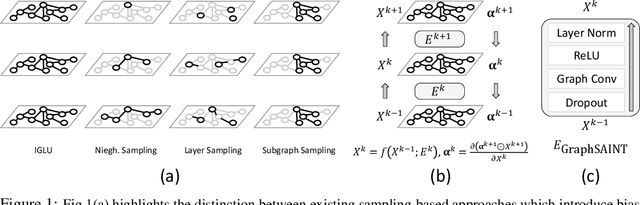
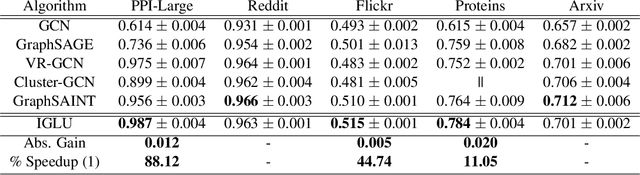
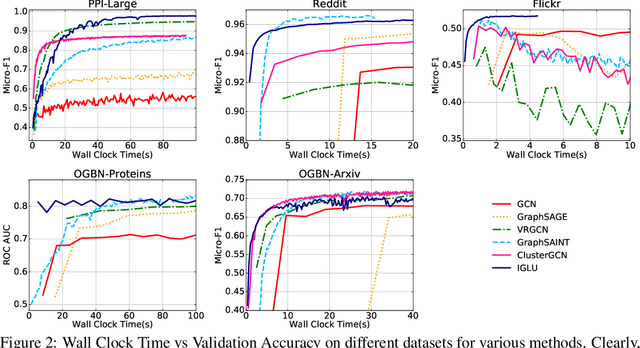

Graph Convolution Networks (GCN) are used in numerous settings involving a large underlying graph as well as several layers. Standard SGD-based training scales poorly here since each descent step ends up updating node embeddings for a large portion of the graph. Recent methods attempt to remedy this by sub-sampling the graph which does reduce the compute load, but at the cost of biased gradients which may offer suboptimal performance. In this work we introduce a new method IGLU that caches forward-pass embeddings for all nodes at various GCN layers. This enables IGLU to perform lazy updates that do not require updating a large number of node embeddings during descent which offers much faster convergence but does not significantly bias the gradients. Under standard assumptions such as objective smoothness, IGLU provably converges to a first-order saddle point. We validate IGLU extensively on a variety of benchmarks, where it offers up to 1.2% better accuracy despite requiring up to 88% less wall-clock time.
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021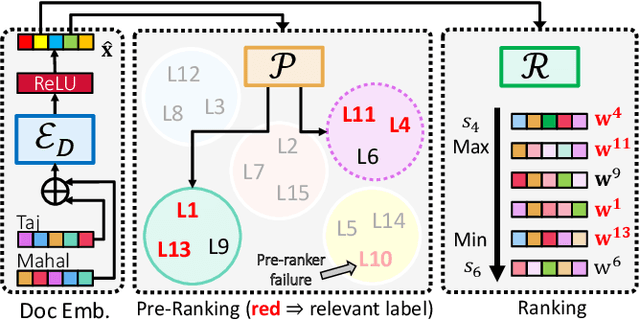
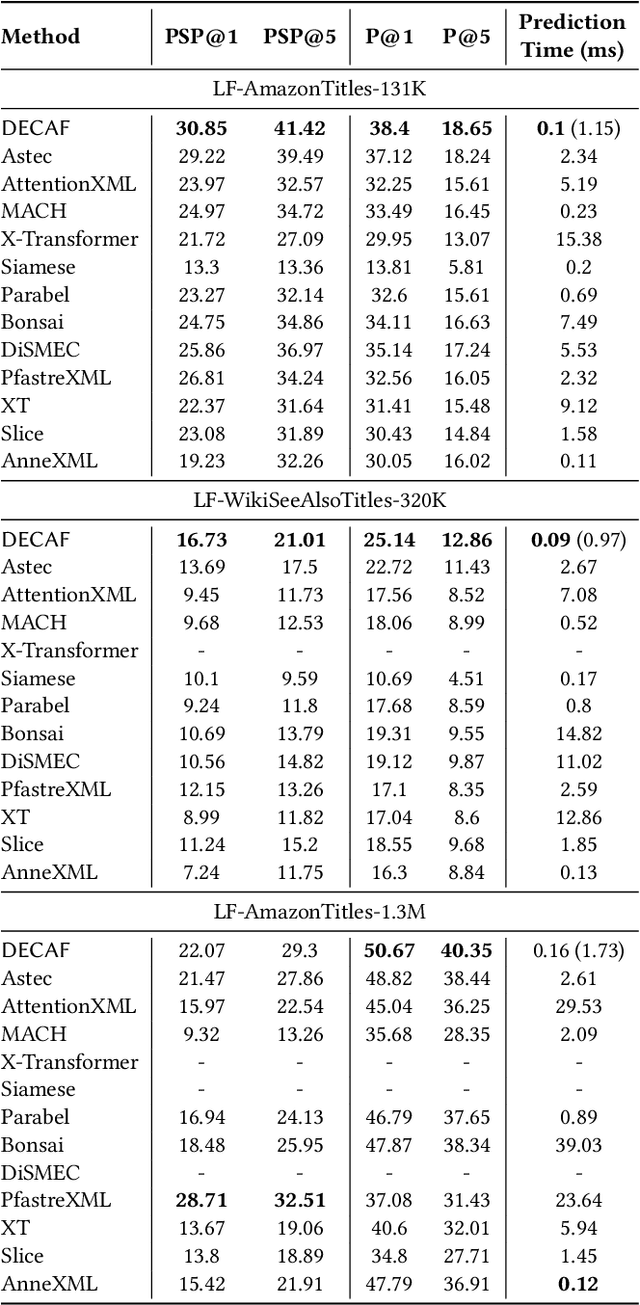
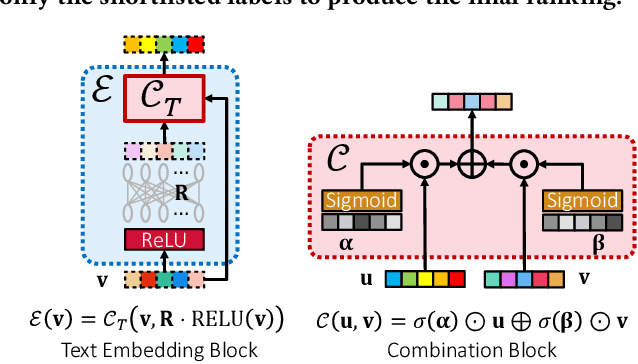
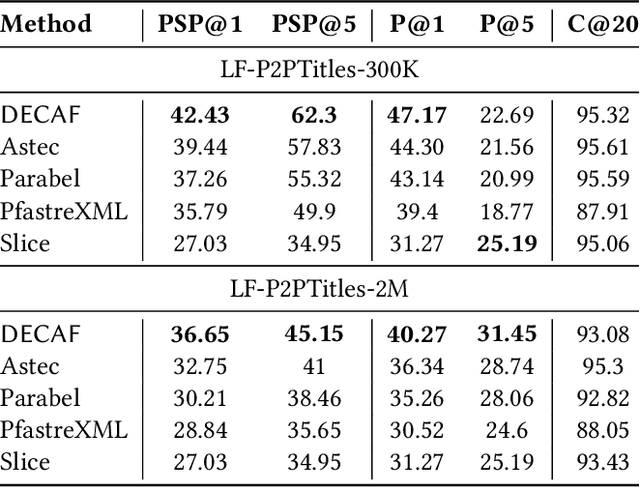
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.
ECLARE: Extreme Classification with Label Graph Correlations
Jul 31, 2021
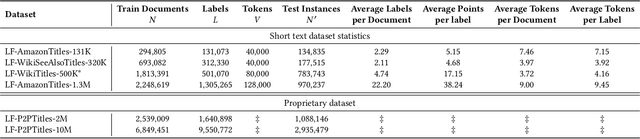
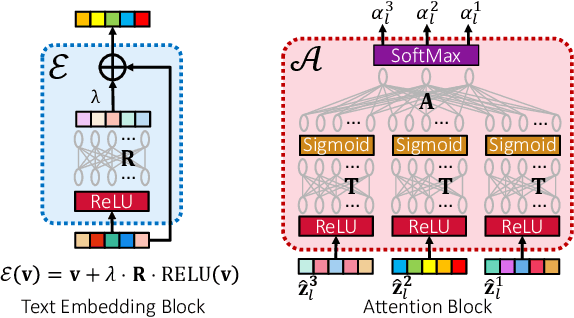
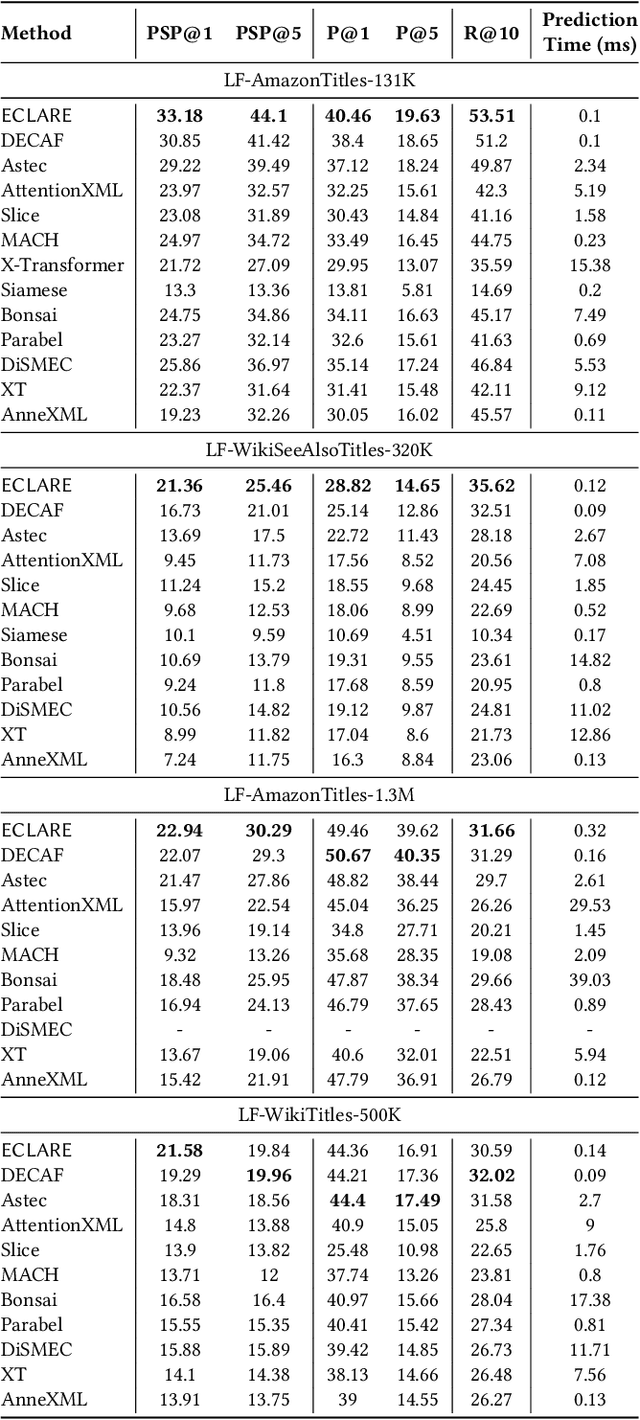
Deep extreme classification (XC) seeks to train deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. The core utility of XC comes from predicting labels that are rarely seen during training. Such rare labels hold the key to personalized recommendations that can delight and surprise a user. However, the large number of rare labels and small amount of training data per rare label offer significant statistical and computational challenges. State-of-the-art deep XC methods attempt to remedy this by incorporating textual descriptions of labels but do not adequately address the problem. This paper presents ECLARE, a scalable deep learning architecture that incorporates not only label text, but also label correlations, to offer accurate real-time predictions within a few milliseconds. Core contributions of ECLARE include a frugal architecture and scalable techniques to train deep models along with label correlation graphs at the scale of millions of labels. In particular, ECLARE offers predictions that are 2 to 14% more accurate on both publicly available benchmark datasets as well as proprietary datasets for a related products recommendation task sourced from the Bing search engine. Code for ECLARE is available at https://github.com/Extreme-classification/ECLARE.
Globally-convergent Iteratively Reweighted Least Squares for Robust Regression Problems
Jun 25, 2020
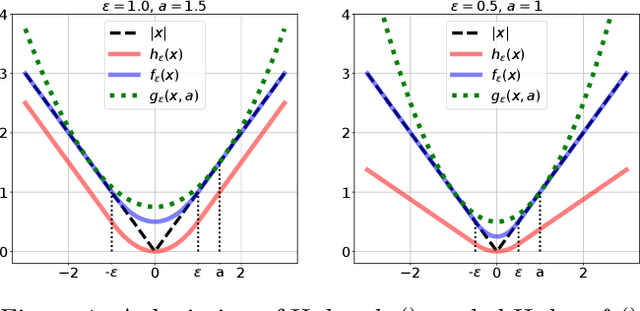
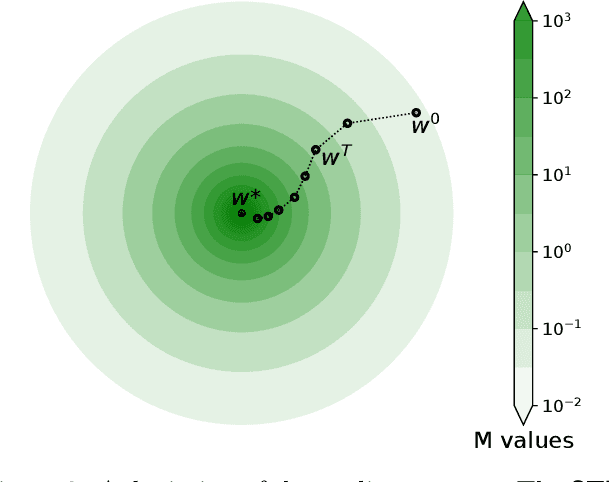

We provide the first global model recovery results for the IRLS (iteratively reweighted least squares) heuristic for robust regression problems. IRLS is known to offer excellent performance, despite bad initializations and data corruption, for several parameter estimation problems. Existing analyses of IRLS frequently require careful initialization, thus offering only local convergence guarantees. We remedy this by proposing augmentations to the basic IRLS routine that not only offer guaranteed global recovery, but in practice also outperform state-of-the-art algorithms for robust regression. Our routines are more immune to hyperparameter misspecification in basic regression tasks, as well as applied tasks such as linear-armed bandit problems. Our theoretical analyses rely on a novel extension of the notions of strong convexity and smoothness to weighted strong convexity and smoothness, and establishing that sub-Gaussian designs offer bounded weighted condition numbers. These notions may be useful in analyzing other algorithms as well.
* 30 pages, 5 figures, appeared as a publication in the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), 2019