 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Advertisement Creative Generation
Mar 14, 2026Lifestyle images are photographs that capture environments and objects in everyday settings. In furniture product marketing, advertisers often create lifestyle images containing products to resonate with potential buyers, allowing buyers to visualize how the products fit into their daily lives. While recent advances in Generative Artificial Intelligence (GenAI) have given rise to realistic image content creation, their application in e-commerce advertising is challenging because high-quality ads must authentically representing the products in realistic scearios. Therefore, manual intervention is usually required for individual generations, making it difficult to scale to larger product catalogs. To understand the challenges faced by advertisers using GenAI to create lifestyle images at scale, we conducted evaluations on ad images generated using state-of-the-art image generation models and identified the major challenges. Based on our findings, we present CreativeAds, a multi-product ad creation system that supports scalable automated generation with customized parameter adjustment for individual generation. To ensure automated high-quality ad generation, CreativeAds innovates a pipeline that consists of three modules to address challenges in product pairing, layout generation, and background generation separately. Furthermore, CreativeAds contains an intuitive user interface to allow users to oversee generation at scale, and it also supports detailed controls on individual generation for user customized adjustments. We performed a user study on CreativeAds and extensive evaluations of the generated images, demonstrating CreativeAds's ability to create large number of high-quality images at scale for advertisers without requiring expertise in GenAI tools.
AutoTask: Task Aware Multi-Faceted Single Model for Multi-Task Ads Relevance
Jul 09, 2024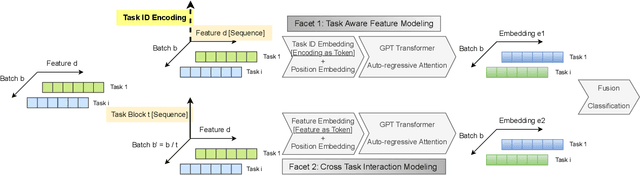


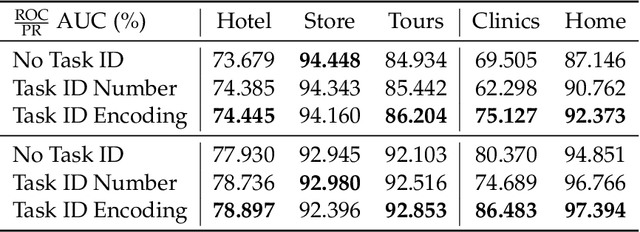
Ads relevance models are crucial in determining the relevance between user search queries and ad offers, often framed as a classification problem. The complexity of modeling increases significantly with multiple ad types and varying scenarios that exhibit both similarities and differences. In this work, we introduce a novel multi-faceted attention model that performs task aware feature combination and cross task interaction modeling. Our technique formulates the feature combination problem as "language" modeling with auto-regressive attentions across both feature and task dimensions. Specifically, we introduce a new dimension of task ID encoding for task representations, thereby enabling precise relevance modeling across diverse ad scenarios with substantial improvement in generality capability for unseen tasks. We demonstrate that our model not only effectively handles the increased computational and maintenance demands as scenarios proliferate, but also outperforms generalized DNN models and even task-specific models across a spectrum of ad applications using a single unified model.
LoPT: Low-Rank Prompt Tuning for Parameter Efficient Language Models
Jun 27, 2024In prompt tuning, a prefix or suffix text is added to the prompt, and the embeddings (soft prompts) or token indices (hard prompts) of the prefix/suffix are optimized to gain more control over language models for specific tasks. This approach eliminates the need for hand-crafted prompt engineering or explicit model fine-tuning. Prompt tuning is significantly more parameter-efficient than model fine-tuning, as it involves optimizing partial inputs of language models to produce desired outputs. In this work, we aim to further reduce the amount of trainable parameters required for a language model to perform well on specific tasks. We propose Low-rank Prompt Tuning (LoPT), a low-rank model for prompts that achieves efficient prompt optimization. The proposed method demonstrates similar outcomes to full parameter prompt tuning while reducing the number of trainable parameters by a factor of 5. It also provides promising results compared to the state-of-the-art methods that would require 10 to 20 times more parameters.
Multi-modal Extreme Classification
Sep 10, 2023This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
DeepProbe: Information Directed Sequence Understanding and Chatbot Design via Recurrent Neural Networks
Mar 01, 2018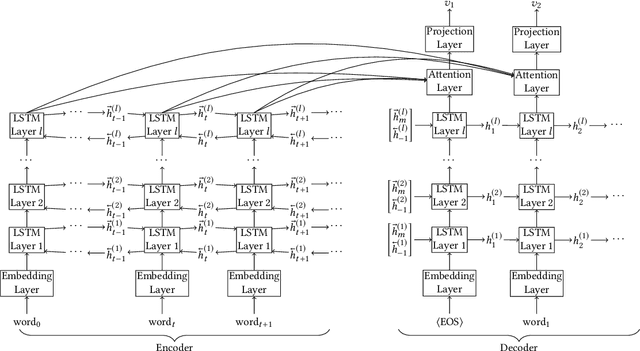

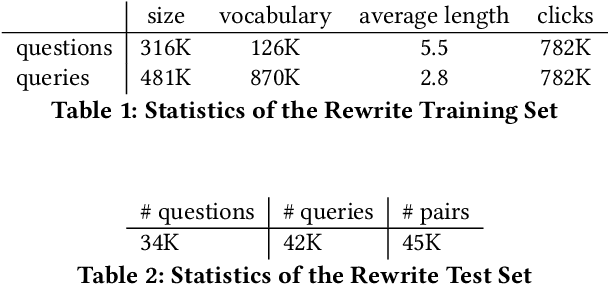
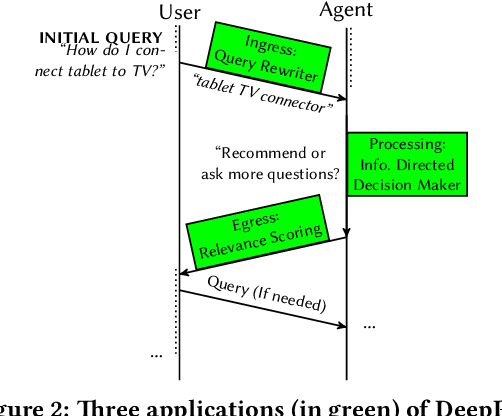
Information extraction and user intention identification are central topics in modern query understanding and recommendation systems. In this paper, we propose DeepProbe, a generic information-directed interaction framework which is built around an attention-based sequence to sequence (seq2seq) recurrent neural network. DeepProbe can rephrase, evaluate, and even actively ask questions, leveraging the generative ability and likelihood estimation made possible by seq2seq models. DeepProbe makes decisions based on a derived uncertainty (entropy) measure conditioned on user inputs, possibly with multiple rounds of interactions. Three applications, namely a rewritter, a relevance scorer and a chatbot for ad recommendation, were built around DeepProbe, with the first two serving as precursory building blocks for the third. We first use the seq2seq model in DeepProbe to rewrite a user query into one of standard query form, which is submitted to an ordinary recommendation system. Secondly, we evaluate DeepProbe's seq2seq model-based relevance scoring. Finally, we build a chatbot prototype capable of making active user interactions, which can ask questions that maximize information gain, allowing for a more efficient user intention idenfication process. We evaluate first two applications by 1) comparing with baselines by BLEU and AUC, and 2) human judge evaluation. Both demonstrate significant improvements compared with current state-of-the-art systems, proving their values as useful tools on their own, and at the same time laying a good foundation for the ongoing chatbot application.