 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Asymptotically Unbiased Constrained Decoding for Large Language Models
Apr 12, 2025In real-world applications of large language models, outputs are often required to be confined: selecting items from predefined product or document sets, generating phrases that comply with safety standards, or conforming to specialized formatting styles. To control the generation, constrained decoding has been widely adopted. However, existing prefix-tree-based constrained decoding is inefficient under GPU-based model inference paradigms, and it introduces unintended biases into the output distribution. This paper introduces Dynamic Importance Sampling for Constrained Decoding (DISC) with GPU-based Parallel Prefix-Verification (PPV), a novel algorithm that leverages dynamic importance sampling to achieve theoretically guaranteed asymptotic unbiasedness and overcomes the inefficiency of prefix-tree. Extensive experiments demonstrate the superiority of our method over existing methods in both efficiency and output quality. These results highlight the potential of our methods to improve constrained generation in applications where adherence to specific constraints is essential.
Improving hp-Variational Physics-Informed Neural Networks for Steady-State Convection-Dominated Problems
Nov 14, 2024



This paper proposes and studies two extensions of applying hp-variational physics-informed neural networks, more precisely the FastVPINNs framework, to convection-dominated convection-diffusion-reaction problems. First, a term in the spirit of a SUPG stabilization is included in the loss functional and a network architecture is proposed that predicts spatially varying stabilization parameters. Having observed that the selection of the indicator function in hard-constrained Dirichlet boundary conditions has a big impact on the accuracy of the computed solutions, the second novelty is the proposal of a network architecture that learns good parameters for a class of indicator functions. Numerical studies show that both proposals lead to noticeably more accurate results than approaches that can be found in the literature.
Efficient Document Ranking with Learnable Late Interactions
Jun 25, 2024



Cross-Encoder (CE) and Dual-Encoder (DE) models are two fundamental approaches for query-document relevance in information retrieval. To predict relevance, CE models use joint query-document embeddings, while DE models maintain factorized query and document embeddings; usually, the former has higher quality while the latter benefits from lower latency. Recently, late-interaction models have been proposed to realize more favorable latency-quality tradeoffs, by using a DE structure followed by a lightweight scorer based on query and document token embeddings. However, these lightweight scorers are often hand-crafted, and there is no understanding of their approximation power; further, such scorers require access to individual document token embeddings, which imposes an increased latency and storage burden. In this paper, we propose novel learnable late-interaction models (LITE) that resolve these issues. Theoretically, we prove that LITE is a universal approximator of continuous scoring functions, even for relatively small embedding dimension. Empirically, LITE outperforms previous late-interaction models such as ColBERT on both in-domain and zero-shot re-ranking tasks. For instance, experiments on MS MARCO passage re-ranking show that LITE not only yields a model with better generalization, but also lowers latency and requires 0.25x storage compared to ColBERT.
FastVPINNs: Tensor-Driven Acceleration of VPINNs for Complex Geometries
Apr 18, 2024
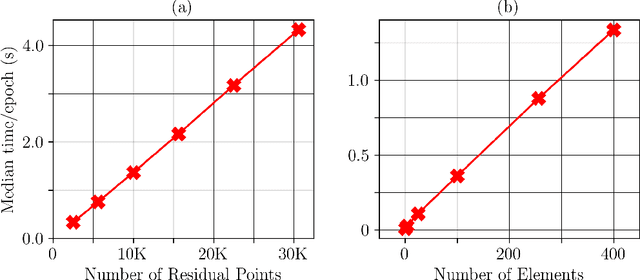
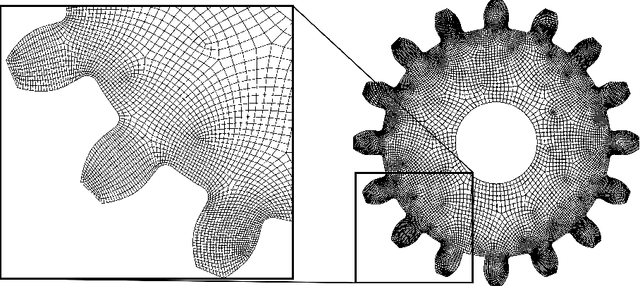

Variational Physics-Informed Neural Networks (VPINNs) utilize a variational loss function to solve partial differential equations, mirroring Finite Element Analysis techniques. Traditional hp-VPINNs, while effective for high-frequency problems, are computationally intensive and scale poorly with increasing element counts, limiting their use in complex geometries. This work introduces FastVPINNs, a tensor-based advancement that significantly reduces computational overhead and improves scalability. Using optimized tensor operations, FastVPINNs achieve a 100-fold reduction in the median training time per epoch compared to traditional hp-VPINNs. With proper choice of hyperparameters, FastVPINNs surpass conventional PINNs in both speed and accuracy, especially in problems with high-frequency solutions. Demonstrated effectiveness in solving inverse problems on complex domains underscores FastVPINNs' potential for widespread application in scientific and engineering challenges, opening new avenues for practical implementations in scientific machine learning.
SpecTr: Fast Speculative Decoding via Optimal Transport
Oct 23, 2023



Autoregressive sampling from large language models has led to state-of-the-art results in several natural language tasks. However, autoregressive sampling generates tokens one at a time making it slow, and even prohibitive in certain tasks. One way to speed up sampling is $\textit{speculative decoding}$: use a small model to sample a $\textit{draft}$ (block or sequence of tokens), and then score all tokens in the draft by the large language model in parallel. A subset of the tokens in the draft are accepted (and the rest rejected) based on a statistical method to guarantee that the final output follows the distribution of the large model. In this work, we provide a principled understanding of speculative decoding through the lens of optimal transport (OT) with $\textit{membership cost}$. This framework can be viewed as an extension of the well-known $\textit{maximal-coupling}$ problem. This new formulation enables us to generalize the speculative decoding method to allow for a set of $k$ candidates at the token-level, which leads to an improved optimal membership cost. We show that the optimal draft selection algorithm (transport plan) can be computed via linear programming, whose best-known runtime is exponential in $k$. We then propose a valid draft selection algorithm whose acceptance probability is $(1-1/e)$-optimal multiplicatively. Moreover, it can be computed in time almost linear with size of domain of a single token. Using this $new draft selection$ algorithm, we develop a new autoregressive sampling algorithm called $\textit{SpecTr}$, which provides speedup in decoding while ensuring that there is no quality degradation in the decoded output. We experimentally demonstrate that for state-of-the-art large language models, the proposed approach achieves a wall clock speedup of 2.13X, a further 1.37X speedup over speculative decoding on standard benchmarks.
Treeformer: Dense Gradient Trees for Efficient Attention Computation
Aug 18, 2022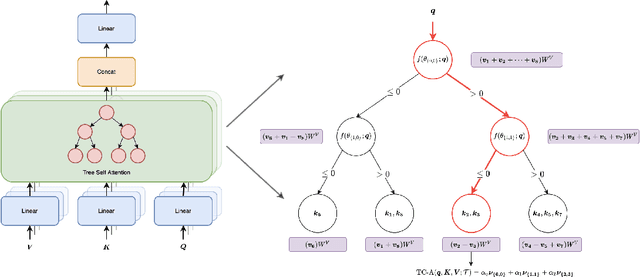
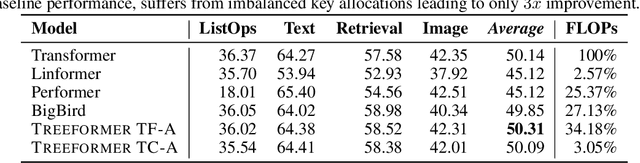
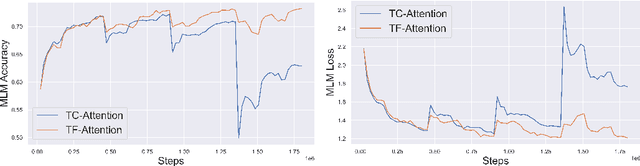
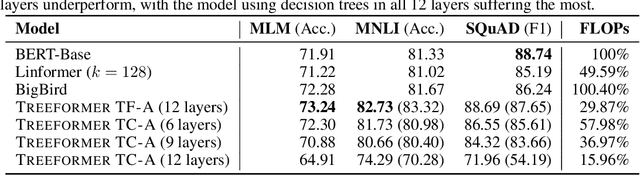
Standard inference and training with transformer based architectures scale quadratically with input sequence length. This is prohibitively large for a variety of applications especially in web-page translation, query-answering etc. Consequently, several approaches have been developed recently to speedup attention computation by enforcing different attention structures such as sparsity, low-rank, approximating attention using kernels. In this work, we view attention computation as that of nearest neighbor retrieval, and use decision tree based hierarchical navigation to reduce the retrieval cost per query token from linear in sequence length to nearly logarithmic. Based on such hierarchical navigation, we design Treeformer which can use one of two efficient attention layers -- TF-Attention and TC-Attention. TF-Attention computes the attention in a fine-grained style, while TC-Attention is a coarse attention layer which also ensures that the gradients are "dense". To optimize such challenging discrete layers, we propose a two-level bootstrapped training method. Using extensive experiments on standard NLP benchmarks, especially for long-sequences, we demonstrate that our Treeformer architecture can be almost as accurate as baseline Transformer while using 30x lesser FLOPs in the attention layer. Compared to Linformer, the accuracy can be as much as 12% higher while using similar FLOPs in the attention layer.
Teacher Guided Training: An Efficient Framework for Knowledge Transfer
Aug 14, 2022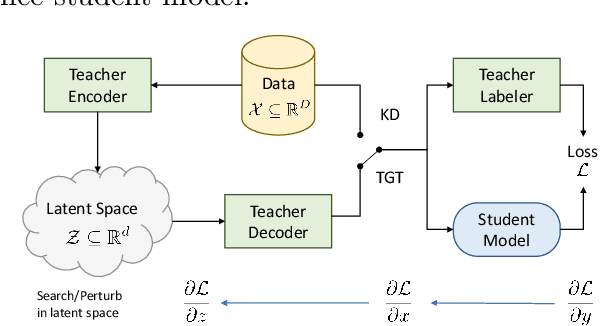
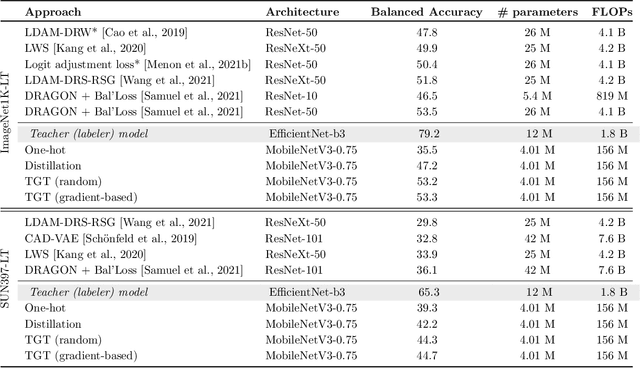
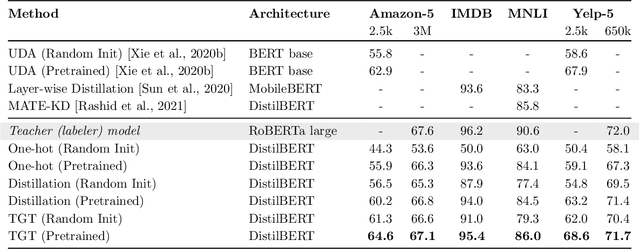
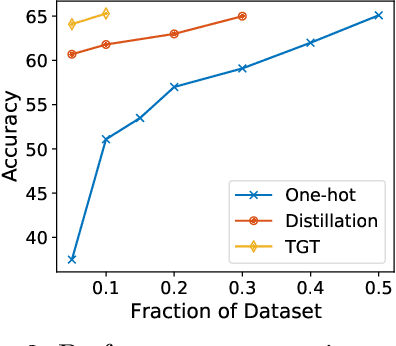
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
Nov 12, 2021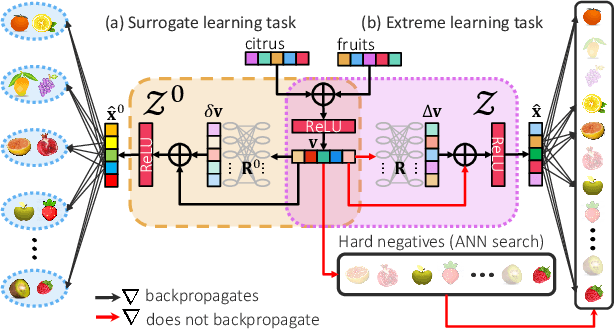
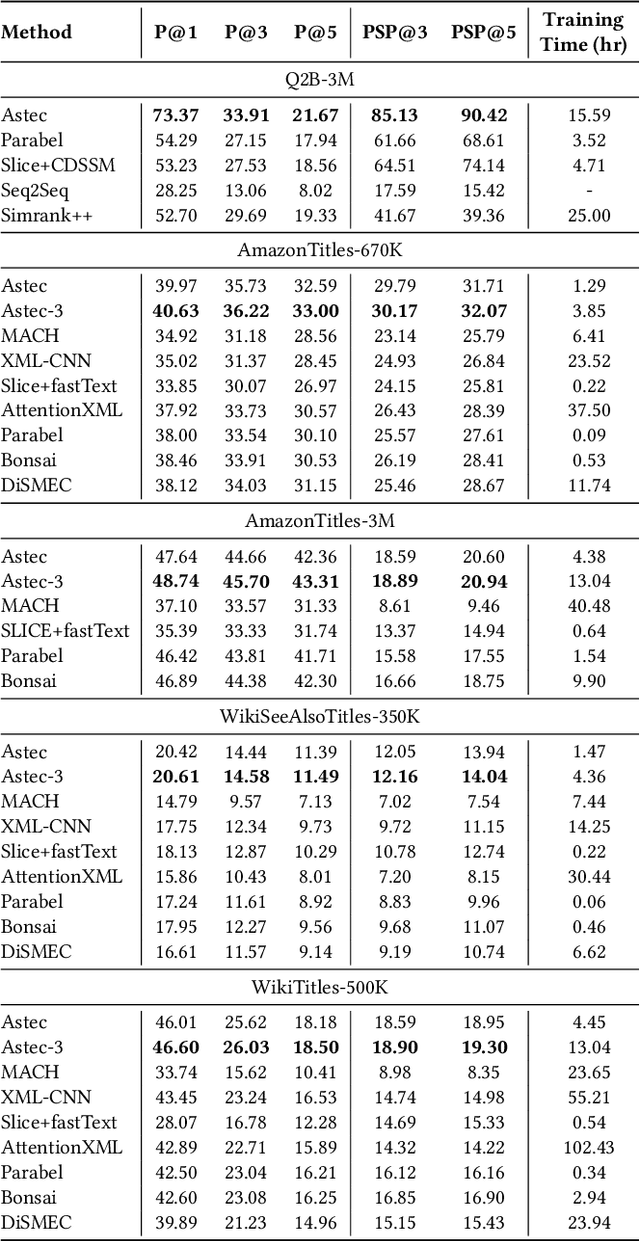

Scalability and accuracy are well recognized challenges in deep extreme multi-label learning where the objective is to train architectures for automatically annotating a data point with the most relevant subset of labels from an extremely large label set. This paper develops the DeepXML framework that addresses these challenges by decomposing the deep extreme multi-label task into four simpler sub-tasks each of which can be trained accurately and efficiently. Choosing different components for the four sub-tasks allows DeepXML to generate a family of algorithms with varying trade-offs between accuracy and scalability. In particular, DeepXML yields the Astec algorithm that could be 2-12% more accurate and 5-30x faster to train than leading deep extreme classifiers on publically available short text datasets. Astec could also efficiently train on Bing short text datasets containing up to 62 million labels while making predictions for billions of users and data points per day on commodity hardware. This allowed Astec to be deployed on the Bing search engine for a number of short text applications ranging from matching user queries to advertiser bid phrases to showing personalized ads where it yielded significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. DeepXML's code is available at https://github.com/Extreme-classification/deepxml
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021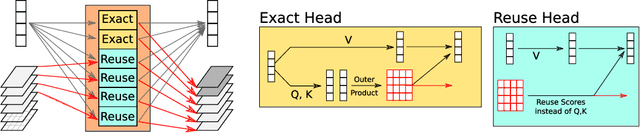
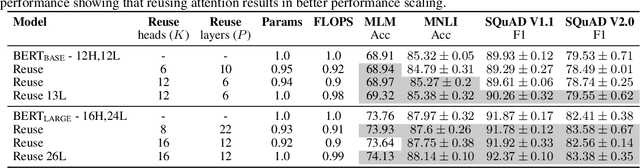
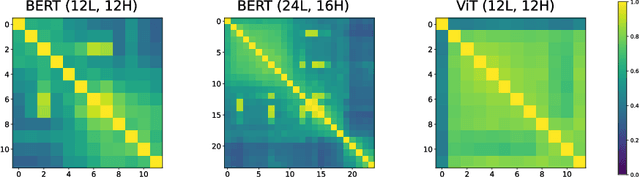
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021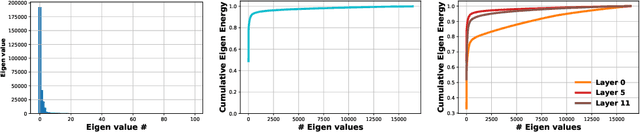
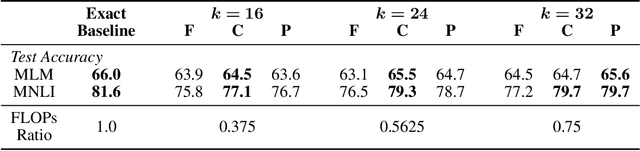
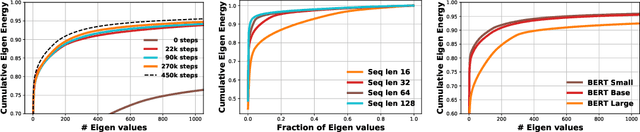
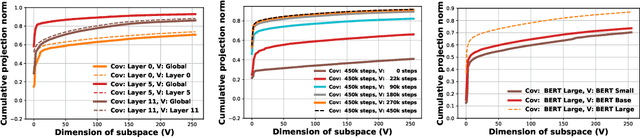
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.