 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Meet Extreme Multi-label Classification: Scaling and Multi-modal Framework
Nov 17, 2025Foundation models have revolutionized artificial intelligence across numerous domains, yet their transformative potential remains largely untapped in Extreme Multi-label Classification (XMC). Queries in XMC are associated with relevant labels from extremely large label spaces, where it is critical to strike a balance between efficiency and performance. Therefore, many recent approaches efficiently pose XMC as a maximum inner product search between embeddings learned from small encoder-only transformer architectures. In this paper, we address two important aspects in XMC: how to effectively harness larger decoder-only models, and how to exploit visual information while maintaining computational efficiency. We demonstrate that both play a critical role in XMC separately and can be combined for improved performance. We show that a few billion-size decoder can deliver substantial improvements while keeping computational overhead manageable. Furthermore, our Vision-enhanced eXtreme Multi-label Learning framework (ViXML) efficiently integrates foundation vision models by pooling a single embedding per image. This limits computational growth while unlocking multi-modal capabilities. Remarkably, ViXML with small encoders outperforms text-only decoder in most cases, showing that an image is worth billions of parameters. Finally, we present an extension of existing text-only datasets to exploit visual metadata and make them available for future benchmarking. Comprehensive experiments across four public text-only datasets and their corresponding image enhanced versions validate our proposals' effectiveness, surpassing previous state-of-the-art by up to +8.21\% in P@1 on the largest dataset. ViXML's code is available at https://github.com/DiegoOrtego/vixml.
Prototypical Extreme Multi-label Classification with a Dynamic Margin Loss
Oct 27, 2024



Extreme Multi-label Classification (XMC) methods predict relevant labels for a given query in an extremely large label space. Recent works in XMC address this problem using deep encoders that project text descriptions to an embedding space suitable for recovering the closest labels. However, learning deep models can be computationally expensive in large output spaces, resulting in a trade-off between high performing brute-force approaches and efficient solutions. In this paper, we propose PRIME, a XMC method that employs a novel prototypical contrastive learning technique to reconcile efficiency and performance surpassing brute-force approaches. We frame XMC as a data-to-prototype prediction task where label prototypes aggregate information from related queries. More precisely, we use a shallow transformer encoder that we coin as Label Prototype Network, which enriches label representations by aggregating text-based embeddings, label centroids and learnable free vectors. We jointly train a deep encoder and the Label Prototype Network using an adaptive triplet loss objective that better adapts to the high granularity and ambiguity of extreme label spaces. PRIME achieves state-of-the-art results in several public benchmarks of different sizes and domains, while keeping the model efficient.
Multi-modal Extreme Classification
Sep 10, 2023This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
Are You Comfortable Now: Deep Learning the Temporal Variation in Thermal Comfort in Winters
Aug 20, 2022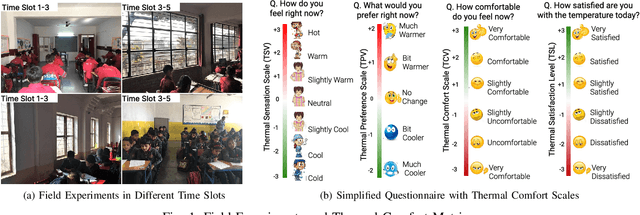

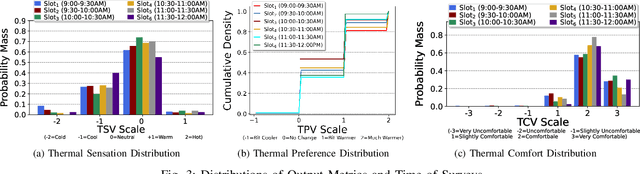
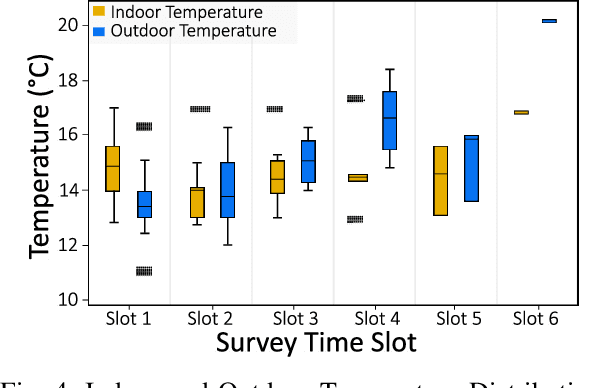
Indoor thermal comfort in smart buildings has a significant impact on the health and performance of occupants. Consequently, machine learning (ML) is increasingly used to solve challenges related to indoor thermal comfort. Temporal variability of thermal comfort perception is an important problem that regulates occupant well-being and energy consumption. However, in most ML-based thermal comfort studies, temporal aspects such as the time of day, circadian rhythm, and outdoor temperature are not considered. This work addresses these problems. It investigates the impact of circadian rhythm and outdoor temperature on the prediction accuracy and classification performance of ML models. The data is gathered through month-long field experiments carried out in 14 classrooms of 5 schools, involving 512 primary school students. Four thermal comfort metrics are considered as the outputs of Deep Neural Networks and Support Vector Machine models for the dataset. The effect of temporal variability on school children's comfort is shown through a "time of day" analysis. Temporal variability in prediction accuracy is demonstrated (up to 80%). Furthermore, we show that outdoor temperature (varying over time) positively impacts the prediction performance of thermal comfort models by up to 30%. The importance of spatio-temporal context is demonstrated by contrasting micro-level (location specific) and macro-level (6 locations across a city) performance. The most important finding of this work is that a definitive improvement in prediction accuracy is shown with an increase in the time of day and sky illuminance, for multiple thermal comfort metrics.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022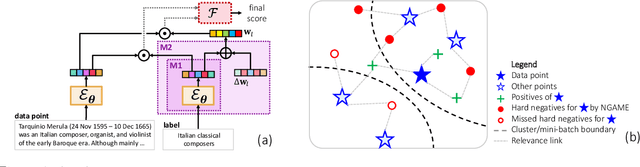
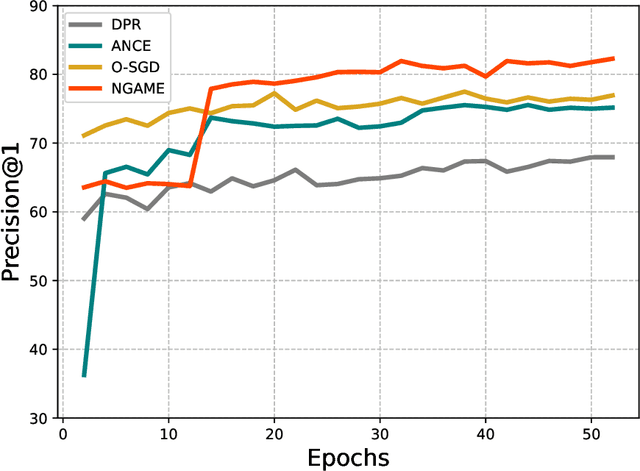
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Building Matters: Spatial Variability in Machine Learning Based Thermal Comfort Prediction in Winters
Jun 28, 2022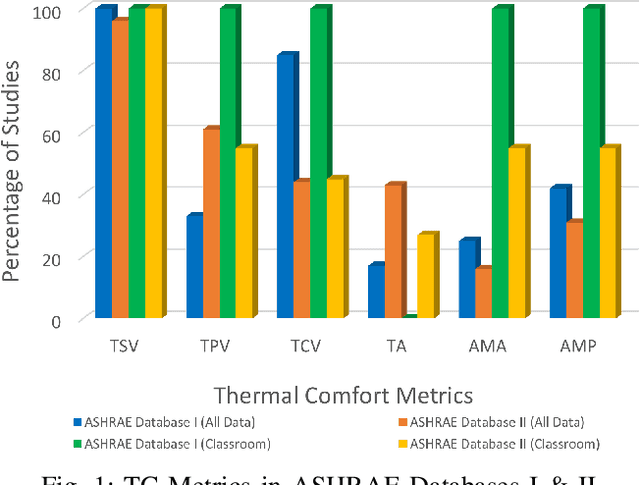
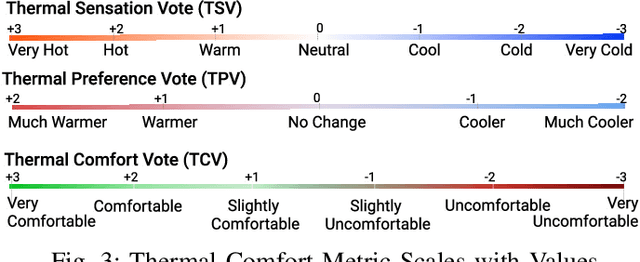
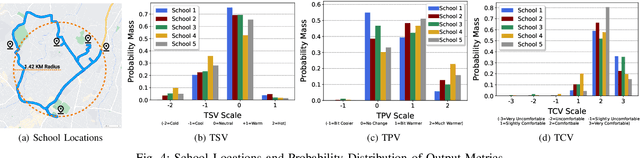
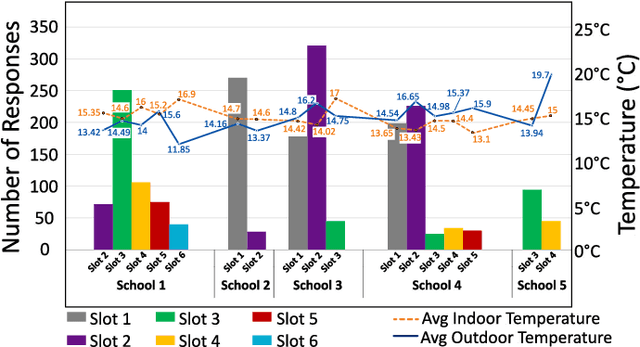
Thermal comfort in indoor environments has an enormous impact on the health, well-being, and performance of occupants. Given the focus on energy efficiency and Internet-of-Things enabled smart buildings, machine learning (ML) is being increasingly used for data-driven thermal comfort (TC) prediction. Generally, ML-based solutions are proposed for air-conditioned or HVAC ventilated buildings and the models are primarily designed for adults. On the other hand, naturally ventilated (NV) buildings are the norm in most countries. They are also ideal for energy conservation and long-term sustainability goals. However, the indoor environment of NV buildings lacks thermal regulation and varies significantly across spatial contexts. These factors make TC prediction extremely challenging. Thus, determining the impact of the building environment on the performance of TC models is important. Further, the generalization capability of TC prediction models across different NV indoor spaces needs to be studied. This work addresses these problems. Data is gathered through month-long field experiments conducted in 5 naturally ventilated school buildings, involving 512 primary school students. The impact of spatial variability on student comfort is demonstrated through variation in prediction accuracy (by as much as 71%). The influence of building environment on TC prediction is also demonstrated through variation in feature importance. Further, a comparative analysis of spatial variability in model performance is done for children (our dataset) and adults (ASHRAE-II database). Finally, the generalization capability of thermal comfort models in NV classrooms is assessed and major challenges are highlighted.
Optimizing Unlicensed Coexistence Network Performance Through Data Learning
Nov 15, 2021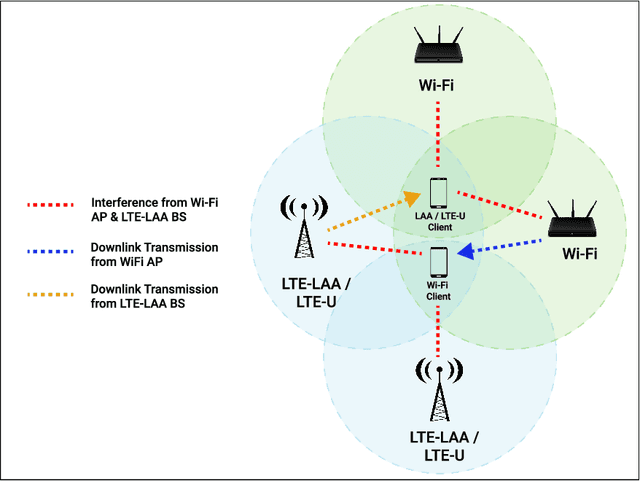
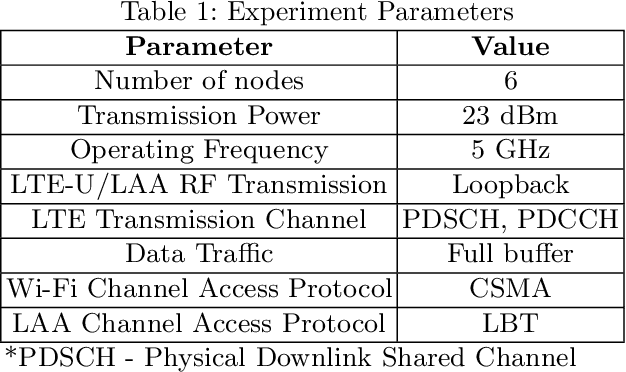
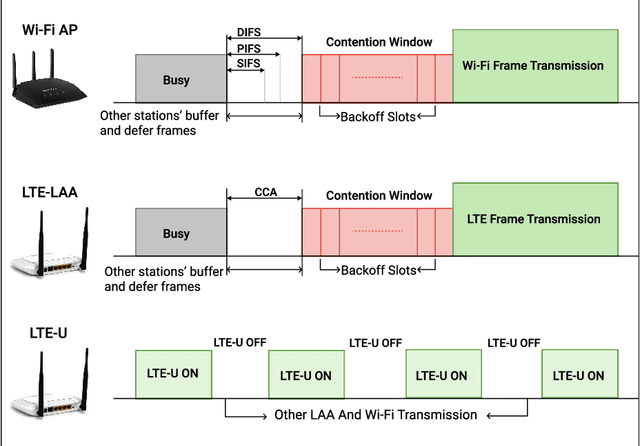
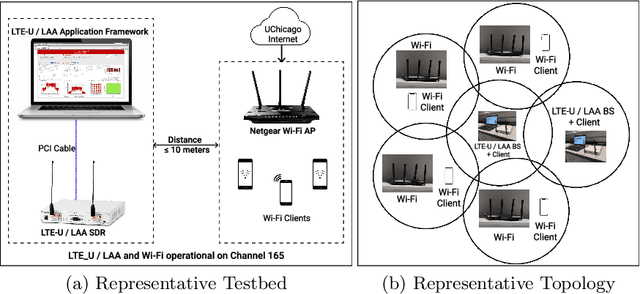
Unlicensed LTE-WiFi coexistence networks are undergoing consistent densification to meet the rising mobile data demands. With the increase in coexistence network complexity, it is important to study network feature relationships (NFRs) and utilize them to optimize dense coexistence network performance. This work studies NFRs in unlicensed LTE-WiFi (LTE-U and LTE-LAA) networks through supervised learning of network data collected from real-world experiments. Different 802.11 standards and varying channel bandwidths are considered in the experiments and the learning model selection policy is precisely outlined. Thereafter, a comparative analysis of different LTE-WiFi network configurations is performed through learning model parameters such as R-sq, residual error, outliers, choice of predictor, etc. Further, a Network Feature Relationship based Optimization (NeFRO) framework is proposed. NeFRO improves upon the conventional optimization formulations by utilizing the feature-relationship equations learned from network data. It is demonstrated to be highly suitable for time-critical dense coexistence networks through two optimization objectives, viz., network capacity and signal strength. NeFRO is validated against four recent works on network optimization. NeFRO is successfully able to reduce optimization convergence time by as much as 24% while maintaining accuracy as high as 97.16%, on average.
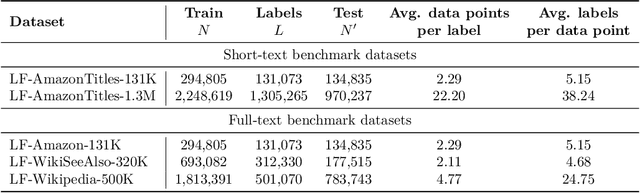
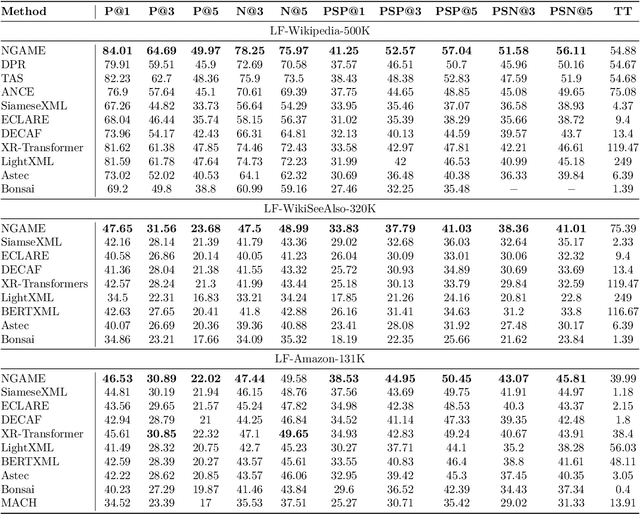
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021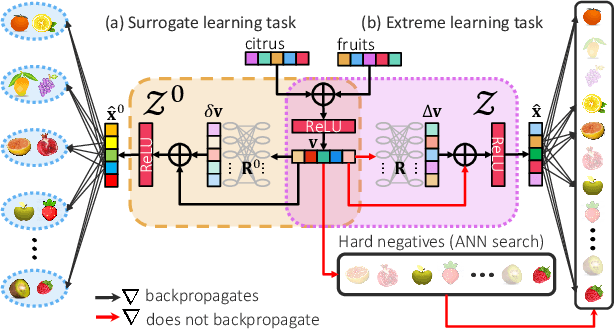
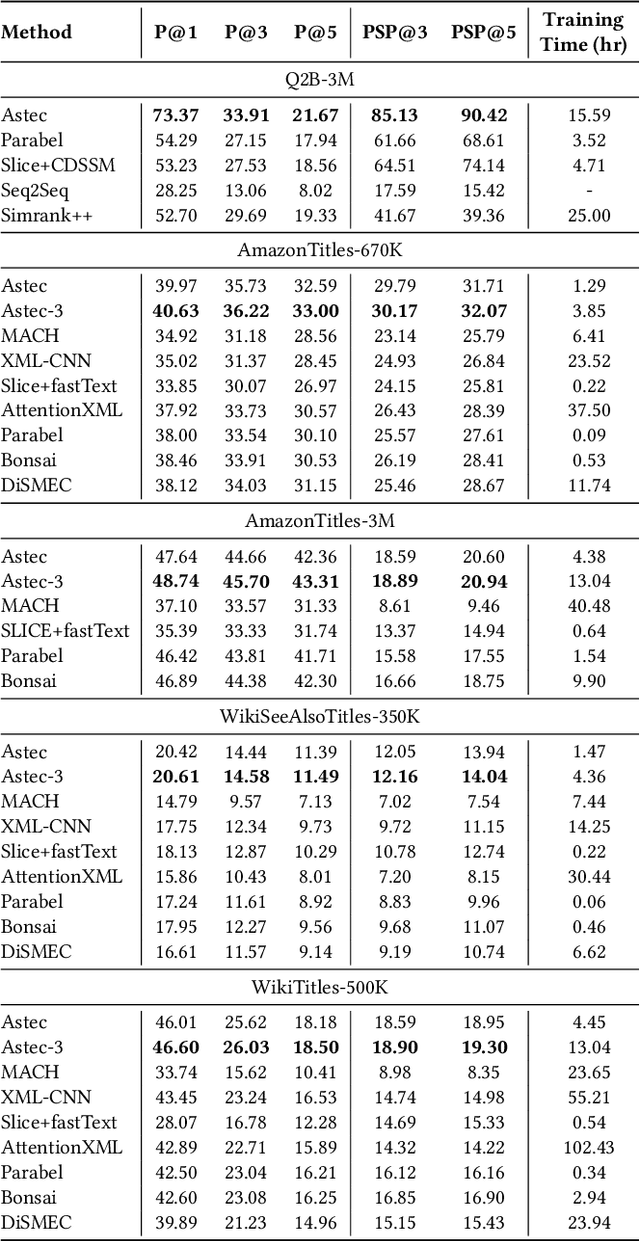

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
DECAF: Deep Extreme Classification with Label Features
Aug 01, 2021
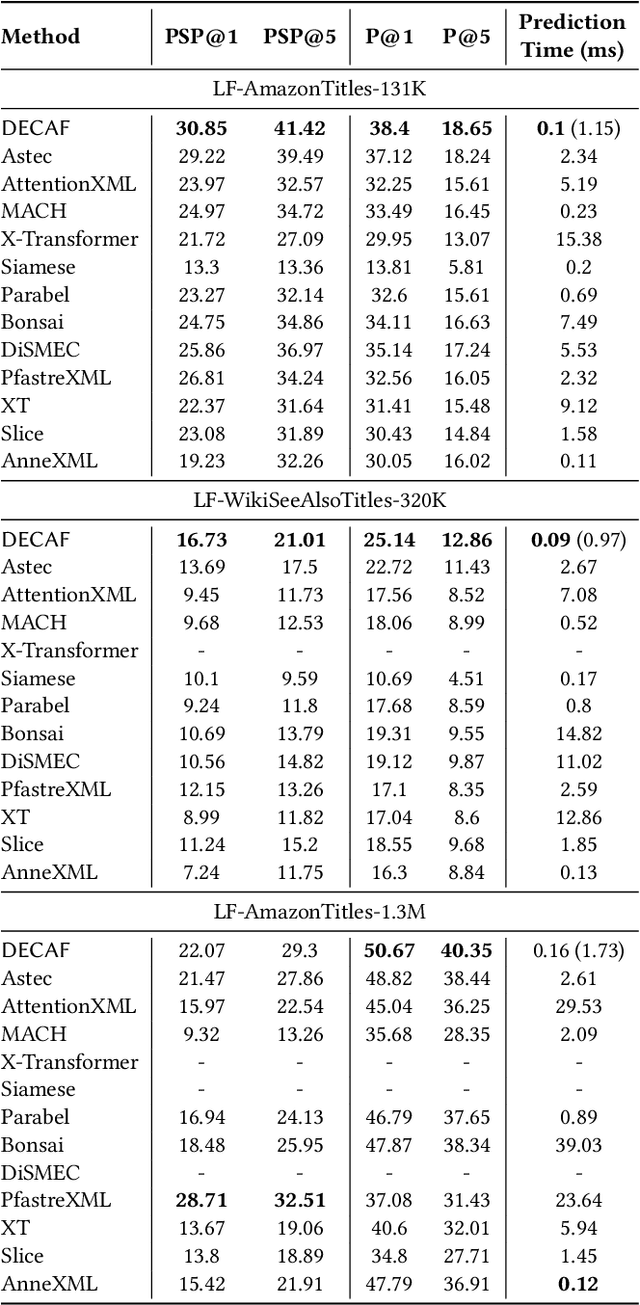
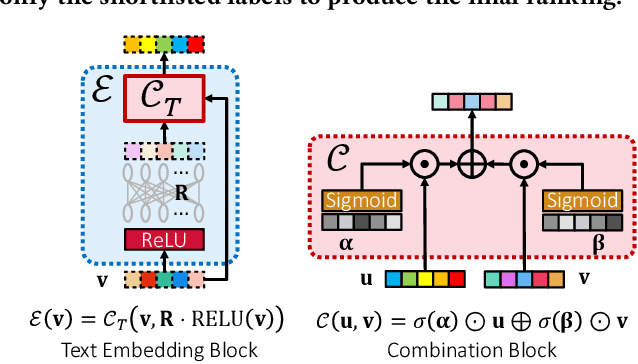
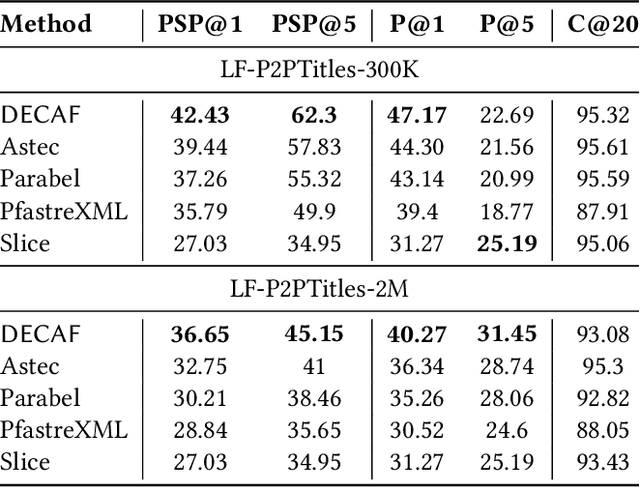
Extreme multi-label classification (XML) involves tagging a data point with its most relevant subset of labels from an extremely large label set, with several applications such as product-to-product recommendation with millions of products. Although leading XML algorithms scale to millions of labels, they largely ignore label meta-data such as textual descriptions of the labels. On the other hand, classical techniques that can utilize label metadata via representation learning using deep networks struggle in extreme settings. This paper develops the DECAF algorithm that addresses these challenges by learning models enriched by label metadata that jointly learn model parameters and feature representations using deep networks and offer accurate classification at the scale of millions of labels. DECAF makes specific contributions to model architecture design, initialization, and training, enabling it to offer up to 2-6% more accurate prediction than leading extreme classifiers on publicly available benchmark product-to-product recommendation datasets, such as LF-AmazonTitles-1.3M. At the same time, DECAF was found to be up to 22x faster at inference than leading deep extreme classifiers, which makes it suitable for real-time applications that require predictions within a few milliseconds. The code for DECAF is available at the following URL https://github.com/Extreme-classification/DECAF.